ke dialogue
1.0.0


這是論文的實現:
學習帶有面向任務的對話系統參數的知識庫。 Andrea Madotto 、Samuel Cahyawijaya、Genta Indra Winata、Yan Xu、Zihan Liu、Zhaojian Lin、Pascale Fung EMNLP 2020 調查結果[PDF]
如果您在工作中使用此工具包中包含的任何原始程式碼或資料集,請引用以下論文。 bibtex 列出如下:
@文章{madotto2020學習,
title={任務導向的對話系統使用參數學習知識庫},
作者={Madotto、Andrea 和 Cahyawijaya、Samuel 和 Winata、Genta Indra 和 Xu、Yan 和 Liu、Zihan 和 Lin、Zhaojian 和 Fung、Pascale},
期刊={arXiv預印本arXiv:2009.13656},
年={2020}
}
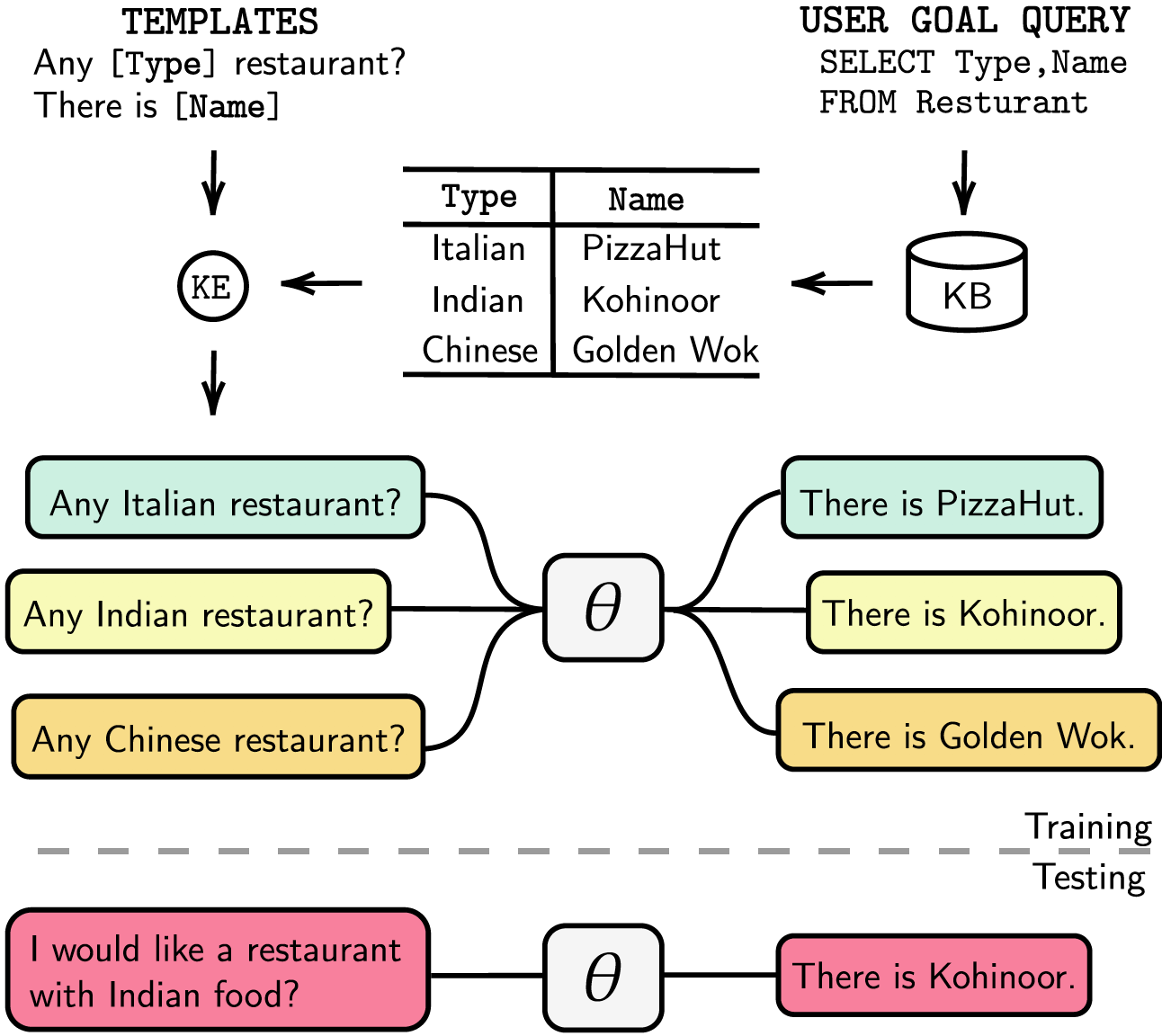
面向任務的對話系統要么是模組化的,具有單獨的對話狀態追蹤(DST)和管理步驟,要么是端到端可訓練的。無論哪種情況,知識庫 (KB) 在滿足使用者請求方面都發揮著重要作用。模組化系統依賴 DST 與 KB 交互,這在註釋和推理時間方面是昂貴的。端對端系統直接使用 KB 作為輸入,但當 KB 大於數百個條目時,它們無法擴展。在本文中,我們提出了一種將任意大小的 KB 直接嵌入到模型參數中的方法。產生的模型不需要任何 DST 或模板回應,也不需要 KB 作為輸入,並且它可以透過微調動態更新其 KB。我們在五個具有小、中、大 KB 大小的任務導向的對話資料集中評估我們的解決方案。我們的實驗表明,端到端模型可以有效地將知識庫嵌入其參數中,並在所有評估的資料集中實現有競爭力的效能。
我們在requirements.txt中列出了我們的依賴項,您可以透過執行來安裝依賴項
❱❱❱ pip install -r requirements.txt此外,我們的程式碼還包括帶有apex fp16支援。您可以從 https://github.com/NVIDIA/apex 找到該軟體包。
資料集下載預處理後的資料集並將 zip 檔案放入./knowledge_embed/babi5資料夾中。透過執行解壓縮 zip 檔案
❱❱❱ cd ./knowledge_embed/babi5
❱❱❱ unzip dialog-bAbI-tasks.zip透過 bAbI-5 資料集生成去詞彙化對話
❱❱❱ python3 generate_delexicalization_babi.py透過 bAbI-5 資料集產生詞彙化數據
❱❱❱ python generate_dialogues_babi5.py --dialogue_path ./dialog-bAbI-tasks/dialog-babi-task5trn_record-delex.txt --knowledge_path ./dialog-bAbI-tasks/dialog-babi-kb-all.txt --output_folder ./dialog-bAbI-tasks --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0其中最大<num_augmented_knowledge>為558(建議), <num_augmented_dialogues>為264,因為它對應於bAbI-5資料集中的知識數量和對話數量。
微調 GPT-2
我們提供在 bAbI 訓練集上微調的 GPT-2 模型的檢查點。您也可以選擇使用以下指令自行訓練模型。
❱❱❱ cd ./modeling/babi5
❱❱❱ python main.py --model_checkpoint gpt2 --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues>注意, --kbpercentage的值等於來自詞彙化的<num_augmented_dialogues>值。此參數用於選擇要嵌入到訓練資料集中的增強檔案。
您可以透過執行以下腳本來評估模型
