GPT_subtitles
1.0.0
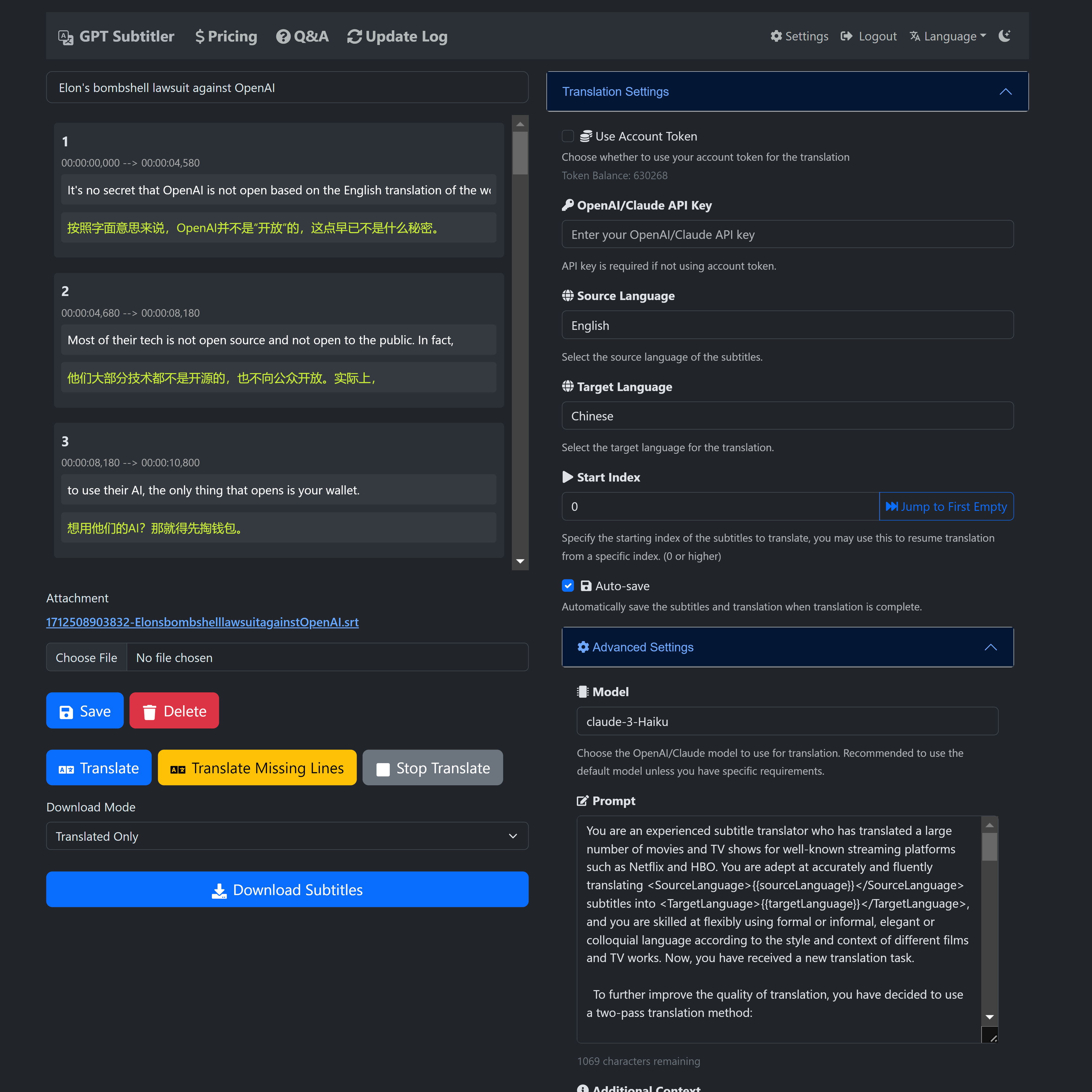
? GPT Subtitler 是一個受此專案啟發的 Web 應用程序,具有許多強大的功能:
支援使用Anthropic Claude、GPT-3.5、GPT-4等多種模型進行高品質字幕翻譯。目前推薦使用Claude-Haiku模型。
此外, Gemini-1.5-flash和Gemini-1.5-pro模型可供免費用戶試用,儘管它們可能不如 Claude-Haiku 模型準確。
?新用戶註冊後即可獲得100,000個免費代幣,足以免費翻譯20分鐘的視訊字幕。
?每天都可以領取免費代幣,也可以低價購買代幣。使用 AI 翻譯不需要 API 金鑰。
?即時預覽翻譯結果,支援編輯提示、少量範例,並能夠隨時停止翻譯並從任何位置重新開始。翻譯後可匯出多種SRT字幕檔案格式(譯文+原版或原版+翻譯雙語字幕)。
網站目前處於早期開發階段,需要您的支持和回饋!歡迎您嘗試並提出寶貴建議。
如果您在使用過程中遇到任何Bug或有任何建議,請隨時在GitHub專案上提出問題或透過電子郵件發送回饋。
網站連結 https://gptsubtitler.com/en
感謝您的支持與閱讀本文!
