gpt neox
GPT-NeoX 2.0
該儲存庫記錄了 EleutherAI 用於在 GPU 上訓練大規模語言模型的庫。我們目前的框架基於 NVIDIA 的 Megatron 語言模型,並透過 DeepSpeed 的技術以及一些新穎的最佳化進行了增強。我們的目標是使這個儲存庫成為一個集中且可訪問的地方,以收集訓練大規模自回歸語言模型的技術,並加速對大規模訓練的研究。該庫在學術、工業和政府實驗室中廣泛使用,包括橡樹嶺國家實驗室、CarperAI、Stability AI、Together.ai、韓國大學、卡內基美隆大學和東京大學等機構的研究人員。在類似的庫中,GPT-NeoX 是獨一無二的,它支援多種系統和硬件,包括透過 Slurm、MPI 和 IBM Job Step Manager 啟動,並且已在 AWS、CoreWeave、ORNL Summit、ORNL Frontier、LUMI 和其他的。
如果您不想從頭開始訓練具有數十億參數的模型,那麼這可能是錯誤的庫。對於一般推理需求,我們建議您使用支援 GPT-NeoX 模型的 Hugging Face transformers庫。
GPT-NeoX 利用了許多與流行的 Megatron-DeepSpeed 庫相同的功能和技術,但大幅提高了可用性和新穎的優化。主要特點包括:
[9/9/2024]我們現在支持透過 DPO、KTO 和獎勵建模進行偏好學習
[9/9/2024]我們現在支援與機器學習監控平台 Comet ML 集成
[5/21/2024]我們現在支援具有管道並行性的 RWKV!請參閱 RWKV 和 RWKV+pipeline 的 PR
[3/21/2024]我們現在支援混合專家 (MoE)
[3/17/2024]我們現在支援 AMD MI250X GPU
[3/15/2024]我們現在支援 Mamba 張量並行!查看公關
[8/10/2023]我們現在支援 AWS S3 的檢查點!使用s3_path配置選項啟動(有關更多詳細信息,請參閱 PR)
[9/20/2023]自 #1035 起,我們已棄用 Flash Attention 0.x 和 1.x,並將支援遷移到 Flash Attention 2.x。我們認為這不會導致問題,但如果您有特定的用例需要使用最新的 GPT-NeoX 來支援舊閃存,請提出問題。
[8/10/2023]我們的 math-lm 專案對 LLaMA 2 和 Flash Attention v2 提供了實驗性支持,該專案將於本月晚些時候上傳到上游。
[5/17/2023]修復了一些其他錯誤後,我們現在完全支援 bf16。
[4/11/2023]我們升級了 Flash Attention 實現,現在支援 Alibi 位置嵌入。
[3/9/2023]我們發布了 GPT-NeoX 2.0.0,這是基於最新 DeepSpeed 構建的升級版本,並將定期同步。
在 2023 年 3 月 9 日之前,GPT-NeoX 依賴 DeeperSpeed,它是基於舊版的 DeepSpeed (0.3.15)。為了遷移到最新的上游 DeepSpeed 版本,同時允許用戶存取舊版的 GPT-NeoX 和 DeeperSpeed,我們為這兩個函式庫引入了兩個版本:
程式碼庫主要針對 Python 3.8-3.10 和 PyTorch 1.8-2.0 進行開發和測試。這不是嚴格要求,其他版本和庫組合也可以工作。
若要安裝其餘的基本依賴項,請執行:
pip install -r requirements/requirements.txt
pip install -r requirements/requirements-wandb.txt # optional, if logging using WandB
pip install -r requirements/requirements-tensorboard.txt # optional, if logging via tensorboard
pip install -r requirements/requirements-comet.txt # optional, if logging via Comet從儲存庫根目錄。
警告
我們的程式碼庫依賴 DeepSpeed,它是 DeepSpeed 庫的分支,並添加了一些更改。我們強烈建議在繼續之前使用 Anaconda、虛擬機器或其他形式的環境隔離。如果不這樣做,可能會導致依賴 DeepSpeed 的其他儲存庫崩潰。
我們現在透過 JIT 融合核心編譯支援 AMD GPU(MI100、MI250X)。融合內核將根據需要建置和載入。為了避免在作業啟動期間等待,您還可以對手動預先建置執行以下操作:
python
from megatron . fused_kernels import load
load ()這將自動適應不同 GPU 供應商(AMD、NVIDIA)的建置過程,而無需更改特定於平台的程式碼。若要使用pytest進一步測試融合內核,請使用pytest tests/model/test_fused_kernels.py
若要使用 Flash-Attention,請在./requirements/requirements-flashattention.txt中安裝其他依賴項,並在設定中相應地設定注意類型(請參閱設定)。與對某些 GPU 架構(包括 Ampere GPU(例如 A100s))的常規關注相比,這可以提供顯著的加速;有關更多詳細信息,請參閱存儲庫。
NeoX 和 Deep(er)Speed 支援在多個不同節點上進行訓練,您可以選擇使用各種不同的啟動器來編排多節點作業。
一般來說,需要有一個可存取的“主機檔案”,格式如下:
node1_ip slots=8
