llmjudge
1.0.0
在開放式場景中評估法學碩士很困難,越來越多的人認為缺乏現有基準,經驗豐富的從業者更喜歡親自檢查模型。我參考了我信任的開發人員和研究人員的軼事評估,而 Chatbot Arena 是一個很好的補充。這個 repo 背後的動機是使用強大的 LLM 作為模型判斷的越來越流行的方法。這種方法已經存在了幾個月,包括 JudgeLM 和最近的 MT-Bench 等模型。
您可能看過也可能沒有看過這個貼文。根據 Arize AI 推文的作者,使用法學碩士作為法官需要謹慎對待伺服器,特別是在使用數字分數評估方面。法學碩士似乎在處理連續範圍方面非常糟糕,當提示他們評估從 1 到 10 的X時,這一點變得非常明顯。最近的工作在 MT-Bench 和人類判斷 (Arena Elo) 之間建立了很強的相關性,這意味著法學碩士有能力擔任法官,那麼這是怎麼回事?
以下是完整的詳細資訊和結果。
由於成本限制,我最初將重點放在推文中描述的拼字/拼字錯誤任務。我有點擔心這個任務的定量 X 會影響這個實驗的見解,但我們會看到的。我歡迎對這現象進行更全面的分析,鑑於實驗有限,我的結果應該持保留態度
我從 Paul Graham 的文章中產生了一個拼字或拼字錯誤的資料集,不確定哪個名稱更合適。這種選擇主要是出於方便,因為我之前在壓力測試上下文視窗時使用過該資料集。我從論文中提取了 3,000 個單字的上下文,並根據所需的拼字錯誤率在隨機單字上插入拼字錯誤。在偽代碼中:
misspell_ratio
words = split context into words