這是 100,000 個代幣的兌換代碼: GPTSubtitler_github_repo
您可以在“設定”中使用它
下載YouTube影片(或提供您自己的影片)並使用Whisper和翻譯API產生雙語字幕,中文文件請見中文
該專案是一個Python腳本,它下載YouTube影片(或使用本地視訊檔案),對其進行轉錄,將轉錄文字翻譯成目標語言,並產生帶有雙字幕(原始和翻譯)的影片。轉錄和翻譯分別由 Whisper 模型和翻譯 API(M2M100、google、GPT3.5)提供支援。
GPT-3.5 翻譯與 Google 翻譯的比較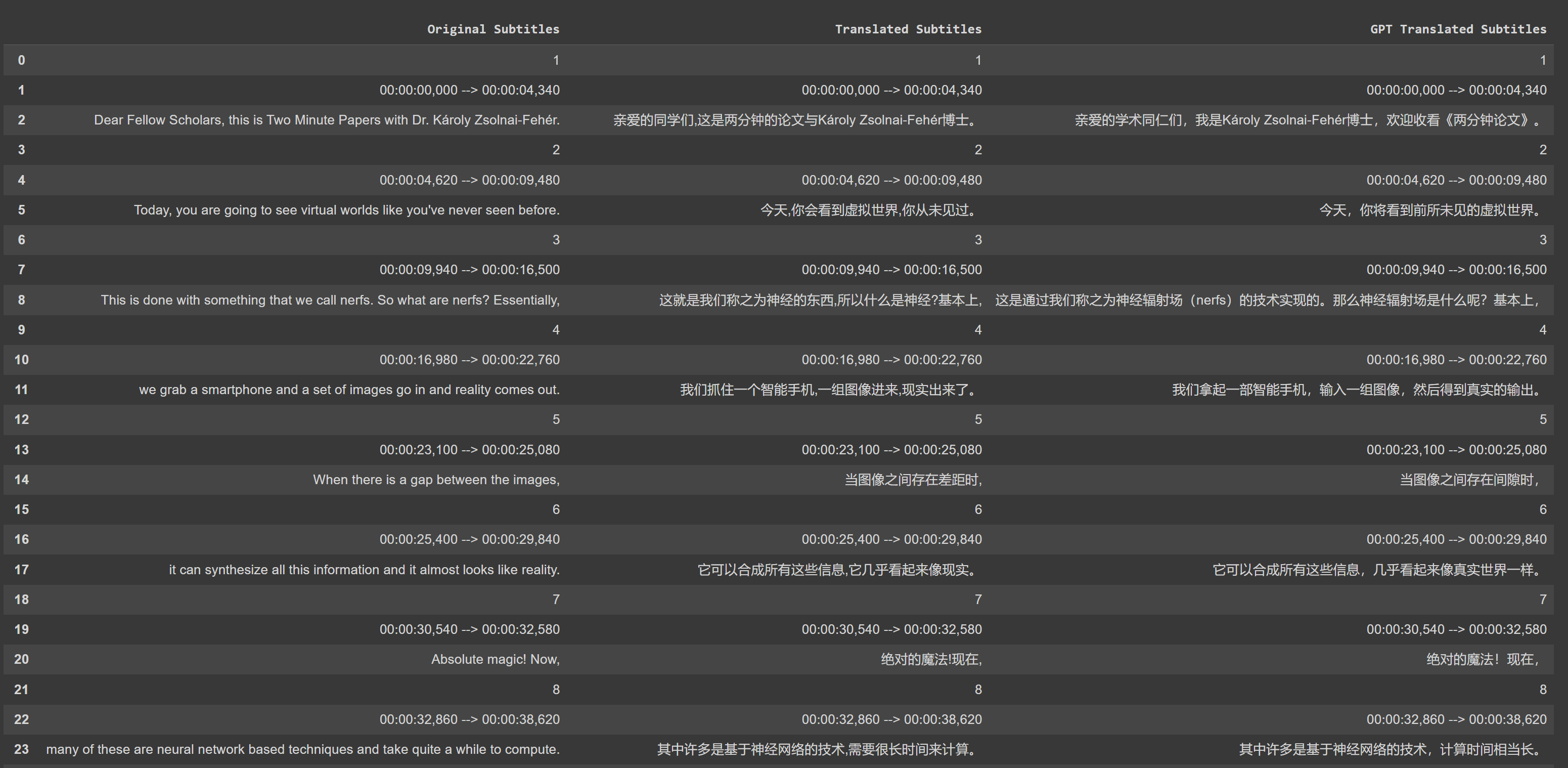
論點: 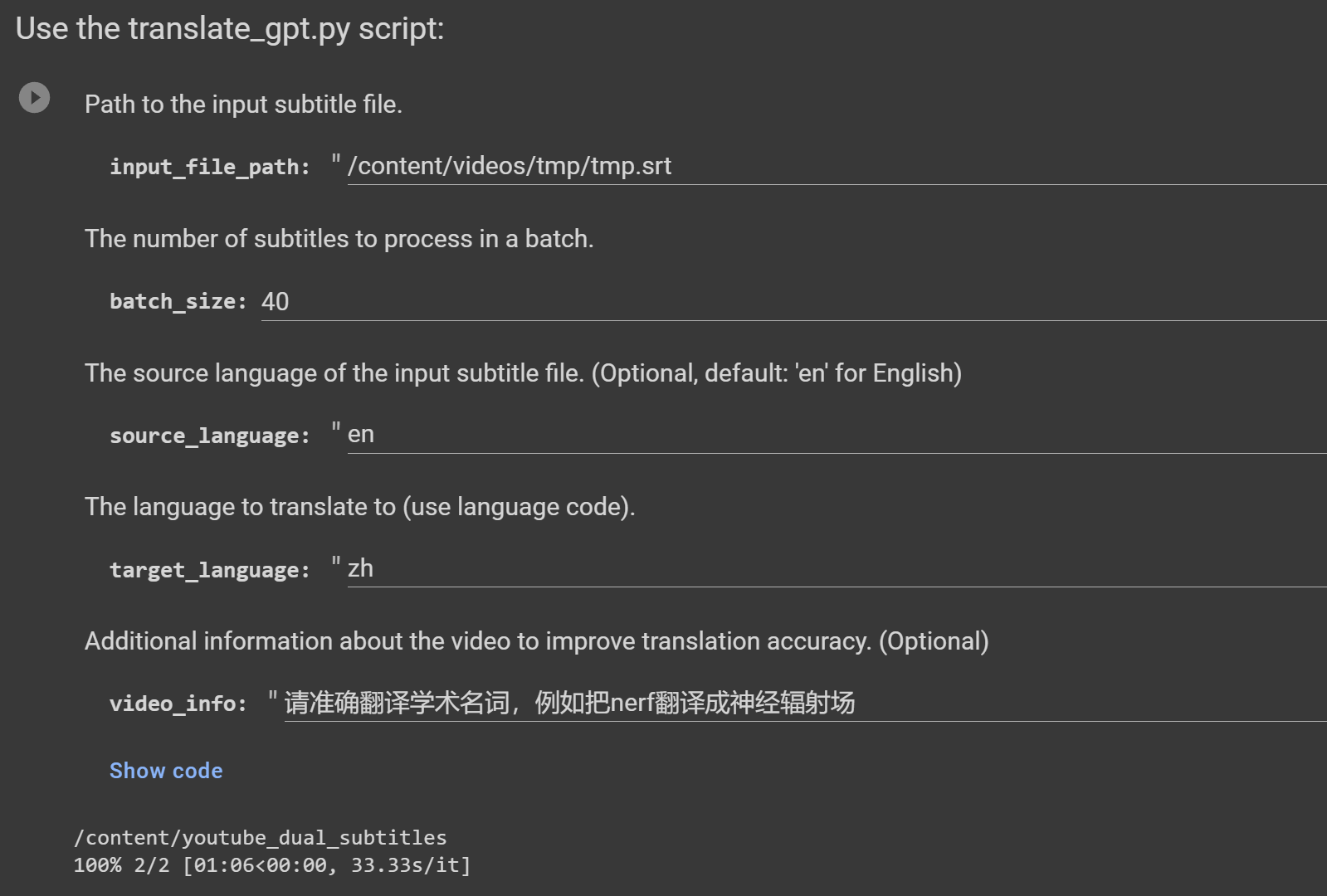
此外,首次執行腳本時,它將下載以下預訓練模型:
pip install -r requirements.txt安裝所需的依賴項您可以提供 YouTube URL 或本機影片檔案進行處理。該腳本將轉錄影片、翻譯轉錄文字並產生 SRT 檔案形式的雙字幕。
python main.py --youtube_url [YOUTUBE_URL] --target_language [TARGET_LANGUAGE] --model [WHISPER_MODEL] --translation_method [TRANSLATION_METHOD]
--youtube_url:YouTube 影片的 URL。
--local_video:本機視訊檔案的路徑。
--target_language:翻譯的目標語言(預設值:'zh')。
--model:選擇 Whisper 模型之一(預設值:'small',選項:['tiny', 'base', 'small', 'medium', 'large'])。