node2_ip slots=8其中第一列包含設定中每個節點的 IP 位址,插槽數量是該節點可以存取的 GPU 數量。在您的設定中,您必須使用"hostfile": "/path/to/hostfile"傳遞主機檔案的路徑。或者,主機檔案的路徑可以位於環境變數DLTS_HOSTFILE中。
pdsh是預設啟動器,如果您使用pdsh ,那麼您必須做的所有事情(除了確保您的環境中安裝了 pdsh 之外)都是在設定檔中設定{"launcher": "pdsh"} 。
如果使用 MPI,則必須指定 MPI 函式庫(DeepSpeed/GPT-NeoX 目前支援mvapich 、 openmpi 、 mpich和impi ,儘管openmpi是最常用且經過測試的),並在設定檔中傳遞deepspeed_mpi標誌:
{
"launcher" : " openmpi " ,
"deepspeed_mpi" : true
}正確設定環境和正確的設定檔後,您可以像普通 python 腳本一樣使用deepy.py並使用以下命令啟動(例如)訓練作業:
python3 deepy.py train.py /path/to/configs/my_model.yml
使用 Slurm 可能會稍微複雜一些。與 MPI 一樣,您必須將以下內容新增至您的配置:
{
"launcher" : " slurm " ,
"deepspeed_slurm" : true
}如果您無法透過 ssh 存取 Slurm 叢集中的運算節點,則需要新增{"no_ssh_check": true}
在很多情況下,上述預設啟動選項是不夠的
在這些情況下,您將需要修改 DeepSpeed 多節點運行程式實用程式以支援您的用例。總的來說,這些增強功能分為兩類:
在這種情況下,您必須將新的多節點運行器類別新增至deepspeed/launcher/multinode_runner.py並將其公開為 GPT-NeoX 中的設定選項。關於我們如何為 Summit JSRun 執行此操作的範例分別位於 DeeperSpeed 提交和 GPT-NeoX 提交中。
我們遇到許多希望修改 MPI/Slurm 運行命令以進行最佳化或調試的情況(例如,修改 Slurm srun CPU 綁定或使用等級標記 MPI 日誌)。在這種情況下,您必須修改多節點運行器類別的get_cmd方法下的運行命令(例如 OpenMPI 的 mpirun_cmd)。有關我們如何使用 Slurm 和 OpenMPI 為穩定性叢集提供最佳化和排名標記的運行命令的範例,請參閱此 DeeperSpeed 分支
一般來說,您將無法擁有一個固定的主機文件,因此您需要一個腳本來在作業開始時動態產生一個主機文件。使用 Slurm 和每個節點 8 個 GPU 動態產生主機檔案的範例腳本是:
#! /bin/bash
GPUS_PER_NODE=8
mkdir -p /sample/path/to/hostfiles
# need to add the current slurm jobid to hostfile name so that we don't add to previous hostfile
hostfile=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# be extra sure we aren't appending to a previous hostfile
rm $hostfile & > /dev/null
# loop over the node names
for i in ` scontrol show hostnames $SLURM_NODELIST `
do
# add a line to the hostfile
echo $i slots= $GPUS_PER_NODE >> $hostfile
done $SLURM_JOBID和$SLURM_NODELIST是 Slurm 將為您建立的環境變數。有關在作業建立時設定的可用 Slurm 環境變數的完整列表,請參閱 sbatch 文件。
然後您可以建立一個 sbatch 腳本來啟動您的 GPT-NeoX 作業。基於 Slurm 的叢集(每個節點有 8 個 GPU)上的基本 sbatch 腳本如下所示:
#! /bin/bash
# SBATCH --job-name="neox"
# SBATCH --partition=your-partition
# SBATCH --nodes=1
# SBATCH --ntasks-per-node=8
# SBATCH --gres=gpu:8
# Some potentially useful distributed environment variables
export HOSTNAMES= ` scontrol show hostnames " $SLURM_JOB_NODELIST " `
export MASTER_ADDR= $( scontrol show hostnames " $SLURM_JOB_NODELIST " | head -n 1 )
export MASTER_PORT=12802
export COUNT_NODE= ` scontrol show hostnames " $SLURM_JOB_NODELIST " | wc -l `
# Your hostfile creation script from above
./write_hostfile.sh
# Tell DeepSpeed where to find our generated hostfile via DLTS_HOSTFILE
export DLTS_HOSTFILE=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# Launch training
