verslibre
1.0.0
該儲存庫包含使用具有 GPT 架構的生成語言模型產生短詩的程式碼。
使用基於GPT架構的變革性語言模型。該模型考慮了俄語的語法(類似於 rugpt 等語言模型)及其語音學,包括押韻規則和詩律的構造。詳細資訊在演示中。
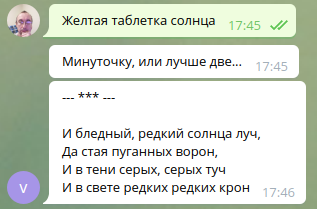
模型二進位檔案可在 inkoziev/verslibre:latest docker 映像中找到。
下載並執行鏡像:
sudo docker pull inkoziev/verslibre:latest
sudo docker run -it inkoziev/verslibre:latest
啟動後,程式將要求您輸入電報機器人的令牌。
載入所有模型後,您可以使用 /start 命令在聊天中啟動機器人。機器人會要求您為您的論文選擇三個隨機主題之一或輸入您自己的主題。主題可以是任何以名詞為主導的短語,例如“詩歌生成器”。
該機器人可在電報中以 @verslibre_bot 的身份使用
生成範例:
* * *
Любовь - источник вдохновения,
Души непризнанных людей.
И день весеннего цветения,
Омытый зеленью дождей…
* * *
Душа, гонимая страстями,
Тревожит, веет теплотой.
Любовь, хранимая стихами,
И примиренье, и покой.
除了生成模型本身之外,標記訓練模型來源詩歌的詩歌轉錄器對於正確運作也非常重要。您可以在此處閱讀有關轉錄員工作的更多資訊。
docker 映像 inkoziev/haiku:latest 可用於將生成器作為電報機器人運作。
下載鏡像並執行:
sudo docker pull inkoziev/haiku:latest
sudo docker run -it inkoziev/haiku
該程式將要求您輸入電報機器人令牌。然後模型將加載(大約一分鐘),您可以與機器人進行通訊。輸入種子 - 名詞或片語。在 CPU 上產生多個選項大約需要 30 秒。然後機器人將顯示第一個選項並提出評估它,或顯示下一個選項。
該機器人可以在電報中以@haiku_guru_bot 的身份找到。
由於這是一個隨機生成模型,因此通常不能透過簡單地引入相同的種子來複製其結果。複製好的結果,用說明性模型(例如 ruDALLE)對其進行補充,並獲得完全獨特的內容:

更多俳句的例子可以在我的部落格上看到。
tmp 子目錄包含帶有部分訓練資料的檔案:
詩歌_corpus.txt - 過濾後的絕句語料庫,符號|作為行分隔符號;用於 ruGPT 模型的額外訓練。
詩歌生成器資料集.dat - 用於訓練 ruGPT 的資料集,它按主題(關鍵短語)生成一首詩的文本。
Captions_generator_rugpt.dat - 用於訓練 ruGPT 的資料集,根據其內容產生詩句標題。
可以在此處找到訓練團準備過程的描述。