misspell_count = calculate number of words to misspell based on ratio
FOR word = sample(words, misspell_count)
IF length(word) > 3
extract random character
ELSE:
add random character
END FOR
完整的程式碼可以作為筆記本輕鬆取得。
給定生成的資料集,我們提示法學碩士使用不同的評分範本評估上下文中拼寫錯誤的單字數量。我們使用以下 API
GPT-4: gpt-4-0125-preview
GPT-3.5: gpt-3.5-turbo-1106
在溫度 = 0 時。
測驗 1.讓我們確認法學碩士很難在零樣本設定中處理數字範圍。我們使用數字評分範本提示 GPT-3.5 和 GPT-4,範圍從 0 分到 10 分。
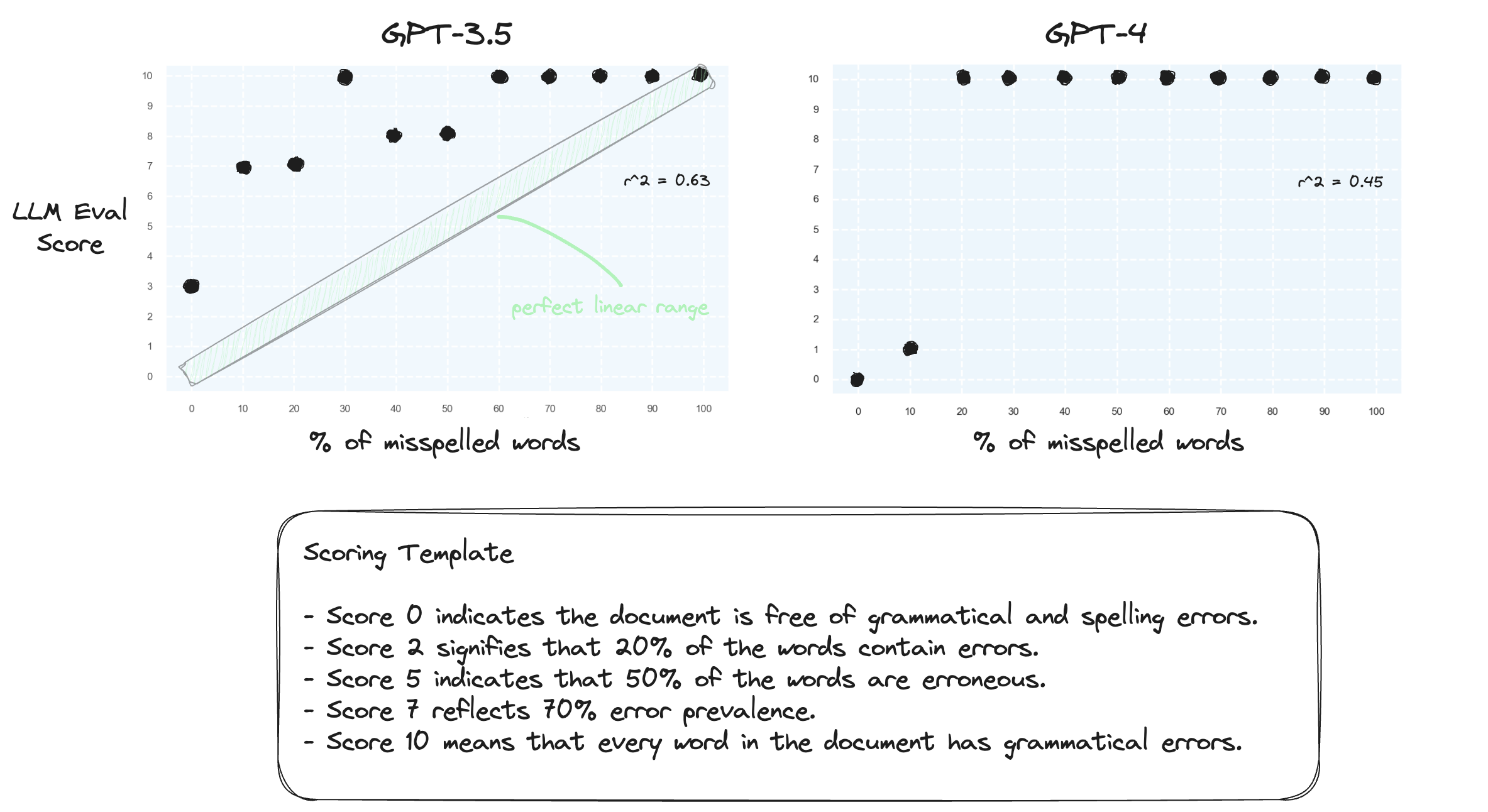
正如所料,兩人都嚴重誤判。
測驗 2.如果我們顛倒評分範圍會發生什麼事?現在,10 分代表文檔拼字完美。
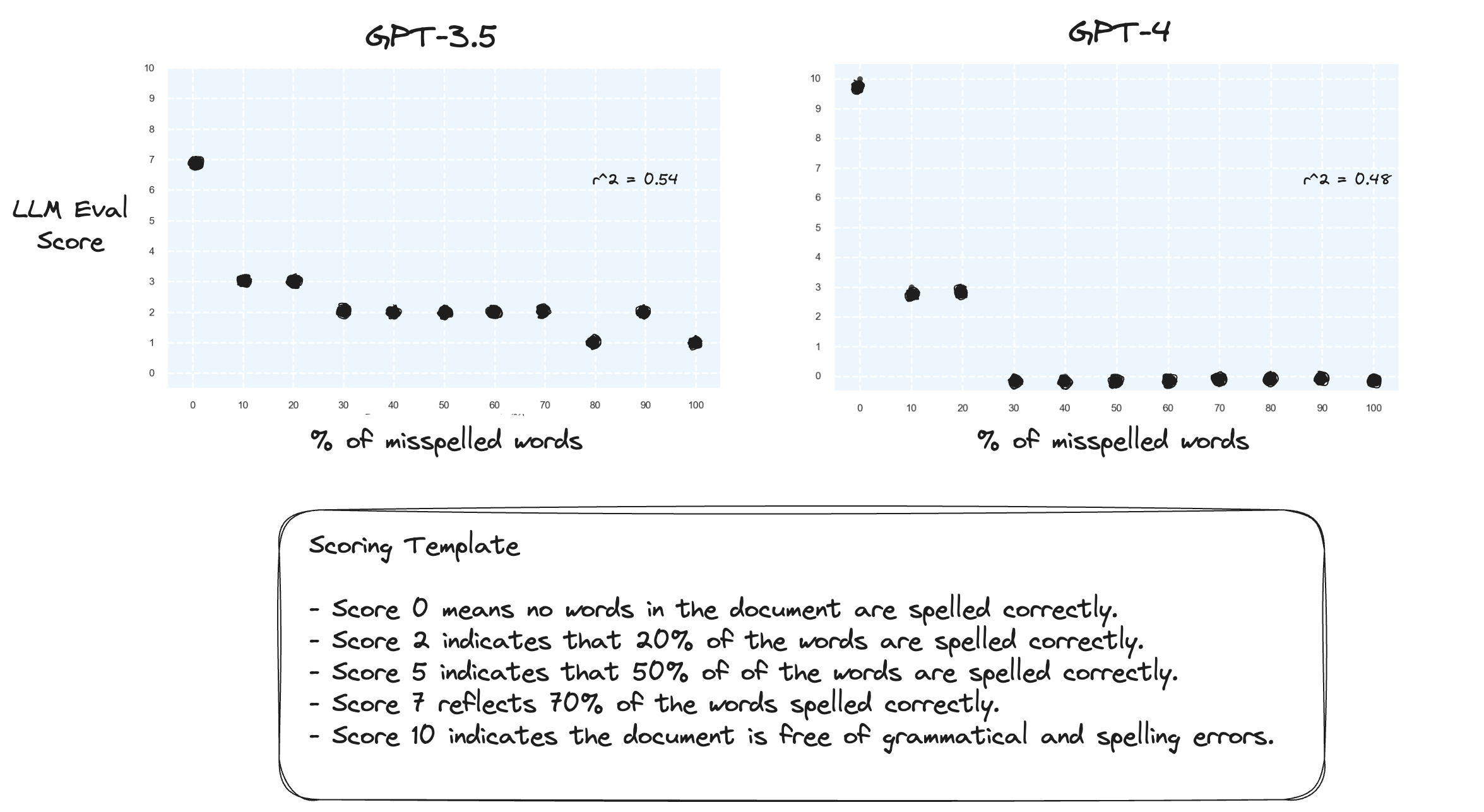
這似乎沒有多大區別。
測試 3:如果我們相信 Arize 的假設,那麼如果我們避免評分標準並使用“標記等級”,我們可能會看到改進。在這種情況下,我決定將評分標準下調至 5 分。
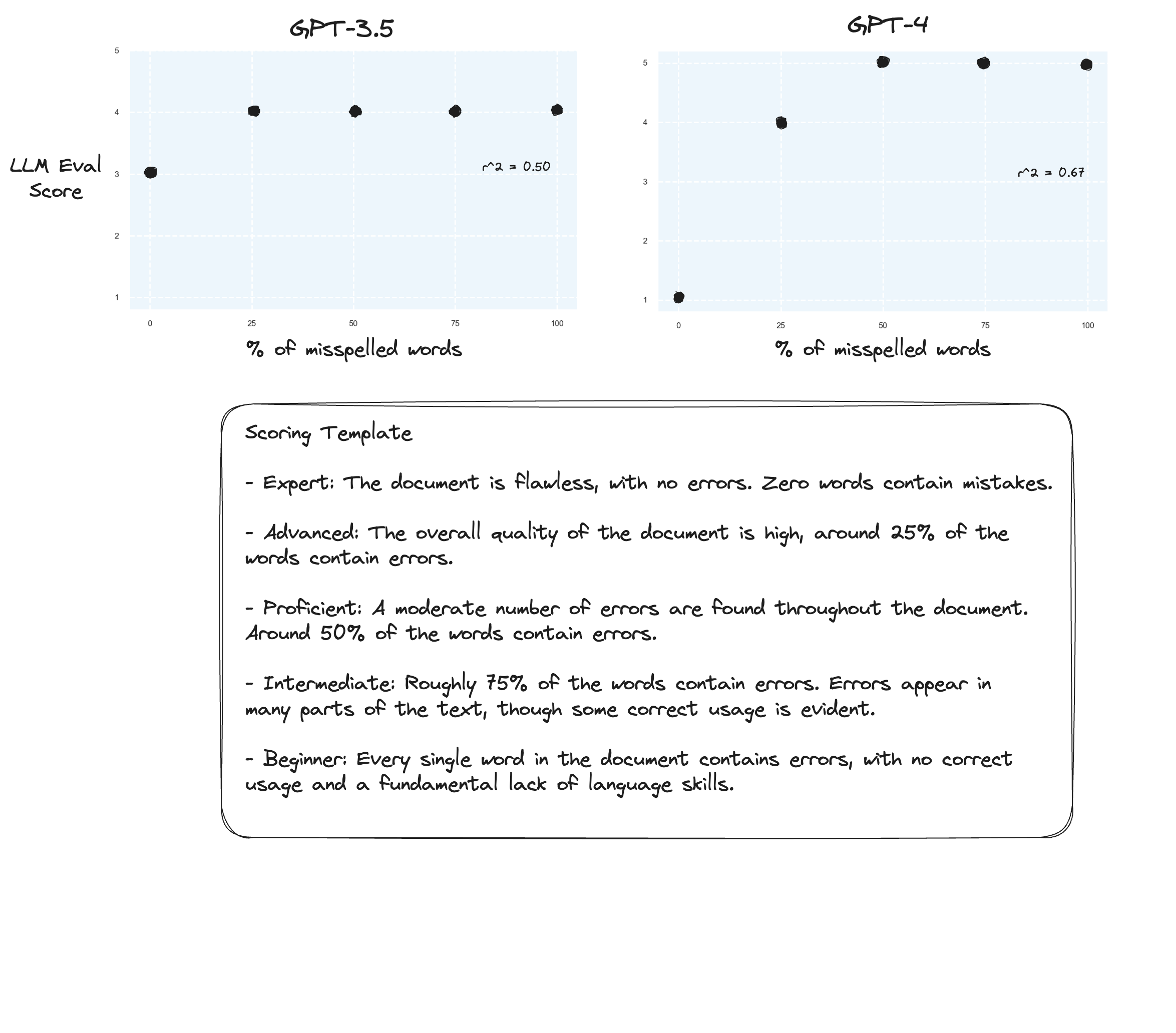
也許略有改進?很難說實話。我沒有留下深刻的印象。
測驗 4.零樣本思維鏈怎麼樣?