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks對 bAbI-5 進行評分要執行 bAbI-5 任務模型的評分器,您可以執行以下命令。 Scorer將讀取從evaluate.py產生的runs資料夾下的所有result.json
python scorer_BABI5.py --model_checkpoint <model_checkpoint> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --kbpercentage 0數據集
下載預處理後的資料集並將zip檔案放在./knowledge_embed/camrest資料夾下。透過執行解壓縮 zip 檔案
❱❱❱ cd ./knowledge_embed/camrest
❱❱❱ unzip CamRest.zip透過 CamRest 資料集產生去詞彙化對話
❱❱❱ python3 generate_delexicalization_CAMREST.py透過 CamRest 資料集產生詞彙化數據
❱❱❱ python generate_dialogues_CAMREST.py --dialogue_path ./CamRest/train_record-delex.txt --knowledge_path ./CamRest/KB.json --output_folder ./CamRest --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0其中最大<num_augmented_knowledge>為201(建議), <num_augmented_dialogues>為156,相當大,因為它對應於CamRest資料集中的知識數量和對話數量。
微調 GPT-2
我們提供在 CamRest 訓練集上微調的 GPT-2 模型的檢查點。您也可以選擇使用以下指令自行訓練模型。
❱❱❱ cd ./modeling/camrest/
❱❱❱ python main.py --model_checkpoint gpt2 --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues>注意, --kbpercentage的值等於來自詞彙化的<num_augmented_dialogues>值。此參數用於選擇要嵌入到訓練資料集中的增強檔案。
您可以透過執行以下腳本來評估模型
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest CamRest 評分要執行 bAbI 5 任務模型的評分器,您可以執行以下命令。 Scorer將讀取從evaluate.py產生的runs資料夾下的所有result.json
python scorer_CAMREST.py --model_checkpoint <model_checkpoint> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --kbpercentage 0數據集
下載預處理後的資料集並將其放在./knowledge_embed/smd資料夾下。
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ unzip SMD.zip微調 GPT-2
我們提供在 SMD 訓練集上微調的 GPT-2 模型的檢查點。下載檢查點並將其放在./modeling資料夾下。
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ mkdir ./runs
❱❱❱ unzip ./knowledge_embed/smd/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12.zip -d ./runs您也可以選擇使用以下指令自行訓練模型。
❱❱❱ cd ./modeling/smd
❱❱❱ python main.py --dataset SMD --lr 6.25e-05 --n_epochs 10 --kbpercentage 0 --layers 12準備知識嵌入對話
首先,我們需要建立用於SQL查詢的資料庫。