python3 deepy.py train.py /sample/path/to/your/configs/my_model.yml
然後,您可以使用sbatch my_sbatch_script.sh開始訓練運行
如果您喜歡在容器中執行 NeoX,我們也提供 Dockerfile 和 docker-compose 配置。
運行容器的要求是具有適當的 GPU 驅動程式、最新安裝的 Docker 以及安裝的 nvidia-container-toolkit。要測試您的安裝是否良好,您可以使用他們的“範例工作負載”,即:
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
如果它將運行,您需要在您的環境中匯出 NEOX_DATA_PATH 和 NEOX_CHECKPOINT_PATH 以指定您的資料目錄以及用於儲存和載入檢查點的目錄:
export NEOX_DATA_PATH=/mnt/sda/data/enwiki8 #or wherever your data is stored on your system
export NEOX_CHECKPOINT_PATH=/mnt/sda/checkpoints
然後,從 gpt-neox 目錄中,您可以建立映像並在容器中執行 shell
docker compose run gpt-neox bash
建置後,您應該能夠執行以下操作:
mchorse@537851ed67de:~$ echo $(pwd)
/home/mchorse
mchorse@537851ed67de:~$ ls -al
total 48
drwxr-xr-x 1 mchorse mchorse 4096 Jan 8 05:33 .
drwxr-xr-x 1 root root 4096 Jan 8 04:09 ..
-rw-r--r-- 1 mchorse mchorse 220 Feb 25 2020 .bash_logout
-rw-r--r-- 1 mchorse mchorse 3972 Jan 8 04:09 .bashrc
drwxr-xr-x 4 mchorse mchorse 4096 Jan 8 05:35 .cache
drwx------ 3 mchorse mchorse 4096 Jan 8 05:33 .nv
-rw-r--r-- 1 mchorse mchorse 807 Feb 25 2020 .profile
drwxr-xr-x 2 root root 4096 Jan 8 04:09 .ssh
drwxrwxr-x 8 mchorse mchorse 4096 Jan 8 05:35 chk
drwxrwxrwx 6 root root 4096 Jan 7 17:02 data
drwxr-xr-x 11 mchorse mchorse 4096 Jan 8 03:52 gpt-neox
對於長時間運行的作業,您應該運行
docker compose up -d
以分離模式運行容器,然後在單獨的終端會話中運行
docker compose exec gpt-neox bash
然後,您可以從容器內執行任何您想要的作業。
長時間運作或處於分離模式時的問題包括
如果您喜歡從 dockerhub 執行預先建置的容器映像,則可以使用-f docker-compose-dockerhub.yml執行 docker compose 命令,例如,
docker compose run -f docker-compose-dockerhub.yml gpt-neox bash
所有功能都應使用deepy.py啟動,它是deepspeed啟動器的包裝器。
目前我們提供三個主要功能:
train.py用於訓練和微調模型。eval.py用於使用語言模型評估工具評估經過訓練的模型。generate.py用於從經過訓練的模型中取樣文字。可以透過以下方式啟動:
./deepy.py [script.py] [./path/to/config_1.yml] [./path/to/config_2.yml] ... [./path/to/config_n.yml]例如,要啟動訓練,您可以運行
./deepy.py train.py ./configs/20B.yml ./configs/local_cluster.yml有關每個入口點的更多詳細信息,請分別參閱訓練和微調、推理和評估。
GPT-NeoX 參數在傳遞給 deepy.py 啟動器的 YAML 設定檔中定義。我們在配置中提供了一些範例 .yml 文件,顯示了各種功能和模型大小。
這些文件通常是完整的,但不是最佳的。例如,根據您的特定 GPU 配置,您可能需要更改一些設置,例如pipe-parallel-size 、 model-parallel-size來增加或減少並行化程度, train_micro_batch_size_per_gpu或gradient-accumulation-steps來修改批量大小相關設置,或zero_optimization字典來修改優化器狀態在工作執行緒之間的並行化方式。
有關可用功能以及如何配置它們的更詳細指南,請參閱配置自述文件,有關每個可能參數的文檔,請參閱 configs/neox_arguments.md。
GPT-NeoX 包括多個針對 MoE 的專家實施。若要在它們之間進行選擇,請指定moe_type of megablocks (預設)或deepspeed 。
兩者都基於 DeepSpeed MoE 並行框架,該框架支援張量-專家-數據並行。兩者都允許您在代幣丟棄和無丟棄之間切換(默認,這就是 Megablocks 的設計目的)。 Sinkhorn 路線即將推出!
