Darwin
1.0.0
機構:新南威爾斯大學(UNSW)AI4Science & GreenDynamics AI
Darwin 是一個開源項目,致力於根據科學文獻和資料集預先訓練和微調 LLaMA 模型。 Darwin 專為科學領域而設計,重點是材料科學、化學和物理學,它整合了結構化和非結構化科學知識,以提高科學研究中語言模型的功效。
使用和許可聲明:Darwin 已獲得許可並僅供研究使用。該資料集已獲得 CC BY NC 4.0 許可,允許非商業用途。使用此資料集訓練的模型不應用於研究目的之外。重量差異也遵循 CC BY NC 4.0 許可
[2024.11.20]
主要成就
模型性能洞察
數據策略和見解
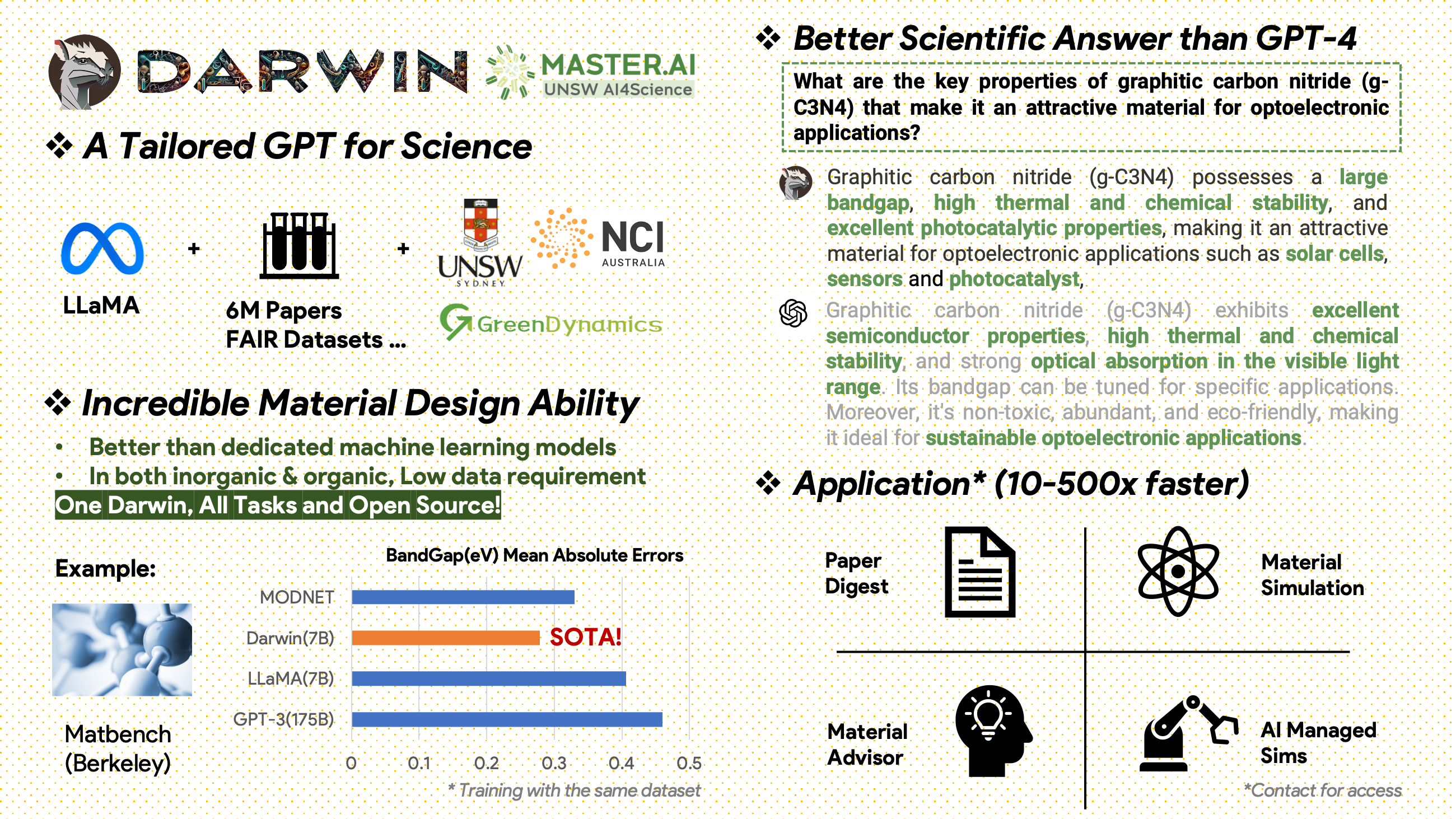
[2024.02.15] Material Projects 的 MatBench 中的 SOTA:DARWIN 是實驗帶隙預測任務和金屬分類任務中的 SOTA 模型,優於 Fine-tuned GPT3.5 和專用 ML 模型。 https://matbench.materialsproject.org/Leaderboards%20Per-Task/matbench_v0.1_matbench_expt_gap/
☆ [2023.09.15]Google Colab 版本可用:透過 Google Colab 試用我們的 DARWIN: inference.ipynb
Darwin 基於 7B LLaMA 模型,接受了 Darwin 科學指令產生器 (SIG) 從各種科學 FAIR 資料集和文獻語料庫產生的超過 100,000 個指令追蹤資料點的訓練。透過關注模型回應的事實正確性,達爾文代表了利用大型語言模型 (LLM) 進行科學發現的重大進步。初步的人類評估表明,Darwin 7B 在科學問答方面優於 GPT-4,在解決化學問題(如 gptChem)方面優於 GPT-3。
我們正在積極開發 Darwin 以進行更高級的科學領域實驗,我們還將 Darwin 與 LangChain 整合以解決更複雜的科學任務(例如個人電腦的私人研究助理)。
請注意,Darwin 仍處於開發階段,有許多限制需要解決。最重要的是,我們尚未對達爾文進行微調以實現最大程度的安全。我們鼓勵使用者報告任何相關行為,以幫助提高模型的安全性和道德考慮。
示範連結
首先安裝要求:
pip install -r requirements.txt從 onedrive 下載 Darwin-7B 重量的檢查點。下載模型後,您可以嘗試我們的演示:
python inference.py < your path to darwin-7b >請注意,Darwin 7B 的推理至少需要 10GB GPU 記憶體。
為了使用不同的資料集進一步微調我們的 Darwin-7b,以下是一個在具有 4 個 A100 80G GPU 的機器上運行的命令。
torchrun --nproc_per_node=8 --master_port=1212 train.py
--model_name_or_path < your path to darwin-7b >
--data_path < your path to dataset >
--bf16 True
--output_dir < your output dir >
--num_train_epochs 3