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ python generate_dialogues_SMD.py --build_db --split test然後,我們根據網域預先設計的範本產生對話。以下命令使您能夠在weather領域產生對話。如果您想在其他兩個網域中產生對話,請將dialogue_path和domain參數中的weather替換為navigate或schedule 。您也可以透過更改參數num_augmented_dialogue來更改重新詞法化過程中使用的模板數量。
❱❱❱ python generate_dialogues_SMD.py --split test --dialogue_path ./templates/weather_template.txt --domain weather --num_augmented_dialogue 100 --output_folder ./SMD/test使微調的 GPT-2 模型適應測試集
❱❱❱ python evaluate_finetune.py --dataset SMD --model_checkpoint runs/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12 --top_k 1 --eval_indices 0,303 --filter_domain ""您也可以透過並行運行實驗來加速微調過程。請修改代碼#L14中的GPU設定。
❱❱❱ python runner_expe_SMD.py 數據集
下載預處理後的資料集並將其放在./knowledge_embed/mwoz資料夾下。
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ unzip mwoz.zip準備知識嵌入對話(如果您已下載上面的 zip 文件,則可以跳過此步驟)
您可以透過運行來準備資料集
❱❱❱ bash generate_MWOZ_all_data.shshell 腳本透過呼叫從 MWOZ 資料集產生去詞彙化對話
❱❱❱ python generate_delex_MWOZ_ATTRACTION.py
❱❱❱ python generate_delex_MWOZ_HOTEL.py
❱❱❱ python generate_delex_MWOZ_RESTAURANT.py
❱❱❱ python generate_delex_MWOZ_TRAIN.py
❱❱❱ python generate_redelex_augmented_MWOZ.py
❱❱❱ python generate_MWOZ_dataset.py微調 GPT-2
我們提供在 MWOZ 訓練集上微調的 GPT-2 模型的檢查點。下載檢查點並將其放在./modeling資料夾下。
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ mkdir ./runs
❱❱❱ unzip ./mwoz.zip -d ./runs您也可以選擇使用以下指令自行訓練模型。
❱❱❱ cd ./modeling/mwoz
❱❱❱ python main.py --model_checkpoint gpt2 --dataset MWOZ_SINGLE --max_history 50 --train_batch_size 6 --kbpercentage 100 --fp16 O2 --gradient_accumulation_steps 3 --balance_sampler --n_epochs 10入門我們使用neo4j社群伺服器版本和apoc函式庫來處理圖形資料。 apoc用於在neo4j中並行化查詢,以便我們可以更快地處理大規模圖
在繼續進行資料集部分之前,您需要確保安裝了neo4j (https://neo4j.com/download-center/#community) 和apoc (https://neo4j.com/developer/neo4j-apoc/)在您的系統上。
如果您不熟悉CYPHER和apoc語法,可以按照https://neo4j.com/developer/cypher/和https://neo4j.com/blog/intro-user-defined-procedures-apoc/中的教學進行操作