有關基本完整配置的範例,請參閱 configs/125M-dmoe.yml(用於 Megablocks dropless)或 configs/125M-moe.yml。
大多數與 MoE 相關的配置參數都以moe為前綴。一些常見的配置參數及其預設值如下:
moe_type: megablocks
moe_num_experts: 1 # 1 disables MoE. 8 is a reasonable value.
moe_loss_coeff: 0.1
expert_interval: 2 # See details below
enable_expert_tensor_parallelism: false # See details below
moe_expert_parallel_size: 1 # See details below
moe_token_dropping: false
DeepSpeed 可以進一步配置以下內容:
moe_top_k: 1
moe_min_capacity: 4
moe_train_capacity_factor: 1.0 # Setting to 1.0
moe_eval_capacity_factor: 1.0 # Setting to 1.0
每個expert_interval轉換器層(包括第一個)都存在一個 MoE 層,因此總共 12 層:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
專家將分為以下幾層:
0, 2, 4, 6, 8, 10
預設情況下,我們使用專家資料並行性,因此任何可用的張量並行性( model_parallel_size )都將用於專家路由。例如,考慮到以下情況:
expert_parallel_size: 4
model_parallel_size: 2 # aka tensor parallelism
對於 32 個 GPU,行為將如下所示:
expert_parallel_size == model_parallel_size 4 = 8。設定enable_expert_tensor_parallelism可啟用張量專家資料(TED)並行性。解釋上述內容的方法是:
expert_parallel_size == 1或model_parallel_size == 1 。因此請注意 DP 必須能被 (MP * EP) 整除。欲了解更多詳情,請參閱 TED 論文。
尚不支援管道並行性 - 即將推出!
可以使用幾個預先配置的資料集,包括 Pile 中的大多數元件以及 Pile 訓練集本身,以便使用prepare_data.py入口點進行簡單的標記化。
EG,使用 GPT2 Tokenizer 下載並標記 enwik8 資料集,將它們儲存到./data您可以運行:
python prepare_data.py -d ./data
或帶有 GPT-NeoX-20B 分詞器的堆的單一分片 ( pile_subset )(假設您已將其保存在./20B_checkpoints/20B_tokenizer.json ):
python prepare_data.py -d ./data -t HFTokenizer --vocab-file ./20B_checkpoints/20B_tokenizer.json pile_subset
標記化資料將會儲存到兩個檔案: [data-dir]/[dataset-name]/[dataset-name]_text_document.bin [data-dir]/[dataset-name]/[dataset-name]_text_document.idx 。您需要將這兩個檔案共享的前綴新增到data-path位下的訓練設定檔中。例如:
" data-path " : " ./data/enwik8/enwik8_text_document " , 要準備您自己的資料集以使用自訂資料進行訓練,請將其格式化為一個大型 jsonl 格式的文件,其中字典清單中的每個項目都是單獨的文件。文件文字應分組在一個 JSON 鍵下,即"text" 。不會使用儲存在其他欄位中的任何輔助資料。
接下來,請確保下載 GPT2 分詞器詞彙,並從以下連結合併文件:
或使用 20B 分詞器(只需要一個 Vocab 檔案):
(或者,您可以使用Tokenizer.from_pretrained()命令提供可由 Hugging Face 的 tokenizers 庫加載的任何 tokenizer 檔案)
現在您可以使用tools/datasets/preprocess_data.py對資料進行預先標記,其參數詳細資訊如下:
usage: preprocess_data.py [-h] --input INPUT [--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]] [--num-docs NUM_DOCS] --tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer} [--vocab-file VOCAB_FILE] [--merge-file MERGE_FILE] [--append-eod] [--ftfy] --output-prefix OUTPUT_PREFIX
[--dataset-impl {lazy,cached,mmap}] [--workers WORKERS] [--log-interval LOG_INTERVAL]
optional arguments:
-h, --help show this help message and exit
input data:
--input INPUT Path to input jsonl files or lmd archive(s) - if using multiple archives, put them in a comma separated list
--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]
space separate listed of keys to extract from jsonl. Default: text
--num-docs NUM_DOCS Optional: Number of documents in the input data (if known) for an accurate progress bar.
tokenizer:
--tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer}
What type of tokenizer to use.