--translation_method:用於翻譯的方法。 (預設值:“google”,選擇:[“m2m100”、“google”、“whisper”、“gpt”、“no_translate”])。
--no_transcribe:跳過轉錄步驟。假設有一個與影片檔同名的SRT文件
注意:您必須提供 --youtube_url 或 --local_video,但不能同時提供兩者。
要下載 YouTube 影片、對其進行轉錄,並使用 google api 進行翻譯,產生目標語言的字幕:
python main.py --youtube_url [YOUTUBE_URL] --target_language 'zh' --model 'small' --translation_method 'google'
要處理本機視訊檔案、對其進行轉錄並使用 gpt3.5-16k 產生目標語言的字幕(您需要提供 OpenAI API 金鑰):
python main.py --local_video [VIDEO_FILE_PATH] --target_language 'zh' --model 'medium' --translation_method 'gpt'
該腳本將在與輸入影片相同的目錄中產生以下輸出檔:
腳本使用 OpenAI 的 GPT-3.5 語言模型翻譯字幕。它需要OpenAI API 金鑰才能運作。在大多數情況下,與 Google 翻譯相比,基於 GPT 的翻譯會產生更好的結果,特別是在處理特定於上下文的翻譯或慣用表達時。該腳本旨在當谷歌翻譯等傳統翻譯服務無法產生令人滿意的結果時,提供另一種翻譯字幕的方法。
OPENAI_API_KEY=your_api_key_here
將 your_api_key_here 替換為您從 OpenAI 取得的 API 金鑰。