gpt-3.5 的兩個提示變成了亂碼。正如預期的那樣,當提示大聲思考時,gpt-4 會得到改進。請注意,它對於是否給出 10 分非常猶豫。
測試5.按照Prometheus作者的建議;將每個分數與其自己的解釋進行映射可能會提高法學碩士在整個數字範圍內評分的能力。這與 CoT 相結合,導致:

對 gpt-4 的持續改進。分配邊界分數 0 和 10 仍然非常不情願。
測試 6.在詳細了解 MT Bench 後,我決定測試另一種方法,使用成對比較而不是單獨評分。現在,通常這需要O(n * log N) 次比較,但因為我們已經知道我認為的順序,所以我們只測試最難的情況:比較0% 拼字錯誤與10% 拼字錯誤、10% 與20%等等共 10 比較。請注意,我也使用了零樣本 CoT。
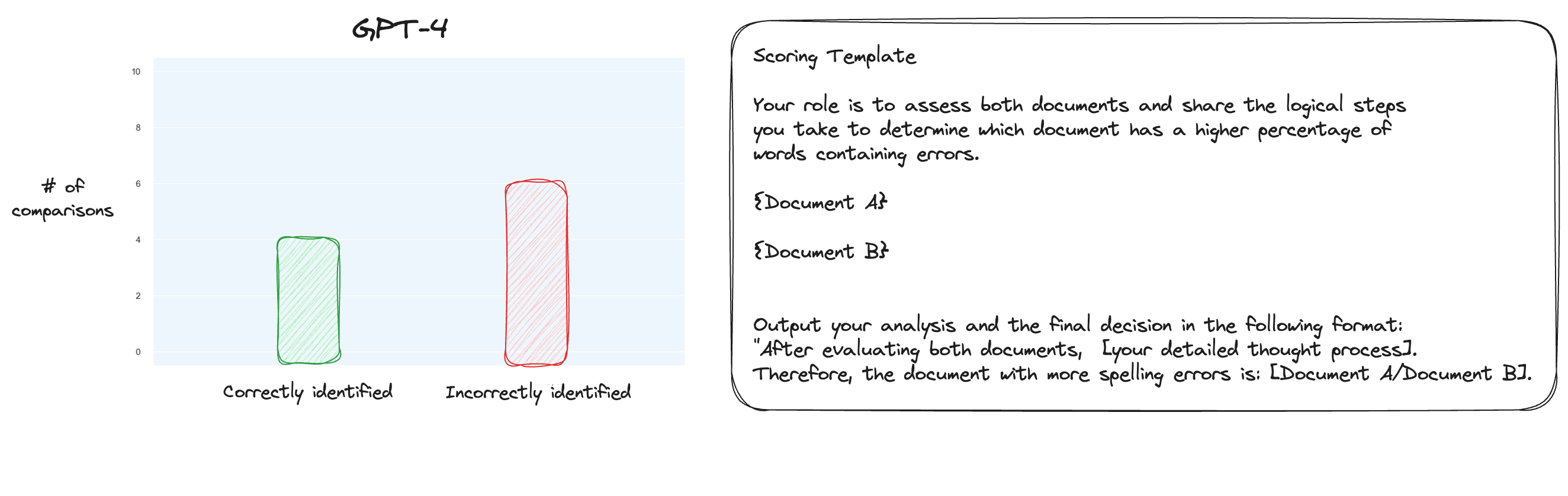
我的假設是,GPT-4 在需要比較上下文視窗內的兩個文本的情況下會表現出色,但我錯了。令我驚訝的是,這根本沒有改善事情。當然,這是所有可能的比較中最困難的,但總而言之,這仍然是一項簡單的任務。也許這項任務的定量方面對於法學碩士來說本質上是非常困難的。嗯,也許我需要找到一個更好的代理任務...
(31/1)我一直在研究 MT-Bench 的內部結構,非常驚訝地發現他們只是要求 GPT-4 以 1-10 的範圍對產出進行評分。他們確實提供了替代的評分選項,例如與基線進行成對比較,但建議的選項是數字選項。判斷提示也出奇的簡單:
請充當公正的法官,評估人工智慧助理對下面顯示的用戶問題的回答品質。您的評估應考慮回覆的效用、相關性、準確性、深度、創造力和詳細程度等因素。透過提供簡短的解釋來開始您的評估。盡可能客觀。提供解釋後,您必須嚴格遵循以下格式對回應進行評分:[評分],例如:“評分:5”,範圍為 1 到 10。 [問題] {問題} [助理回答的開始] {答案} [助理回答的結束]
如果有人相信這就是 MT-Bench 中判斷的全部內容,那麼我開始質疑使用拼字錯誤任務作為代理任務...
(2/2)我熱衷於讓 GPT-4 透過成對比較來判斷拼字錯誤的文本,而不是單獨評分。這是 MT Bench 的替代判斷方法之一(儘管他們確實建議孤立評分),我懷疑它更適合這個任務。 CoT + 完整映射結果絕對是一個改進,但我仍然認為還有工作要做。成對評分的缺點當然是您將需要更多的 API 呼叫來建立完整的排名(在實踐中)。