--vocab-file VOCAB_FILE
Path to the vocab file
--merge-file MERGE_FILE
Path to the BPE merge file (if necessary).
--append-eod Append an <eod> token to the end of a document.
--ftfy Use ftfy to clean text
output data:
--output-prefix OUTPUT_PREFIX
Path to binary output file without suffix
--dataset-impl {lazy,cached,mmap}
Dataset implementation to use. Default: mmap
runtime:
--workers WORKERS Number of worker processes to launch
--log-interval LOG_INTERVAL
Interval between progress updates
例如:
python tools/datasets/preprocess_data.py
--input ./data/mydataset.jsonl.zst
--output-prefix ./data/mydataset
--vocab ./data/gpt2-vocab.json
--merge-file gpt2-merges.txt
--dataset-impl mmap
--tokenizer-type GPT2BPETokenizer
--append-eod然後,您可以在設定檔中新增以下設定來執行訓練:
" data-path " : " data/mydataset_text_document " ,訓練是使用deepy.py啟動的,它是 DeepSpeed 啟動器的包裝器,它在許多 GPU/節點上並行啟動相同的腳本。
一般的使用模式是:
python ./deepy.py train.py [path/to/config1.yml] [path/to/config2.yml] ...您可以傳入任意數量的配置,這些配置將在執行時全部合併。
您也可以選擇傳入配置前綴,這將假定您的所有配置都位於同一資料夾中,並將該前綴附加到其路徑中。
例如:
python ./deepy.py train.py -d configs 125M.yml local_setup.yml這將在所有節點上部署train.py腳本,每個 GPU 一個進程。工作節點和 GPU 數量在/job/hostfile檔案中指定(請參閱參數文件),或者如果在單節點設定上運行,則可以簡單地作為num_gpus arg 傳入。
儘管這並不是絕對必要的,但我們發現在一個設定檔(例如configs/125M.yml )中定義模型參數並在另一個設定檔(例如configs/local_setup.yml )中定義資料路徑參數很有用。
GPT-NeoX-20B 是在 Pile 上訓練的 200 億參數自回歸語言模型。有關 GPT-NeoX-20B 的技術詳細資訊可以在相關論文中找到。此模型的設定檔可在./configs/20B.yml中獲取,並包含在下面的下載連結中。
Slim 權重 -(無優化器狀態,用於推理或微調,39GB)