python translate_gpt.py --input_file INPUT_FILE_PATH [--batch_size BATCH_SIZE] [--target_language TARGET_LANGUAGE] [--source_language SOURCE_LANGUAGE] [--video_info VIDEO_INFO] [--model MODEL_NAME] [--no_mapping] [--load_tmp_file]
您可以檢查包含輸入視訊檔案的資料夾中的response.log檔案以進行即時更新,類似於ChatGPT 的體驗。
筆記:
視訊資訊: --video_info參數接受任何語言的詳細資訊。它可用於告知 GPT 模型有關視訊內容的信息,從而改進上下文特定術語(例如遊戲中的專有名詞)的翻譯。例如,如果翻譯與遊戲相關的視頻,您可以指示 GPT 對遊戲中的術語使用精確的翻譯。
翻譯映射:此功能透過儲存來源-目標翻譯對來保持常用術語的一致性。啟用後,它可以防止影片中專有名詞和技術術語等術語的翻譯發生變化。如果願意,可以使用--no_mapping標誌來停用此功能。
復原翻譯:使用--load_tmp_file標誌從先前中斷的位置繼續翻譯任務。該腳本將進度保存在tmp_subtitles.json中,允許無縫恢復而無需重做先前的工作。
語言支援:雖然該腳本在英語到簡體中文翻譯方面表現出色,但它也可以容納其他語言對。透過為few_shot_examples.json添加客製化的少數範例來提高其他語言的準確性。請注意,GPT 模型的效能可能會因多語言輸入而異,並且可能需要在translate_gpt.py中進行提示調整。
非常歡迎您的貢獻!
您也可以使用 Google Colab 筆記本嘗試此腳本。點擊下面的連結訪問範例:
按照筆記本中的說明下載必要的套件和模型,並在所需的 YouTube 影片或本機影片檔案上執行腳本。