資料集下載原始資料集並將 zip 檔案放入./knowledge_embed/opendialkg資料夾中。透過執行解壓縮 zip 檔案
❱❱❱ cd ./knowledge_embed/opendialkg
❱❱❱ unzip https://drive.google.com/file/d/1llH4-4-h39sALnkXmGR8R6090xotE0PE/view?usp=sharing.zip透過 opendialkg 資料集產生去詞彙化對話(警告:這需要大約 12 小時才能運行)
❱❱❱ python3 generate_delexicalization_DIALKG.py該腳本將產生./opendialkg/dialogkg_train_meta.pt ,它將用於產生詞彙化對話。然後,您可以透過 opendialkg 資料集產生詞彙化對話
❱❱❱ python generate_dialogues_DIALKG.py --random_seed <random_seed> --batch_size 100 --max_iteration <max_iter> --stop_count <stop_count> --connection_string bolt://localhost:7687此腳本最多會產生batch_size * max_iter個樣本的對話樣本,但在每個批次中,有可能沒有有效的候選者,導致樣本較少。產生數量受到另一個稱為stop_count因素的限制,如果產生的樣本數量大於等於指定的stop_count則該因素將停止產生。該檔案將產生 4 個檔案: ./opendialkg/db_count_records_{random_seed}.csv 、 ./opendialkg/used_count_records_{random_seed}.csv和./opendialkg/generation_iteration_{random_seed}.csv Generation_iteration_{random_seed}csv. ;和./opendialkg/generated_dialogue_bs100_rs{random_seed}.json {random_seed}.json 其中包含產生的樣本。
注意事項:
generate_delexicalization_DIALKG.py和generate_dialogues_DIALKG.py中的neo4j密碼。微調 GPT-2
我們提供在 opendialkg 訓練集上微調的 GPT-2 模型的檢查點。您也可以選擇使用以下指令自行訓練模型。
❱❱❱ cd ./modeling/opendialkg
❱❱❱ python main.py --dataset_path ../../knowledge_embed/opendialkg/opendialkg --model_checkpoint gpt2 --dataset DIALKG --n_epochs 50 --kbpercentage <random_seed> --train_batch_size 8 --valid_batch_size 8請注意, --kbpercentage的值等於來自詞法化的<random_seed>值。此參數用於選擇要嵌入到訓練資料集中的增強檔案。
您可以透過執行以下腳本來評估模型
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset DIALKG --dataset_path ../../knowledge_embed/opendialkg/opendialkg對 OpenDialKG 進行評分要執行 bAbI-5 任務模型的評分器,您可以執行以下命令。 Scorer將讀取從evaluate.py產生的runs資料夾下的所有result.json
python scorer_DIALKG5.py --model_checkpoint <model_checkpoint> --dataset DIALKG ../../knowledge_embed/opendialkg/opendialkg --kbpercentage 0 有關實驗、超參數和評估結果的詳細信息,您可以在我們工作的主要論文和補充資料中找到。