若要從命令列下載到名為20B_checkpoints的資料夾,請使用下列命令:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/ -P 20B_checkpoints完整權重 -(包括優化器狀態,268GB)
若要從命令列下載到名為20B_checkpoints的資料夾,請使用下列命令:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/full_weights/ -P 20B_checkpoints或者可以使用 BitTorrent 用戶端下載權重。 Torrent 檔案可以在這裡下載:slimweights、fullweights。
我們還在整個訓練過程中保存了 150 個檢查點,每 1,000 步一個。我們正在研究如何最好地大規模服務這些,但與此同時,有興趣使用部分訓練的檢查站的人們可以發送電子郵件至 [email protected] 來安排訪問。
Pythia Scaling Suite 是一套在 Pile 上訓練的模型,範圍從 70M 參數到 12B 參數,旨在促進大型語言模型的可解釋性和訓練動態的研究。有關該專案的更多詳細資訊以及模型的連結可以在論文中和該專案的 GitHub 上找到。
Polyglot 計畫致力於訓練強大的非英語預訓練語言模型,以促進機器學習領域以外的研究人員能夠使用這項技術。 EleutherAI 已經訓練並發布了 1.3B、3.8B 和 5.8B 參數韓語語言模型,其中最大的模型在韓語任務上優於所有其他公開可用的語言模型。有關該項目的更多詳細資訊以及模型的連結可以在此處找到。
對於大多數用途,我們建議透過 Hugging Face Transformers 函式庫部署使用 GPT-NeoX 函式庫訓練的模型,該函式庫針對推理進行了更好的最佳化。
我們支援預訓練模型的三種類型的生成:
所有三種類型的文字產生都可以透過python ./deepy.py generate.py -d configs 125M.yml local_setup.yml text_generation.yml啟動,並在configs/text_generation.yml中設定適當的值。
GPT-NeoX 支援透過語言模型評估工具對下游任務進行評估。
要在評估工具上評估經過訓練的模型,只需運行:
python ./deepy.py eval.py -d configs your_configs.yml --eval_tasks task1 task2 ... taskn其中--eval_tasks是評估任務列表,後面跟著空格,例如--eval_tasks lambada hellaswag piqa sciq 。有關所有可用任務的詳細信息,請參閱 lm-evaluation-harness 存儲庫。
GPT-NeoX 僅針對訓練進行了大量最佳化,且 GPT-NeoX 模型檢查點與其他深度學習庫不相容。為了使模型能夠輕鬆加載並與最終用戶共享,並進一步導出到各種其他框架,GPT-NeoX 支援檢查點轉換為 Hugging Face Transformers 格式。
儘管 NeoX 支援許多不同的架構配置,包括 AliBi 位置嵌入,但並非所有這些配置都能清楚地對應到 Hugging Face Transformers 中支援的配置。
