microGPT
1.0.0
microGPT 是用於自然語言處理任務的生成式預訓練 Transformer (GPT) 模型的輕量級實作。它的設計簡單且易於使用,使其成為小型應用程式或學習和實驗生成模型的絕佳選擇。
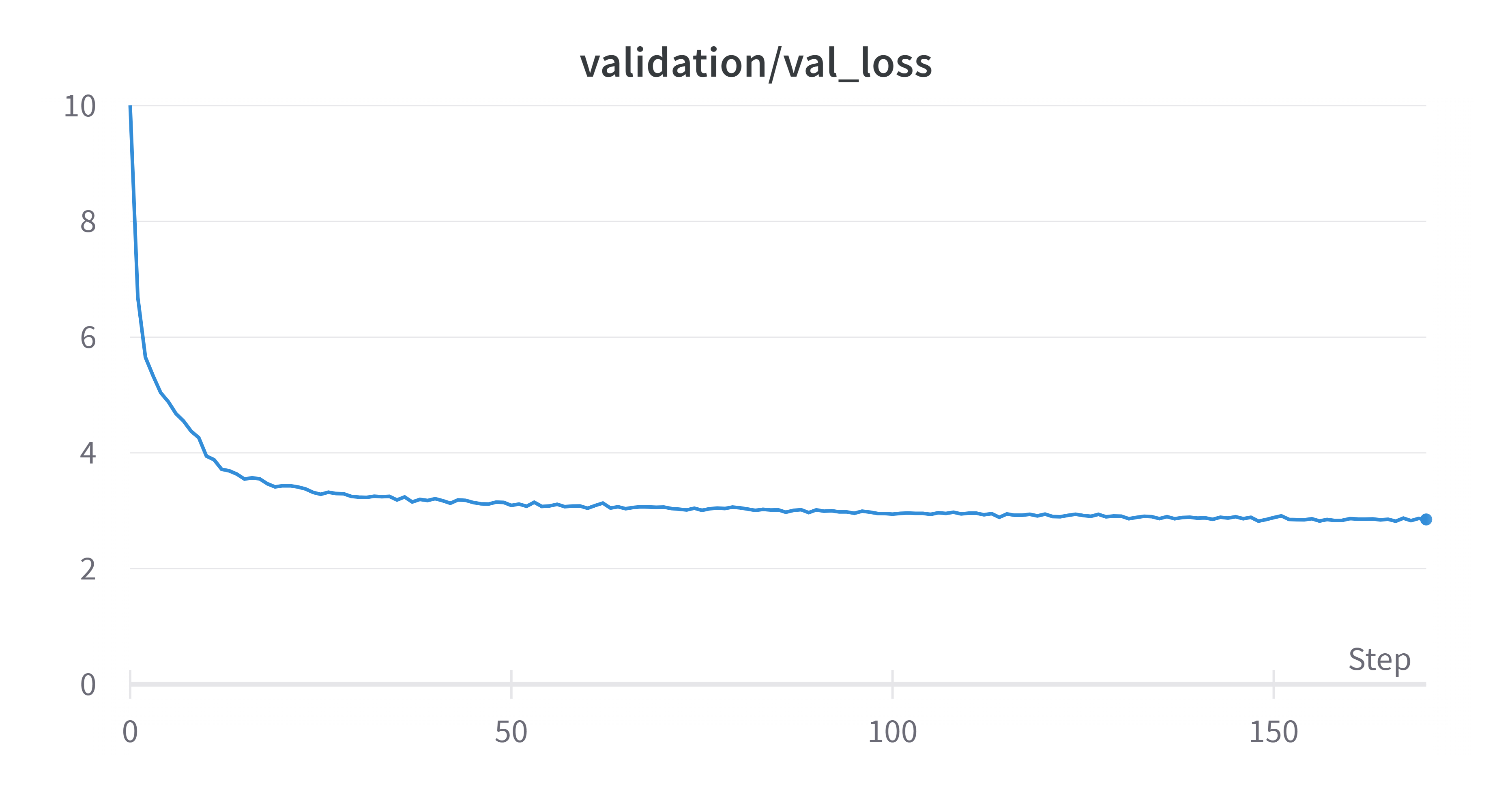 300k 次訓練迭代
300k 次訓練迭代
pip install -r requirements.txt tokenizer/train_tokenizer.py以產生 tokenizer 檔案。該模型將基於它對文本進行標記。datasets/prepare_dataset.py產生資料集檔案。train.py開始訓練~如果您想更改其參數,請修改上述文件。
若要編輯模型產生參數,請從inference.py轉到此部分:
# Parameters (Edit here):
n_tokens = 1000
temperature = 0.8
top_k = 0
top_p = 0.9
model_path = 'models/microGPT.pth'
# Edit input here
context = "The magical wonderland of"有興趣部署為網頁應用程式嗎?查看 microGPT 部署!
從頭開始的效率:從頭開始開發的 microGPT 代表了受人尊敬的 GPT 模型的簡化方法。它展示了卓越的效率,同時在品質上保持了輕微的權衡。
學習遊樂場: microGPT 的架構專為渴望深入人工智慧世界的個人而設計,提供了掌握生成模型內部運作的獨特機會。它是磨練您的技能和加深您的理解的啟動板。
小型動力室:除了學習和實驗之外,microGPT 也是小型應用程式的合適選擇。它使您能夠將人工智慧驅動的語言生成整合到效率和效能至關重要的專案中。
客製化能力: microGPT 的適應性使您能夠修改和微調模型以滿足您的特定目標,為創建適合您的要求的 AI 解決方案提供了畫布。
學習之旅:使用 microGPT 作為理解生成模型基礎的墊腳石。其易於存取的設計和文件為人工智慧新手提供了理想的環境。
實驗實驗室:透過調整和測試 microGPT 的參數來參與實驗。該模型的簡單性和多功能性為創新提供了肥沃的土壤。
如果您想做出貢獻,請遵循以下準則:
透過向此儲存庫做出貢獻,您同意遵守我們的行為準則,並且您的貢獻將在與儲存庫相同的許可證下發布。
模型的靈感來自 Andrej Karpathy 讓我們從頭開始建立 GPT 影片和 Andrej Kaparthy nanoGPT 並對此專案進行了修改。