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 False我們的數據來自兩個主要來源:
2000年後出版了包含材料科學、化學和物理領域600萬篇論文的原始文獻語料庫。我們感謝他們的支持。
FAIR 資料集 - 我們從 16 個 FAIR 資料集中收集了資料。
我們開發了 Darwin-SIG 來產生科學指令。它可以記憶完整文獻文本中的長文本(平均~5000字),並根據科學文獻關鍵字產生問答(Q&A)數據(來自web of science API)
注意:您也可以使用 GPT3.5 或 GPT-4 進行生成,但這些選項可能會很昂貴。
請注意,由於與發布者達成協議,我們無法共享訓練資料集。
該項目是以下各方的共同努力:
新南威爾斯大學和 GreenDynamics:謝童、王紹洲
新南威爾斯大學:伊姆蘭拉扎克、科迪黃
USYD 和 DARE 中心:Clara Grazian
綠色動力:萬宇偉、劉逸軒
新南威爾斯大學工程學院的 Bram Hoex 和 Wenjie Zhang 為所有人提供了建議。
如果您在工作中使用此儲存庫中的資料或程式碼,請相應地引用它。
DAWRIN 基礎大語言模式與半自指導微調
@misc{xie2023darwin,
title={DARWIN Series: Domain Specific Large Language Models for Natural Science},
author={Tong Xie and Yuwei Wan and Wei Huang and Zhenyu Yin and Yixuan Liu and Shaozhou Wang and Qingyuan Linghu and Chunyu Kit and Clara Grazian and Wenjie Zhang and Imran Razzak and Bram Hoex},
year={2023},
eprint={2308.13565},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
用於材料發現的微調 GPT-3 和 LLaMA(單任務訓練)
@article{xie2023large,
title={Large Language Models as Master Key: Unlocking the Secrets of Materials Science},
author={Xie, Tong and Wan, Yuwei and Zhou, Yufei and Huang, Wei and Liu, Yixuan and Linghu, Qingyuan and Wang, Shaozhou and Kit, Chunyu and Grazian, Clara and Zhang, Wenjie and others},
journal={Available at SSRN 4534137},
year={2023}
}
本專案參考了以下開源專案:
特別感謝 NCI 澳洲的 HPC 支持。
我們不斷擴大達爾文的開發團隊。加入我們,踏上利用人工智慧推進科學研究的令人興奮的旅程!
對於博士或博士後職位,請聯繫 [email protected] 或 [email protected] 以了解詳細資訊。
其他職位,請造訪 www.greendynamics.com.au