NeoX 支援將相容模型匯出到以下架構:
訓練一個不適合這些 Hugging Face Transformers 架構之一的模型需要為導出的模型編寫自訂建模程式碼。
若要將 GPT-NeoX 庫檢查點轉換為 Hugging Face-loadable 格式,請執行:
python ./tools/ckpts/convert_neox_to_hf.py --input_dir /path/to/model/global_stepXXX --config_file your_config.yml --output_dir hf_model/save/location --precision {auto,fp16,bf16,fp32} --architecture {neox,mistral,llama}然後要將模型上傳到 Hugging Face Hub,請執行:
huggingface-cli login
python ./tools/ckpts/upload.py並輸入請求的信息,包括 HF hub 用戶令牌。
NeoX 提供了幾個實用程序,用於將預先訓練的模型檢查點轉換為可以在庫中訓練的格式。
GPT-NeoX 中可以載入以下模型或模型系列:
我們提供了兩個實用程序,用於將兩種不同的檢查點格式轉換為與 GPT-NeoX 相容的格式。
若要將 Meta AI 分發的 Llama 1 或 Llama 2 檢查點從其原始檔案格式(可在此處或此處下載)轉換為 GPT-NeoX 庫,請執行
python tools/ckpts/convert_raw_llama_weights_to_neox.py --input_dir /path/to/model/parent/dir/7B --model_size 7B --output_dir /path/to/save/ckpt --num_output_shards <TENSOR_PARALLEL_SIZE> (--pipeline_parallel if pipeline-parallel-size >= 1)
若要將 Hugging Face 模型轉換為 NeoX 可載入模型,請執行tools/ckpts/convert_hf_to_sequential.py 。如需更多選項,請參閱該文件中的文件。
除了在本地儲存日誌之外,我們還為兩種流行的實驗監控框架提供內建支援:Weights & Biases、TensorBoard 和 Comet
記錄我們實驗的權重和偏差是一個機器學習監控平台。要使用 wandb 監控您的 gpt-neox 實驗:
wandb login來完成此操作 - 您的跑步將自動記錄。./requirements/requirements-wandb.txt中找到並安裝。 ./configs/local_setup_wandb.yml中提供了範例配置。wandb_group允許您命名運行群組, wandb_team允許您將運行分配給組織或團隊帳戶。 ./configs/local_setup_wandb.yml中提供了範例配置。 我們支援透過tensorboard-dir欄位使用TensorBoard。 TensorBoard 監控所需的相依性可以在./requirements/requirements-tensorboard.txt中找到並安裝。
