MedicalGPT
v2.2.0
??中文|英文|文檔/Docs | ?模型/Models

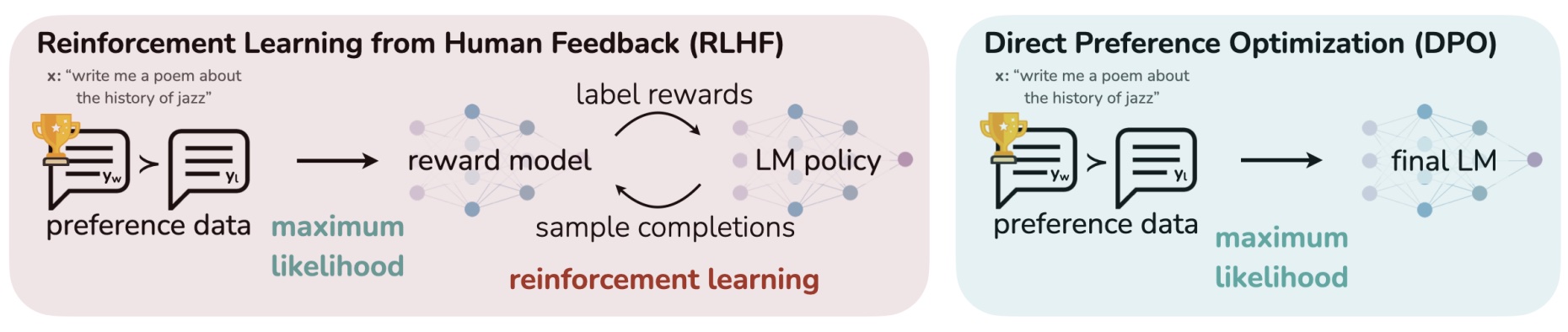
MedicalGPT training medical GPT model with ChatGPT training pipeline, implemantation of Pretraining, Supervised Finetuning, RLHF(Reward Modeling and Reinforcement Learning) and DPO(Direct Preference Optimization).
MedicalGPT訓練醫療大模型,實現了包括增量預訓練、有監督微調、RLHF(獎勵建模、強化學習訓練)和DPO(直接偏好優化)。
[2024/09/21] v2.3版本: 支持了Qwen-2.5系列模型,詳見Release-v2.3
[2024/08/02] v2.2版本:支援了角色扮演模型訓練,新增了醫病對話SFT資料產生腳本role_play_data,詳見Release-v2.2
[2024/06/11] v2.1版:支持了Qwen-2系列模型,詳見Release-v2.1
[2024/04/24] v2.0版:支援了Llama-3系列模型,詳見Release-v2.0
[2024/04/17] v1.9版本:支援了ORPO ,詳細用法請參考run_orpo.sh 。詳見Release-v1.9
[2024/01/26] v1.8版本:支援微調Mixtral混合專家MoE模型Mixtral 8x7B 。詳見Release-v1.8
[2024/01/14] v1.7版本:新增檢索增強生成(RAG)的基於文件問答ChatPDF功能,代碼chatpdf.py ,可以基於微調後的LLM結合知識庫文件問答提升行業問答準確率。詳見Release-v1.7
[2023/10/23] v1.6版本:新增RoPE插值來擴展GPT模型的上下文長度;針對LLaMA模型支援了FlashAttention-2和LongLoRA 提出的
[2023/08/28] v1.5版本: 新增DPO(直接偏好最佳化)方法,DPO透過直接最佳化語言模型來實現對其行為的精確控制,可以有效學習到人類偏好。詳見Release-v1.5
[2023/08/08] v1.4版本: 發布基於ShareGPT4資料集微調的中英文Vicuna-13B模型shibing624/vicuna-baichuan-13b-chat,和對應的LoRA模型shibing624/vicuna-baichuan-13b-chat- lora,詳見Release-v1.4
[2023/08/02] v1.3版本: 新增LLaMA, LLaMA2, Bloom, ChatGLM, ChatGLM2, Baichuan模型的多輪對話微調訓練;新增領域詞表擴充功能;新增中文預訓練資料集和中文ShareGPT微調訓練集,詳見Release-v1.3
[2023/07/13] v1.1版本: 發表中文醫療LLaMA-13B模型shibing624/ziya-llama-13b-medical-merged,基於Ziya-LLaMA-13B-v1模型,SFT微調了一版醫療模型,醫療問答效果有提升,發布微調後的完整模型權重,詳見Release-v1.1
[2023/06/15] v1.0版本: 發表中文醫療LoRA模型shibing624/ziya-llama-13b-medical-lora,基於Ziya-LLaMA-13B-v1模型,SFT微調了一版醫療模型,醫療問答效果有提升,發布微調後的LoRA權重,詳見Release-v1.0
[2023/06/05] v0.2版本: 以醫療為例,訓練領域大模型,實現了四階段訓練:包括二次預訓練、監督微調、獎勵建模、強化學習訓練。詳見Release-v0.2
基於ChatGPT Training Pipeline,本計畫實現了領域模型--醫療產業語言大模型的訓練:
| Model | Base Model | Introduction |
|---|---|---|
| shibing624/ziya-llama-13b-medical-lora | IDEA-CCNL/Ziya-LLaMA-13B-v1 | 在240萬條中英文醫療資料集shibing624/medical上SFT微調了一版Ziya-LLaMA-13B模型,醫療問答效果有提升,發布微調後的LoRA權重(單輪對話) |
| shibing624/ziya-llama-13b-medical-merged | IDEA-CCNL/Ziya-LLaMA-13B-v1 | 在240萬條中英文醫療資料集shibing624/medical上SFT微調了一版Ziya-LLaMA-13B模型,醫療問答效果有提升,發布微調後的完整模型權重(單輪對話) |
| shibing624/vicuna-baichuan-13b-chat-lora | baichuan-inc/Baichuan-13B-Chat | 在10萬條多語言ShareGPT GPT4多輪對話資料集shibing624/sharegpt_gpt4 和醫療資料集shibing624/medical 上SFT微調了一版baichuan-13b-chat多輪問答模型,日常問答和醫療問答效果有提升,發布微調後的LoRA權重 |
| shibing624/vicuna-baichuan-13b-chat | baichuan-inc/Baichuan-13B-Chat | 在10萬條多語言ShareGPT GPT4多輪對話資料集shibing624/sharegpt_gpt4 和醫療資料集shibing624/medical 上SFT微調了一版baichuan-13b-chat多輪問答模型,日常問答和醫療問答效果有提升,發布微調後的完整模型權重 |
| shibing624/llama-3-8b-instruct-262k-chinese | Llama-3-8B-Instruct-262k | 在2萬條中英文偏好資料集shibing624/DPO-En-Zh-20k-Preference上使用ORPO方法微調得到的超長文本多輪對話模型,適用於RAG、多輪對話 |
示範shibing624/vicuna-baichuan-13b-chat模型效果: 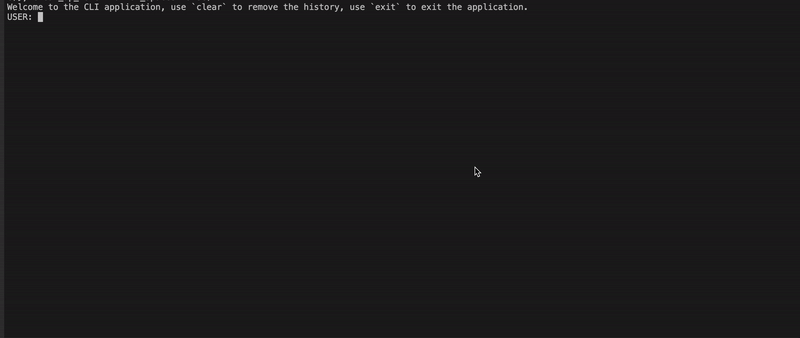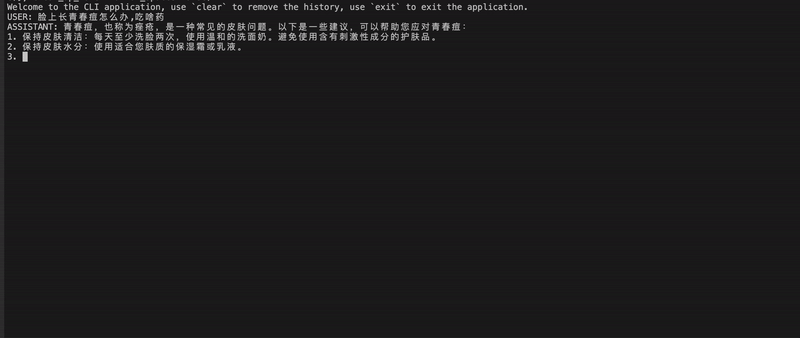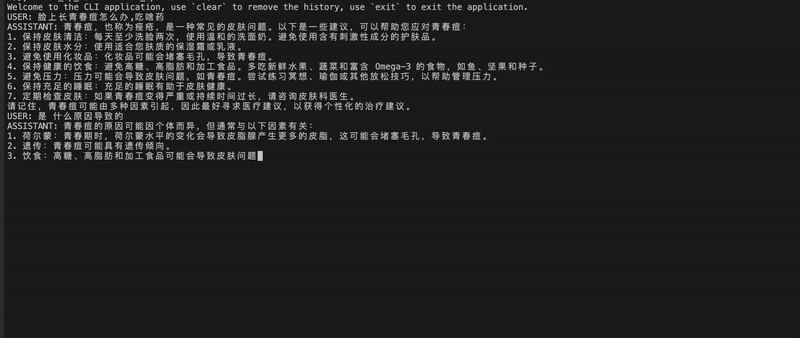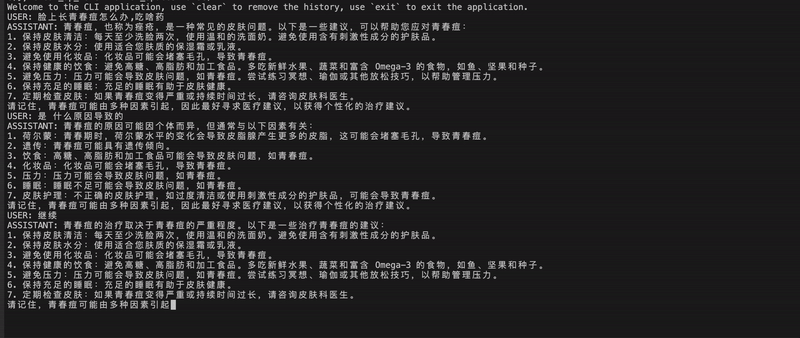 具體case見Inference Examples
具體case見Inference Examples
我們提供了一個簡潔的基於gradio的互動式web介面,啟動服務後,可透過瀏覽器訪問,輸入問題,模型會返回答案。
啟動服務,命令如下:
CUDA_VISIBLE_DEVICES=0 python gradio_demo.py --model_type base_model_type --base_model path_to_llama_hf_dir --lora_model path_to_lora_dir參數說明:
--model_type {base_model_type} :預訓練模型類型,如llama、bloom、chatglm等--base_model {base_model} :存放HF格式的LLaMA模型權重與設定檔的目錄,也可使用HF Model Hub模型呼叫名稱--lora_model {lora_model} :LoRA檔案所在目錄,也可使用HF Model Hub模型呼叫名稱。若lora權重已合併到預訓練模型,則刪除--lora_model參數--tokenizer_path {tokenizer_path} :存放對應tokenizer的目錄。若不提供此參數,則其預設值與--base_model相同--template_name :範本名稱,如vicuna 、 alpaca等。若不提供此參數,則其預設值為vicuna--only_cpu : 僅使用CPU進行推理--resize_emb :是否調整embedding大小,若不調整,則使用預訓練模型的embedding大小,預設不調整 requirements.txt會不時更新以適配最新功能,使用下列指令更新依賴:
git clone https://github.com/shibing624/MedicalGPT
cd MedicalGPT
pip install -r requirements.txt --upgrade*估算值
| 訓練方法 | 精確度 | 7B | 13B | 30B | 70B | 110B | 8x7B | 8x22B |
|---|---|---|---|---|---|---|---|---|
| 全參數 | AMP(自動混合精度) | 120GB | 240GB | 600GB | 1200GB | 2000GB | 900GB | 2400GB |
| 全參數 | 16 | 60GB | 120GB | 300GB | 600GB | 900GB | 400GB | 1200GB |
| LoRA | 16 | 16GB | 32GB | 64GB | 160GB | 240GB | 120GB | 320GB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | 140GB | 60GB | 160GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | 72GB | 30GB | 96GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | 48GB | 18GB | 48GB |
Training Stage:
| Stage | Introduction | Python script | Shell script |
|---|---|---|---|
| Continue Pretraining | 增量預訓練 | pretraining.py | run_pt.sh |
| Supervised Fine-tuning | 有監督微調 | supervised_finetuning.py | run_sft.sh |
| Direct Preference Optimization | 直接偏好優化 | dpo_training.py | run_dpo.sh |
| Reward Modeling | 獎勵模型建模 | reward_modeling.py | run_rm.sh |
| Reinforcement Learning | 強化學習 | ppo_training.py | run_ppo.sh |
| ORPO | 機率偏好優化 | orpo_training.py | run_orpo.sh |
| Model Name | Model Size | Target Modules | Template |
|---|---|---|---|
| Baichuan | 7B/13B | W_pack | baichuan |
| Baichuan2 | 7B/13B | W_pack | baichuan2 |
| BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value | vicuna |
| ChatGLM | 6B | query_key_value | chatglm |
| ChatGLM2 | 6B | query_key_value | chatglm2 |
| ChatGLM3 | 6B | query_key_value | chatglm3 |
| Cohere | 104B | q_proj,v_proj | cohere |
| DeepSeek | 7B/16B/67B | q_proj,v_proj | deepseek |
| InternLM2 | 7B/20B | wqkv | intern2 |
| LLaMA | 7B/13B/33B/65B | q_proj,v_proj | alpaca |
| LLaMA2 | 7B/13B/70B | q_proj,v_proj | llama2 |
| LLaMA3 | 8B/70B | q_proj,v_proj | llama3 |
| Mistral | 7B/8x7B | q_proj,v_proj | mistral |
| Orion | 14B | q_proj,v_proj | orion |
| Qwen | 1.8B/7B/14B/72B | c_attn | qwen |
| Qwen1.5 | 0.5B/1.8B/4B/14B/32B/72B/110B | q_proj,v_proj | qwen |
| Qwen2 | 0.5B/1.5B/7B/72B | q_proj,v_proj | qwen |
| XVERSE | 13B | query_key_value | xverse |
| Yi | 6B/34B | q_proj,v_proj | yi |
訓練完成後,現在我們載入訓練好的模型,驗證模型產生文字的效果。
CUDA_VISIBLE_DEVICES=0 python inference.py
--model_type base_model_type
--base_model path_to_model_hf_dir
--tokenizer_path path_to_model_hf_dir
--lora_model path_to_lora
--interactive參數說明:
--model_type {base_model_type} :預訓練模型類型,如llama、bloom、chatglm等--base_model {base_model} :存放HF格式的LLaMA模型權重與設定檔的目錄--tokenizer_path {base_model} :存放HF格式的LLaMA模型權重與設定檔的目錄--lora_model {lora_model} :LoRA解壓縮後檔案所在目錄,也可使用HF Model Hub模型呼叫名稱。如果已經合併了LoRA權重到預訓練模型,則可以不提供此參數--tokenizer_path {tokenizer_path} :存放對應tokenizer的目錄。若不提供此參數,則其預設值與--base_model相同--template_name :範本名稱,如vicuna 、 alpaca等。若不提供此參數,則其預設值為vicuna--interactive :以互動方式啟動多輪問答,使用串流推理--data_file {file_name} :非互動方式啟動下,讀取file_name中的內容進行batch預測--output_file {file_name} :非互動式方式下,將預測的結果以jsonl格式寫入file_name--resize_emb :是否調整embedding大小,若不調整,則使用預訓練模型的embedding大小,預設不調整--only_cpu :僅使用CPU進行推理--gpus {gpu_ids} :指定使用的GPU設備編號,預設為0。如使用多張GPU,以逗號分隔,如0,1,2 多卡資料並行,batch推理
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 inference_multigpu_demo.py --model_type baichuan --base_model shibing624/vicuna-baichuan-13b-chatbash run_Multi-GPUs-deployment.shshibing624/vicuna-baichuan-13b-chat inference examples:
| Human | Assitant |
|---|---|
| 小孩發燒怎麼辦 | 發燒是身體對感染或其他疾病的自然反應。以下是一些可以幫助緩解發燒症狀的建議: 1. 保持身體水分充足:發燒時,身體會失去水分,因此需要保持水分充足。 2. 使用冰袋:將冰袋放在額頭或頸部可以幫助降低體溫。 3. 使用退燒藥:退燒藥可以幫助降低體溫。 4. 保持身體溫度:保持身體溫度可以幫助降低體溫。 5. 使用冷水或溫水擦拭身體:使用冷水或溫水擦拭身體可以幫助降低體溫。 6. 使用退燒藥:退燒藥可以幫助降低體溫。 7. 保持身體溫度:保持身體溫度可以幫助降低體溫。 8. 使用冷水或溫水擦拭身體:使用冷水或溫水擦拭身體可以幫助降低體溫。 9. 使用退燒藥:退燒藥可以幫助降低體溫。 10. 保持身體溫度:保持身體溫度可以幫助降低體溫。 |
| 一歲寶寶發燒吃啥藥? | 1歲寶寶發燒時,可以考慮以下幾種藥物: 1. 退燒藥:如布洛芬(Ibuprofen)或對乙醯氨基酚(Paracetamol)。這些藥物可以幫助降低體溫,並緩解發燒症狀。 2. 抗生素:如果發燒是由細菌感染引起的,可以考慮使用抗生素。但請務必在醫生的建議下使用。 3. 抗病毒藥物:如果發燒是由病毒感染引起的,可以考慮使用抗病毒藥物。但請務必在醫生的建議下使用。 4. 解熱鎮痛藥:如阿斯匹靈(Aspirin)或對乙醯氨基酚(Paracetamol)。這些藥物可以幫助緩解發燒症狀。 5. 抗組織胺:如苯海拉明(Diphenhydramine)或非索非那定(Naproxen)。這些藥物可以幫助緩解發燒症狀。 請務必在醫生的建議下使用這些藥物,並遵循藥物說明書上的用量和用法。同時,保持寶寶充足的水分攝入,並確保寶寶有足夠的休息。 |
| 肛門病變可能是什麼疾病的症狀 | 肛門病變可能由多種原因引起,包括感染、發炎、腫瘤或其他疾病。一些常見的肛門病變包括: 1. 肛裂:這是一種肛門皮膚撕裂,通常由便秘或其他壓力因素引起。 2. 肛瘺:這是一種肛門感染,導致肛門皮膚和直腸之間形成瘻管。 3. 肛門疣:這是一種肛門皮膚上形成的疣狀病變,通常由人類乳頭狀瘤病毒(HPV)引起。 4. 肛門膿瘍:這是一種肛門感染,導致肛門皮膚下形成膿瘍。 5. 肛門腫瘤:這是一種肛門皮膚或直腸內形成的腫瘤。 6. 肛門潰瘍:這是一種肛門皮膚上形成的潰瘍,通常由感染或發炎引起。 7. 肛門搔癢:這是一種肛門皮膚搔癢的症狀,可能由感染、發炎或其他疾病引起。 如果您有肛門病變的症狀,請諮詢醫療保健專業人員以獲得適當的診斷和治療。 |
| 醫生,您好白帶增多泛黃怎麼回事? | 您好,白帶增多和發黃可能是由多種原因引起的,包括感染、荷爾蒙變化、陰道乾燥或其他婦科問題。以下是一些可能的原因: 1. 感染:白帶增加和發黃可能是陰道或尿道感染引起的。感染可能由細菌、病毒或真菌引起。 2. 荷爾蒙變化:荷爾蒙變化,如月經週期或更年期,可能會導致白帶增加和發黃。 3. 陰道乾燥:陰道乾燥可能會導致白帶增加和發黃。 4. 其他婦科問題:其他婦科問題,如子宮頸炎、子宮內膜炎或子宮內膜異位症,也可能導致白帶增多和發黃。 如果您擔心自己的白帶,建議您諮詢婦科醫生進行檢查和診斷。醫生可以根據您的症狀和檢查結果確定原因並提供適當的治療。 |
| 藥流後有巧克力白帶沒流乾淨嗎 | 藥流後出現巧克力白帶不一定代表沒有流乾淨。巧克力白帶是由於子宮內膜脫落和出血引起的,通常在藥流後的一段時間內會出現。 藥流後出現巧克力白帶的原因可能包括: 1. 子宮內膜脫落:藥流後,子宮內膜會脫落,導致出血。這種出血可能表現為巧克力白帶。 2. 感染:藥流後,子宮內膜和子宮頸口可能有創傷,容易受到細菌感染。感染可能導致巧克力白帶。 3. 荷爾蒙水平變化:藥流後,荷爾蒙水平可能發生變化,導致巧克力白帶。 如果巧克力白帶持續時間較長,或伴隨其他症狀,如腹痛、發燒、分泌物異味等,建議及時就診,進行相關檢查,如婦科檢查、B超等,以確定是否有感染或其他問題。在醫師的指導下進行相應的治療。 |
| 維胺酯維E乳膏能治理什麼疾病 | 維胺酯維E乳膏是一種外用藥物,主要用於治療痤瘡、脂漏性皮膚炎等皮膚病。它可以幫助減少皮膚油脂分泌,減輕炎症,促進皮膚修復。 需要注意的是,維胺酯維E乳膏並非萬用藥,對於某些皮膚病可能並不適用。使用前,建議諮詢醫生或藥師,以了解藥物的適應症、禁忌症、用法用量等資訊。同時,使用藥物時應遵循醫囑,避免自行濫用。 |
| 痤瘡是什麼原因導致的? | 痤瘡,也稱為粉刺,是由皮膚毛孔堵塞引起的。堵塞毛孔的原因有很多,包括: 1. 皮脂腺過度活躍:皮脂腺產生過多油脂,導致毛孔阻塞。 2. 毛孔堵塞:皮膚表面的死皮細胞、油脂和細菌堵塞毛孔。 3. 發炎:痤瘡通常伴隨著炎症,這可能是由於皮膚感染或免疫系統對痤瘡的反應引起的。 4. 遺傳因素:某些人可能更容易患痤瘡,這可能是由於遺傳因素引起的。 5. 荷爾蒙變化:痤瘡在青春期和月經期間更為常見,這可能是由於荷爾蒙變化引起的。 6. 生活方式因素:某些生活方式因素,如壓力、不良飲食和缺乏運動,也可能導致痤瘡。 7. 化妝品和保養品:某些化妝品和保養品可能會導致痤瘡,特別是那些含有刺激性成分的產品。 8. 藥物:某些藥物,如口服避孕藥,也可能導致痤瘡。 要預防痤瘡,可以採取一些措施,例如保持皮膚清潔、使用溫和的護膚品、避免過度使用化妝品和護膚品、保持健康的生活方式和飲食習慣、避免壓力和荷爾蒙變化。如果痤瘡嚴重,可能需要尋求皮膚科醫生的幫助。 |
| 臉上長青春痘怎麼辦,能吃啥藥,需要注意啥 | 青春痘,又稱痤瘡,是一種常見的皮膚病。青春痘的治療需要綜合考慮飲食、生活習慣、藥物等多個面向。以下是一些建議: 1. 飲食: * 避免高糖、高脂、高油的食物,如快餐、甜點、油炸食品等。 * 多吃新鮮蔬菜、水果、全穀類食物,以增加纖維攝入,促進腸道蠕動。 * 避免攝取過多的咖啡因、酒精、辛辣食物等刺激性食物。 2. 生活習慣: * 保持良好的作息時間,確保充足的睡眠。 * 避免長時間使用電腦、手機等電子產品,以免輻射對皮膚造成刺激。 * 保持肌膚清潔,每天早晚使用溫和的潔面產品清潔肌膚。 * 避免擠壓青春痘,以免感染和留下疤痕。 3. 藥物: * 外用藥物:可使用含有水楊酸、苯甲酸、壬二酸等成分的保養品,幫助去除皮膚表面的角質,減少痘痘的形成。 * 口服藥物:如果青春痘嚴重,可以考慮口服抗生素、維生素B族、鋅等藥物,但需在醫師指導下使用。 4. 注意: * 不要隨意使用化妝品、保養品,以免刺激肌膚。 * 不要過度清潔皮膚,以免破壞皮膚屏障。 * 保持心情舒暢,避免焦慮、憂鬱等負面情緒。 總之,青春痘的治療需要綜合考慮飲食、生活習慣、藥物等多個面向。在治療過程中,要保持耐心和信心,遵循醫生的建議,逐步改善皮膚狀況。 |
| 由於輸精管阻塞會不會導致男性不孕? ,醫生您好,我同事這幾天不開心,我問她怎麼了,她說她老公輸精管堵塞,所以一直沒孩子,不是不想要,請問輸精管堵塞會不會導致男性不孕? | 輸精管阻塞可能會導致男性不孕。輸精管是連接睪丸和尿道的一條管道,負責將精子從睪丸輸送到尿道。如果輸精管阻塞,精子就無法經由輸精管到達尿道,導致不孕。 輸精管阻塞的原因有很多,包括先天性發育異常、發炎、腫瘤、外傷等。輸精管阻塞的治療方法包括手術疏通、藥物治療等。如果輸精管阻塞嚴重,可能需要進行手術疏通。 需要注意的是,輸精管阻塞並不一定會導致不孕,因為還有其他途徑可以將精子輸送到女性體內。例如,精子可以透過附睪、前列腺等組織到達女性體內。因此,如果輸精管堵塞,建議及時就醫,尋求專業醫師的協助。 |
| 心肌梗塞能治療嗎? | 心肌梗塞是一種嚴重的疾病,如果及時治療,可以挽救生命並防止長期殘疾。治療心肌梗塞的關鍵是儘早識別和治療。 心肌梗塞的治療通常包括以下步驟: 1. 立即就醫:如果出現胸痛、呼吸急促或暈厥等症狀,立即就醫。 2. 藥物治療:醫生可能會開處方藥物,如硝酸甘油或阿斯匹靈,以幫助緩解症狀並防止進一步的損傷。 3. 溶栓治療:如果患者在到達醫院前出現心肌梗塞,醫師可能會進行溶栓治療,透過注射溶解血栓的藥物來幫助恢復血流。 4. 手術治療:如果藥物治療或血栓溶解治療無效,醫師可能會建議進行手術,如冠狀動脈繞道手術或心臟支架植入術。 5. 復健和預防:心肌梗塞的治療通常包括復健計劃,以幫助患者恢復身體功能並預防未來的心臟事件。此外,患者也應遵循醫生的建議,以降低心臟病的風險。 需要注意的是,心肌梗塞的治療取決於患者的具體情況和症狀。因此,如果您或您認識的人出現心肌梗塞症狀,請立即就醫。 |
| 怎麼讓自己精力充沛,列5點建議 | 1. 保持充足的睡眠:睡眠對於保持精力充沛至關重要。確保每晚獲得7-9小時的高品質睡眠。 2. 均衡飲食:均衡飲食對於維持能量水平至關重要。確保攝取足夠的蛋白質、碳水化合物和健康脂肪。 3. 規律運動:定期運動可以幫助提高能量水平。嘗試每天至少30分鐘的有氧運動,如散步、跑步或騎自行車。 4. 管理壓力:壓力會消耗能量,因此管理壓力對於保持精力充沛至關重要。試著找出放鬆和減壓的方法,如冥想、瑜珈或深呼吸練習。 5. 保持水分:脫水會降低能量水平。確保每天喝足夠的水,並根據需要補充水分。 |
| 寫一本春天的詩 | 春天, 是大地甦醒的季節, 是萬物復甦的季節, 是生命綻放的季節。 春天, 是陽光明媚的季節, 是鳥語花香的季節, 是綠意盎然的季節, 是希望無限的季節。 春天, 是人們歡笑的季節, 是孩子們嬉戲的季節, 是戀人相擁的季節, 是人們追求夢想的季節。 |
| 南極洲為啥沒有北極熊? | 南極洲沒有北極熊,因為北極熊生活在北極地區,而南極洲位於南半球,氣候和環境與北極地區有很大不同。南極洲的氣候非常寒冷,常年被冰雪覆蓋,而北極熊則生活在北極地區,那裡有豐富的海洋生物和陸地哺乳動物。此外,南極洲的生態系統也與北極地區不同,沒有北極熊所需的生存條件。 |


本專案僅可應用於研究目的,專案開發者不承擔任何因使用本專案(包含但不限於資料、模型、程式碼等)而導致的危害或損失。詳細請參考免責聲明。
MedicalGPT專案代碼的授權協議為The Apache License 2.0,程式碼可免費用做商業用途,模型權重和資料只能用於研究目的。請在產品說明中附加MedicalGPT的連結和授權協議。
如果你在研究中使用了MedicalGPT,請按以下格式引用:
@misc{MedicalGPT,
title={MedicalGPT: Training Medical GPT Model},
author={Ming Xu},
year={2023},
howpublished={ url {https://github.com/shibing624/MedicalGPT}},
}項目代碼還很粗糙,如果大家對程式碼有所改進,歡迎提交回本項目,在提交之前,請注意以下兩點:
tests中加入對應的單元測試python -m pytest來運行所有單元測試,確保所有單測都是通過的之後即可提交PR。
Thanks for their great work!