Comet 是一個機器學習監控平台。要使用 comet 監控您的 gpt-neox 實驗:
comet login或傳遞export COMET_API_KEY=<your-key-here>在執行時間連結您的 API 金鑰pip install -r requirements/requirements-comet.txt安裝comet_ml和任何依賴函式庫use_comet: True啟用 Comet。您也可以使用comet_workspace和comet_project自訂記錄資料的位置。 configs/local_setup_comet.yml中提供了啟用 comet 的完整範例設定。如果您需要提供與基於 MPI 的 DeepSpeed 啟動器一起使用的主機文件,您可以將環境變數DLTS_HOSTFILE設定為指向該主機文件。
我們支援使用 Nsight Systems、PyTorch Profiler 和 PyTorch Memory Profiling 進行分析。
若要使用 Nsight Systems 分析,請設定設定選項profile 、 profile_step_start和profile_step_stop (請參閱此處以了解參數用法,並參閱此處查看範例設定)。
若要填入 nsys 指標,請使用下列命令啟動訓練:
nsys profile -s none -t nvtx,cuda -o <path/to/profiling/output> --force-overwrite true
--capture-range=cudaProfilerApi --capture-range-end=stop python $TRAIN_PATH/deepy.py
$TRAIN_PATH/train.py --conf_dir configs <config files>
然後可以使用 Nsight Systems GUI 查看產生的輸出檔:
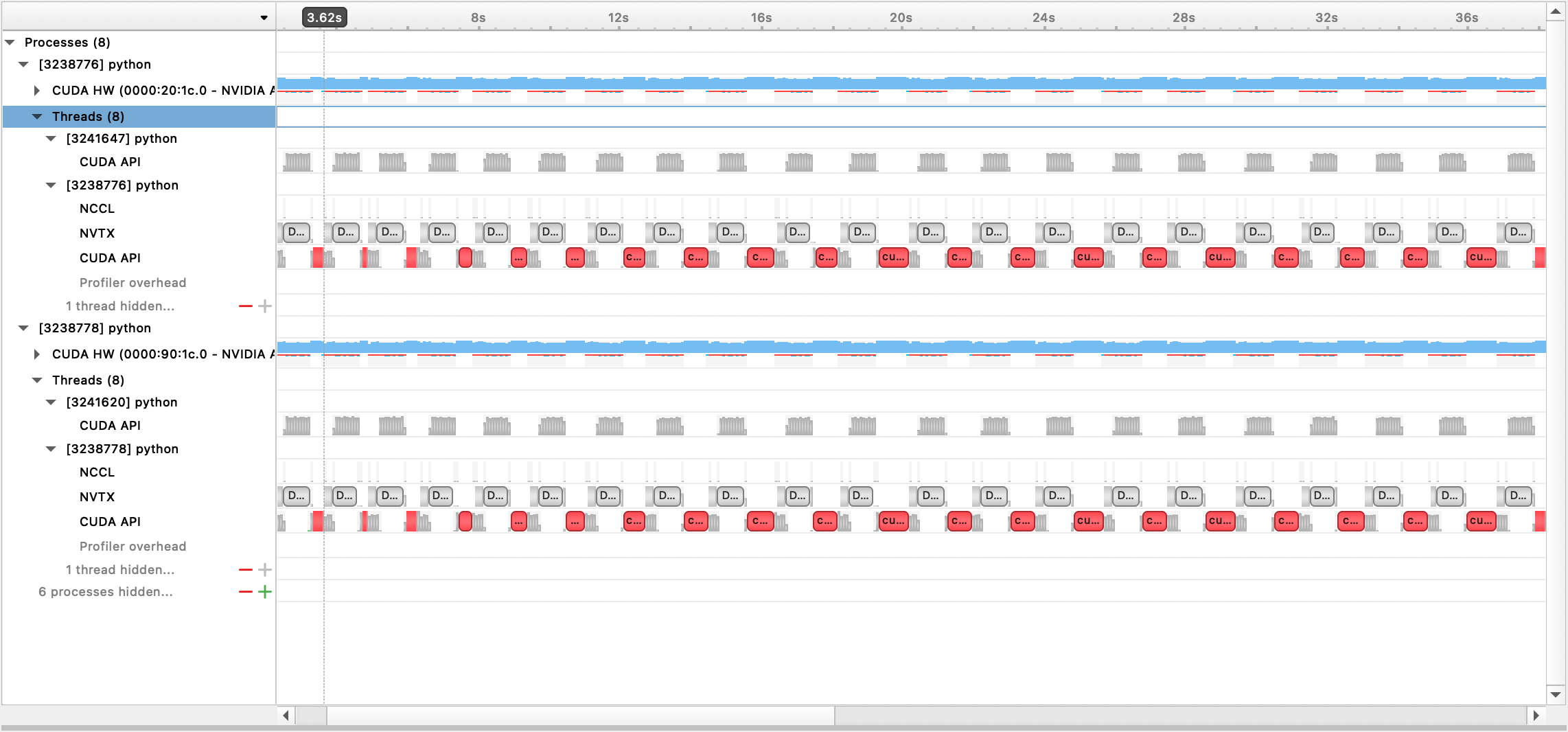
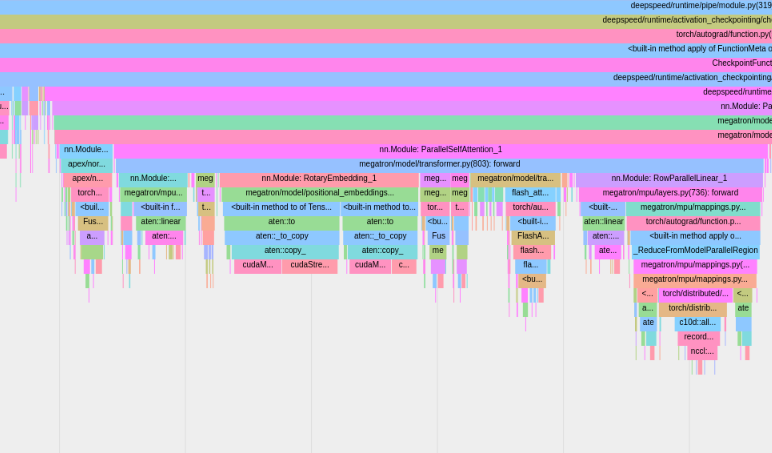
若要使用內建 PyTorch 分析器,請設定設定選項profile 、 profile_step_start和profile_step_stop (請參閱此處了解參數用法,並參閱此處查看範例設定)。
PyTorch 分析器會將追蹤資訊儲存到您的tensorboard日誌目錄中。您可以按照此處的步驟在 TensorBoard 中查看這些追蹤。
若要使用 PyTorch 記憶體分析,請設定配置選項memory_profiling和memory_profiling_path (有關參數用法,請參閱此處,有關範例配置,請參閱此處)。
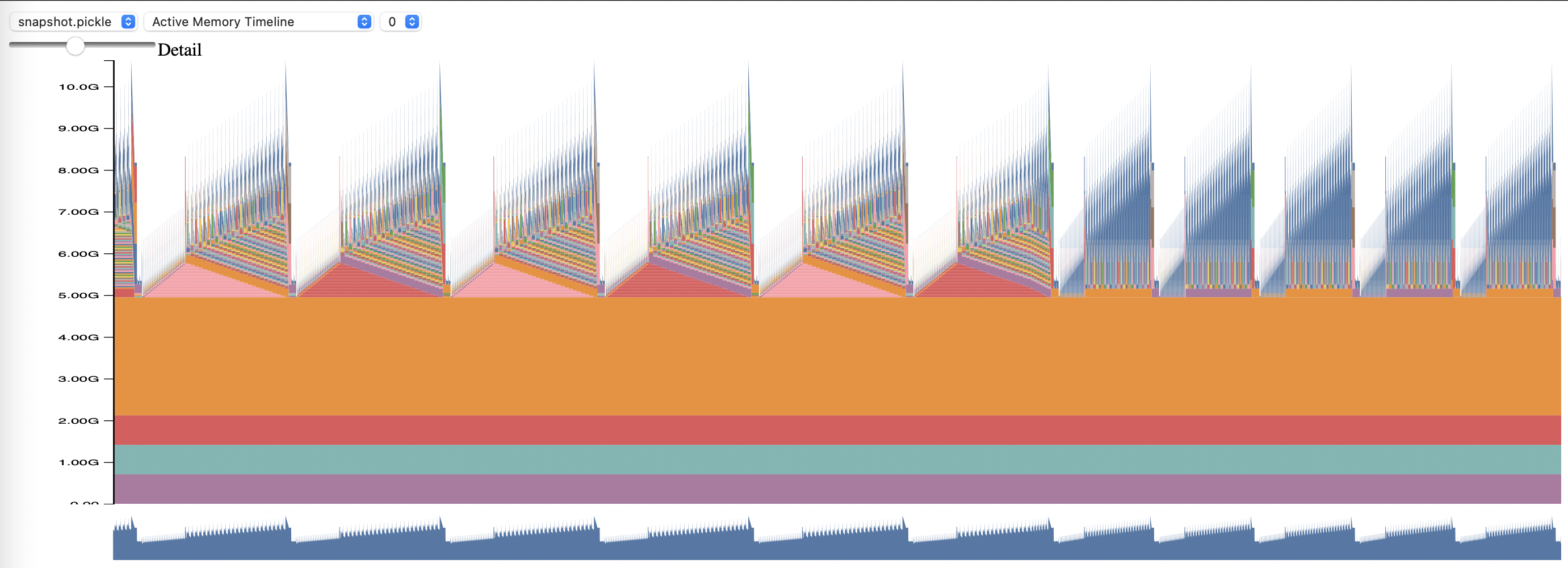
使用 memory_viz.py 腳本查看產生的設定檔。運行:
python _memory_viz.py trace_plot <generated_profile> -o trace.html
GPT-NeoX 庫被學術界和行業研究人員廣泛採用,並移植到許多 HPC 系統上。
如果您發現該庫對您的研究有用,請與我們聯繫!我們很樂意將您添加到我們的清單中。
EleutherAI 和我們的合作者已在以下出版物中使用它:
其他研究小組的以下出版物使用該庫:


