T2M GPT
1.0.0
論文“T2M-GPT:通過離散表示的文本描述生成人體運動”的 Pytorch 實現
[專案頁] [論文] [筆記本示範] [HuggingFace] [太空示範] [T2M-GPT+]

如果我們的專案對您的研究有幫助,請考慮引用:
@inproceedings{zhang2023generating,
title={T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations},
author={Zhang, Jianrong and Zhang, Yangsong and Cun, Xiaodong and Huang, Shaoli and Zhang, Yong and Zhao, Hongwei and Lu, Hongtao and Shen, Xi},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2023},
}
| 文字:一名男子向前跨出並倒立。 | ||||
|---|---|---|---|---|
| GT | T2M | 主資料管理 | 運動漫反射 | 我們的 |
 | 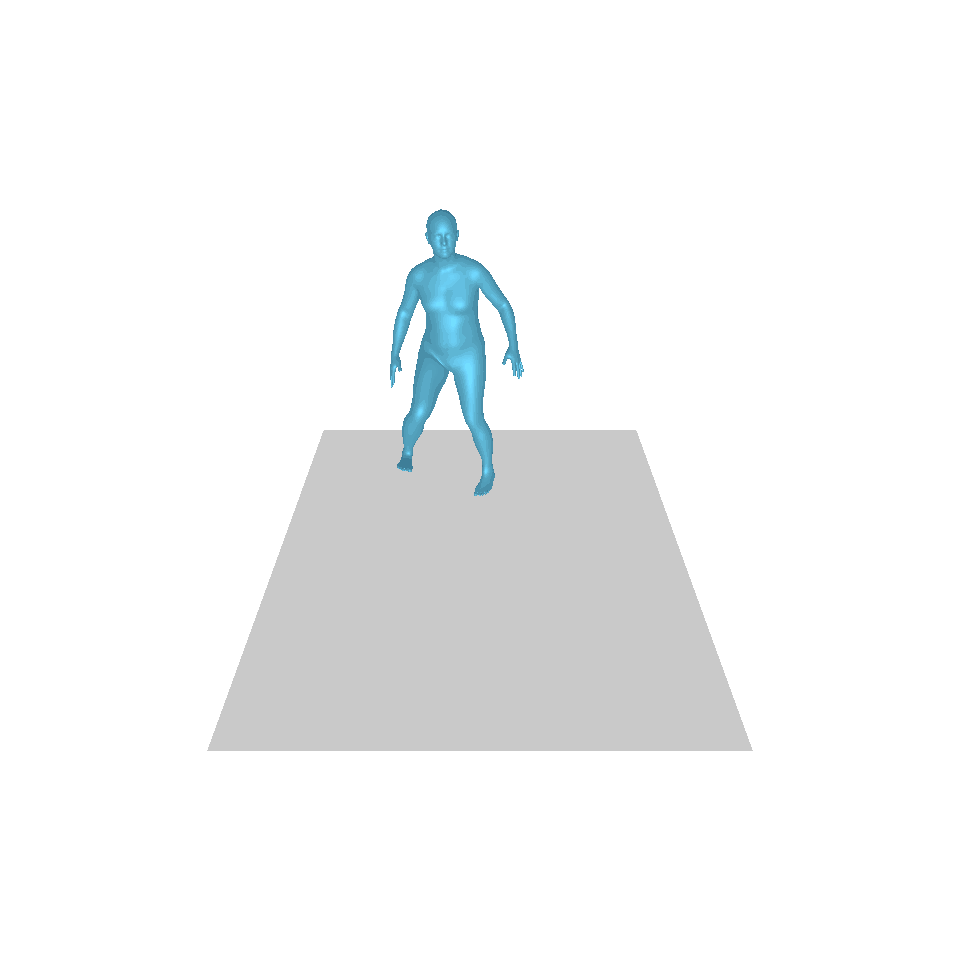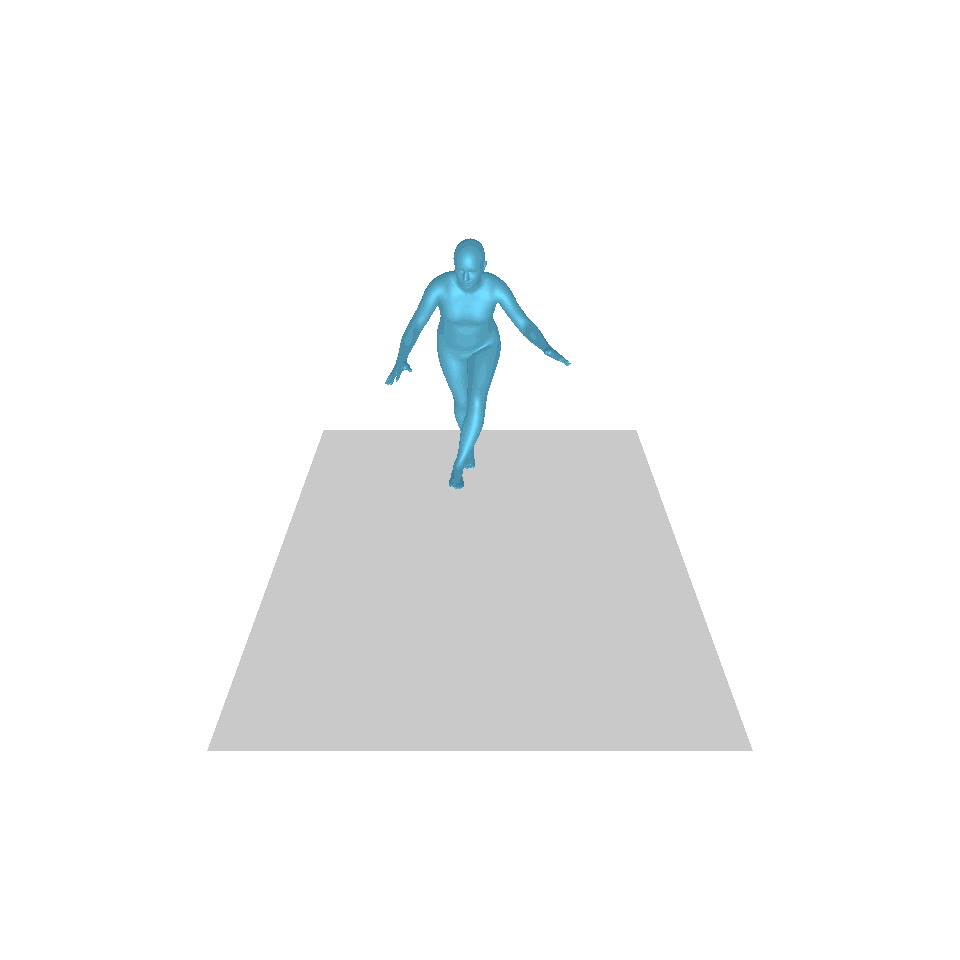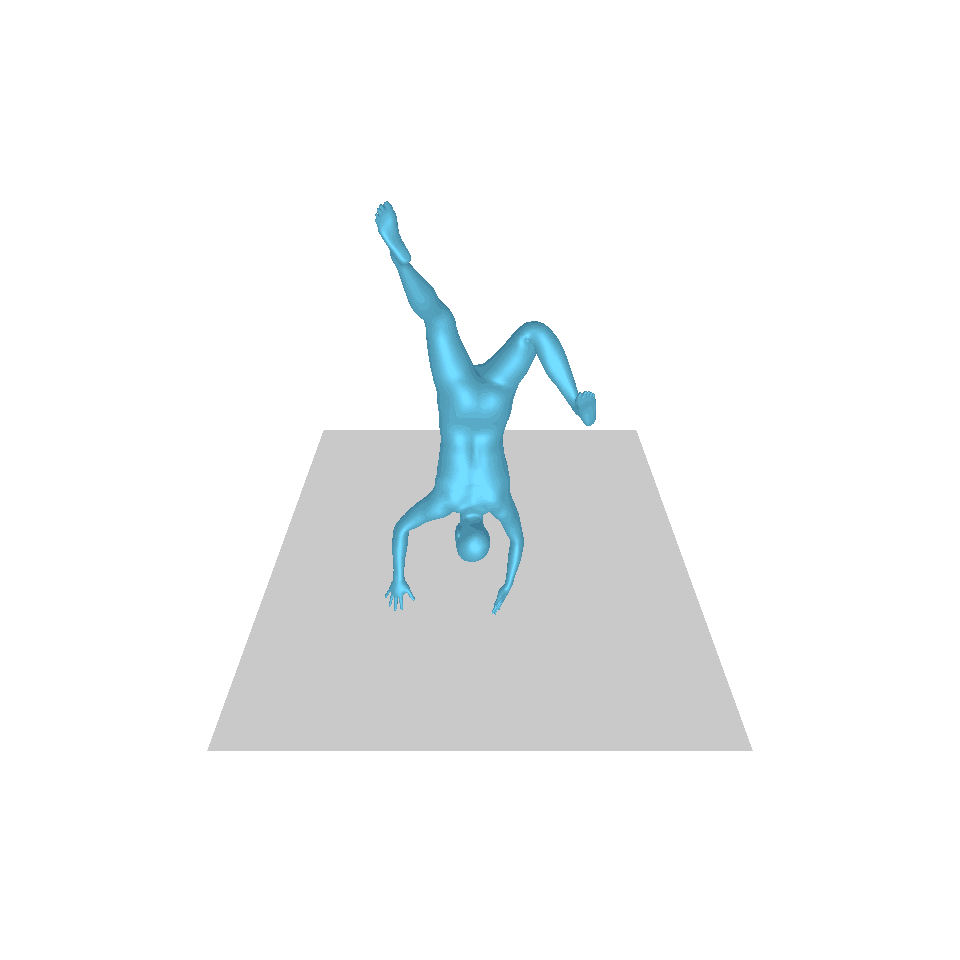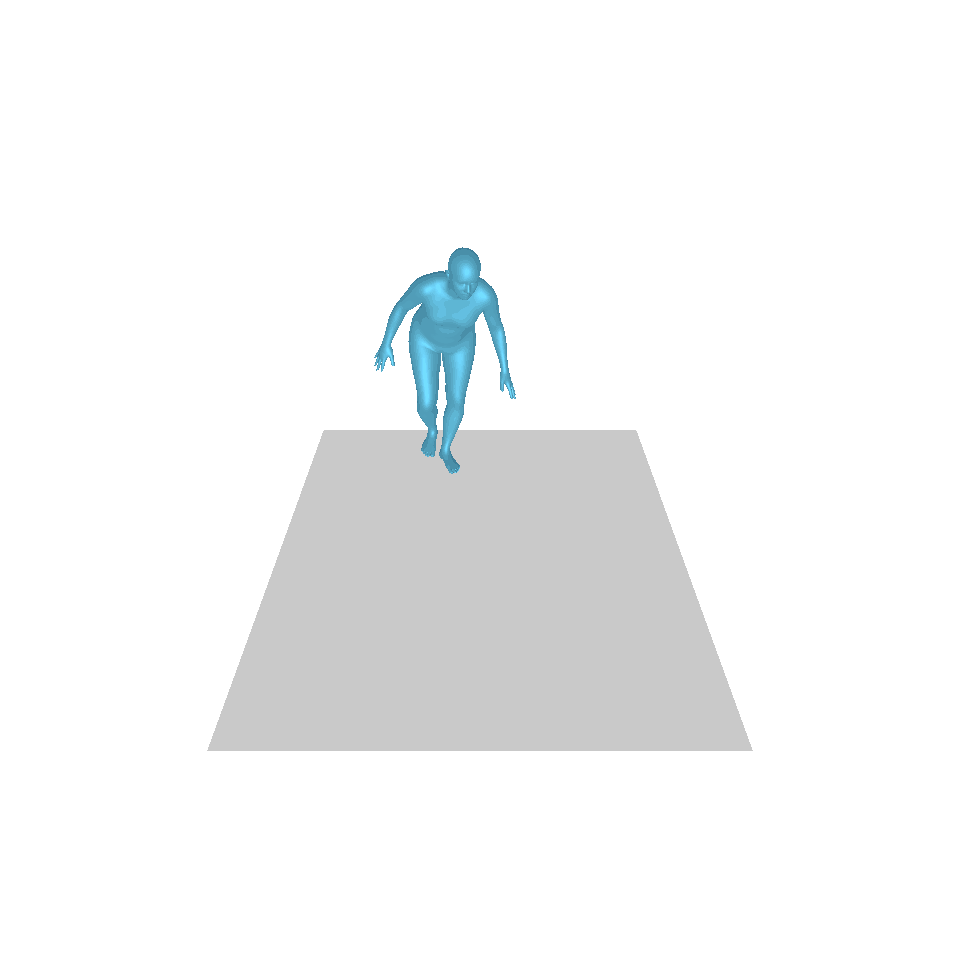 |  | 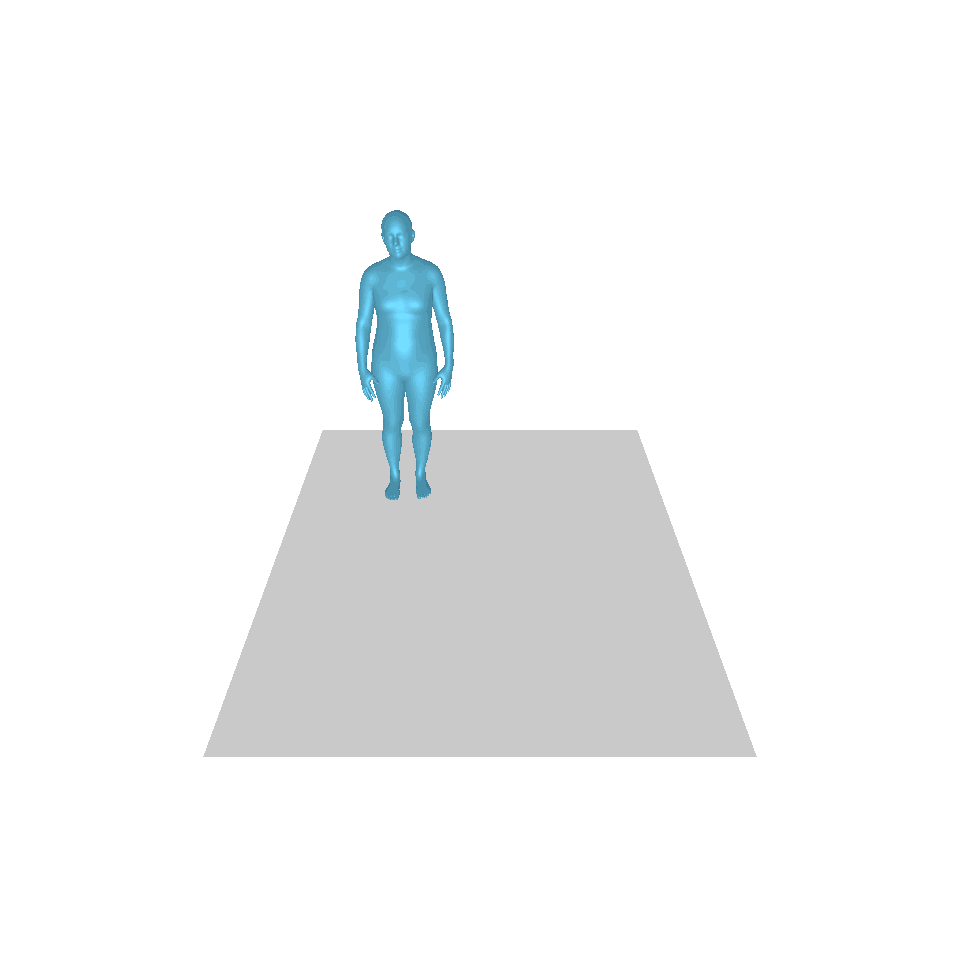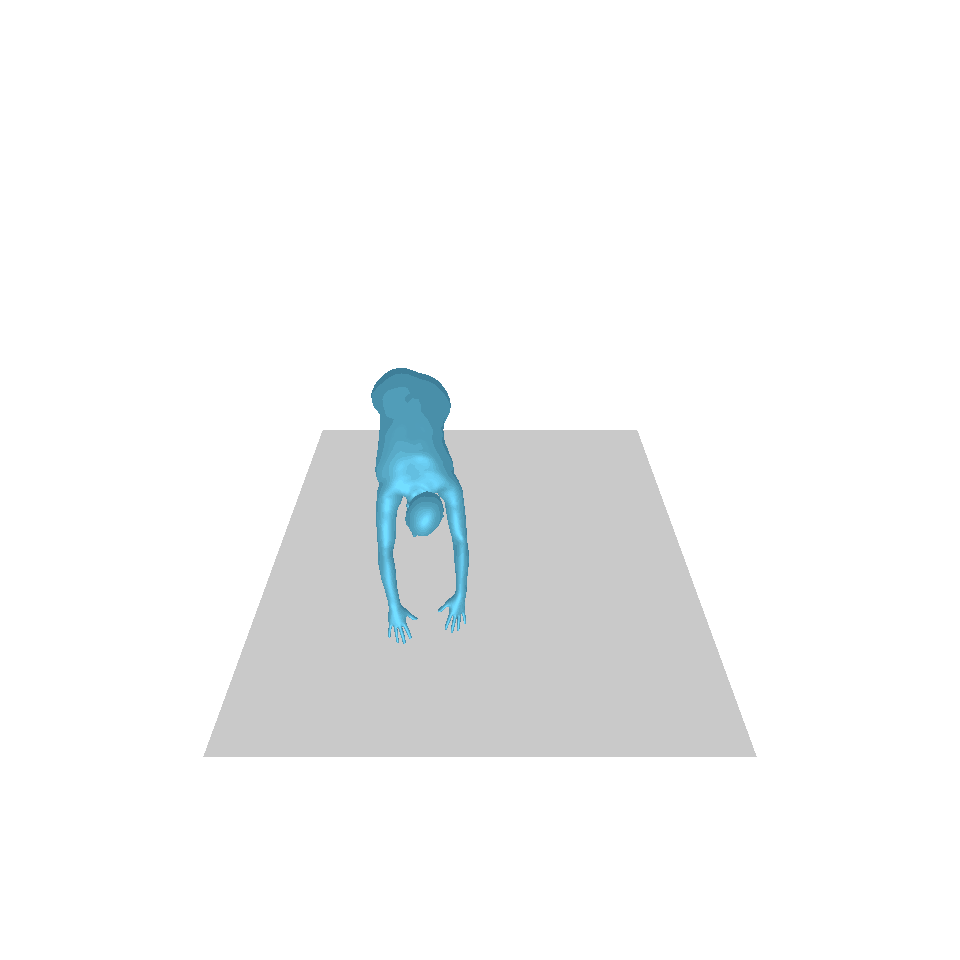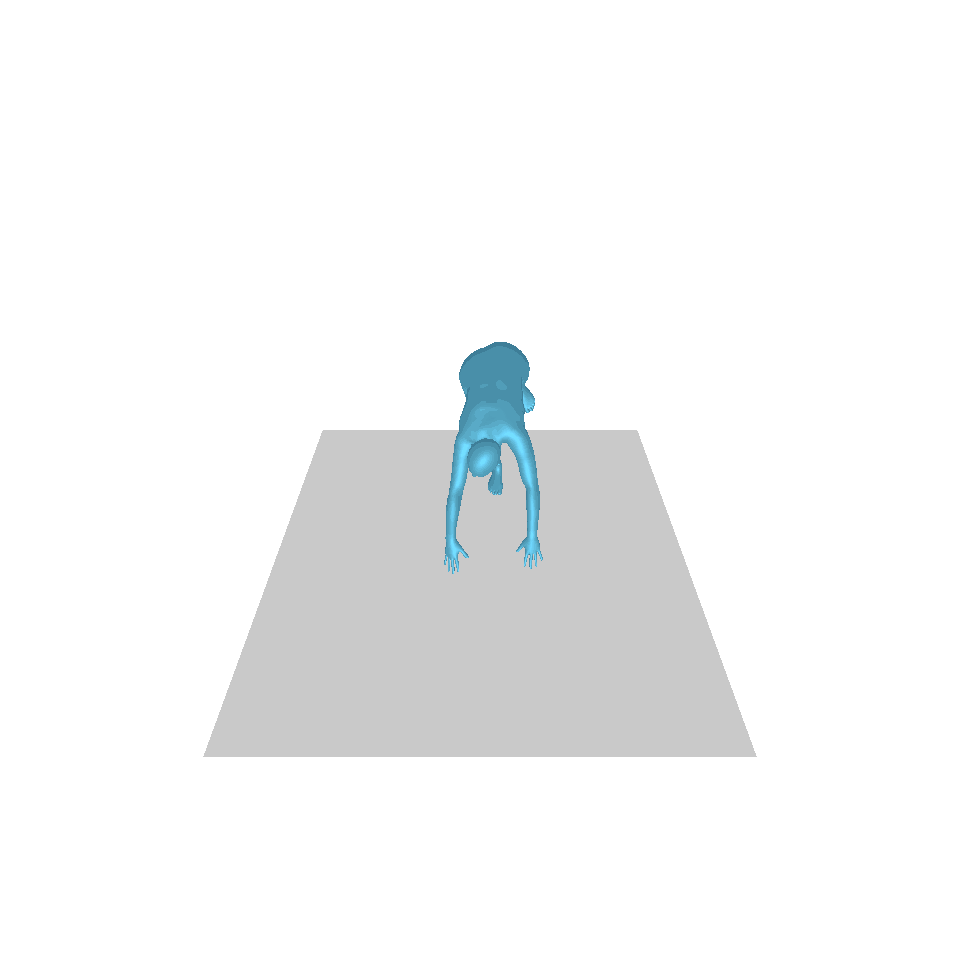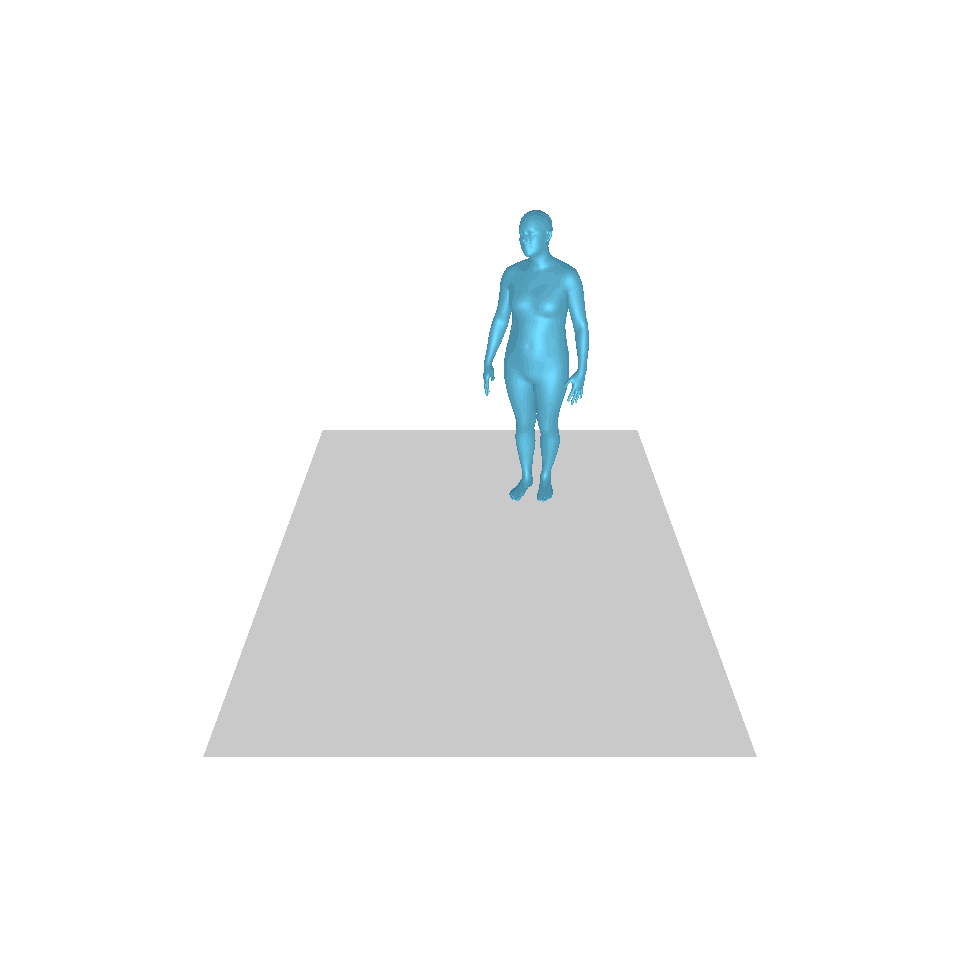 | 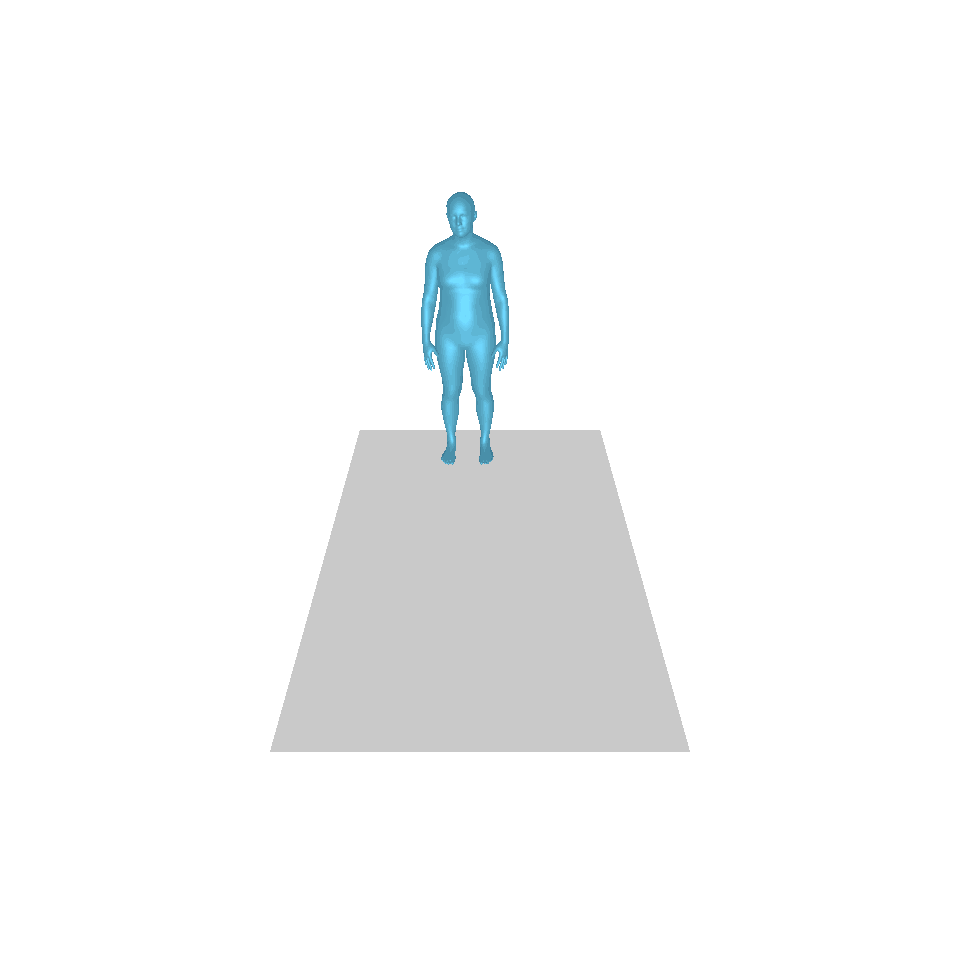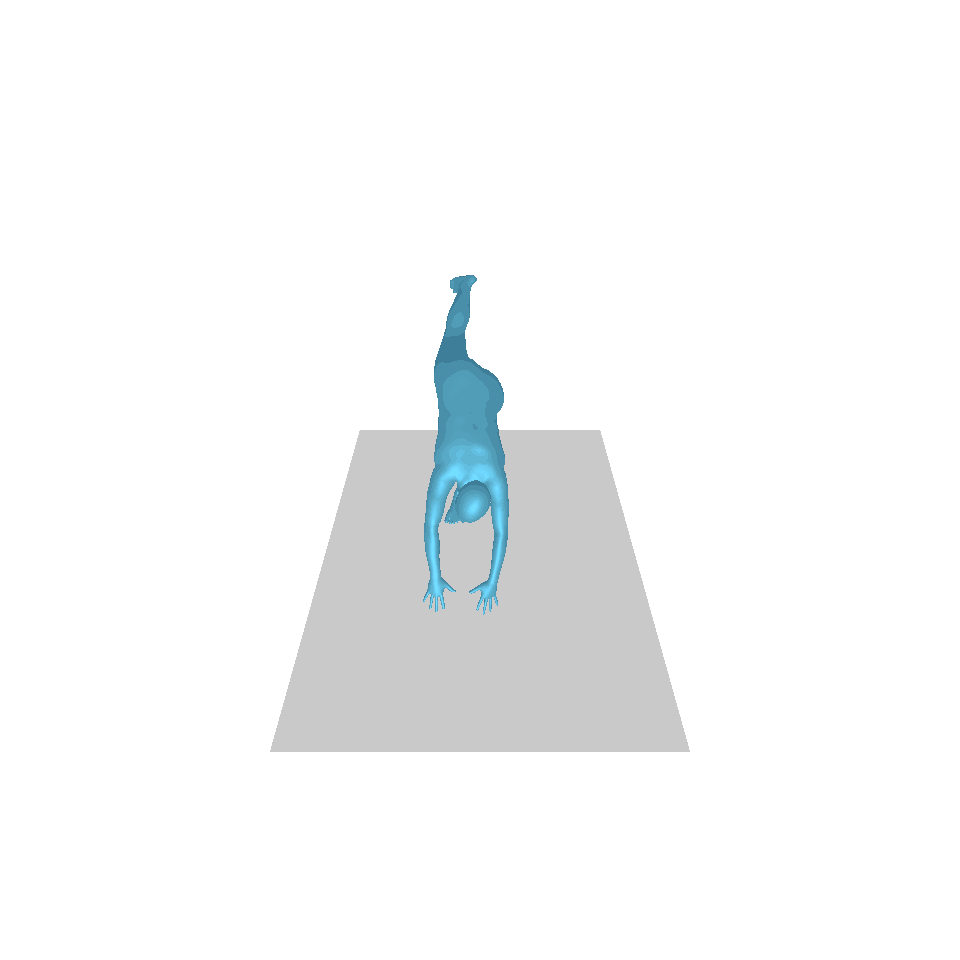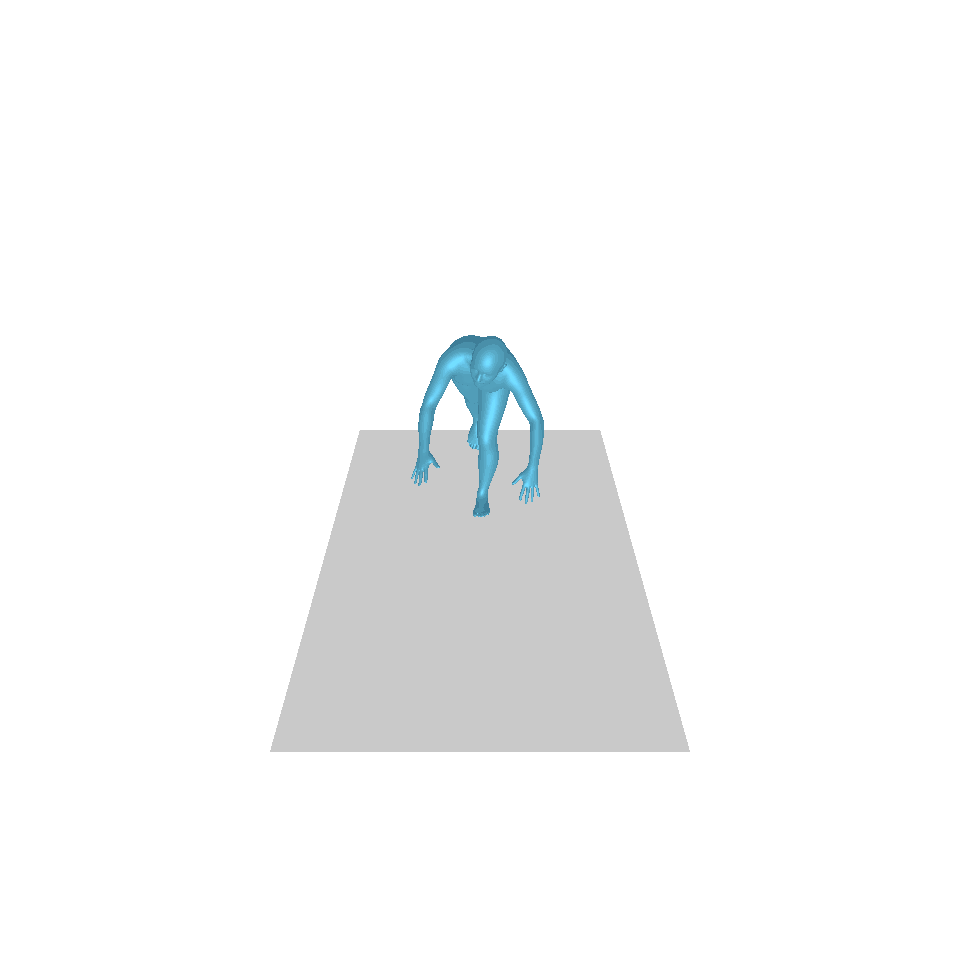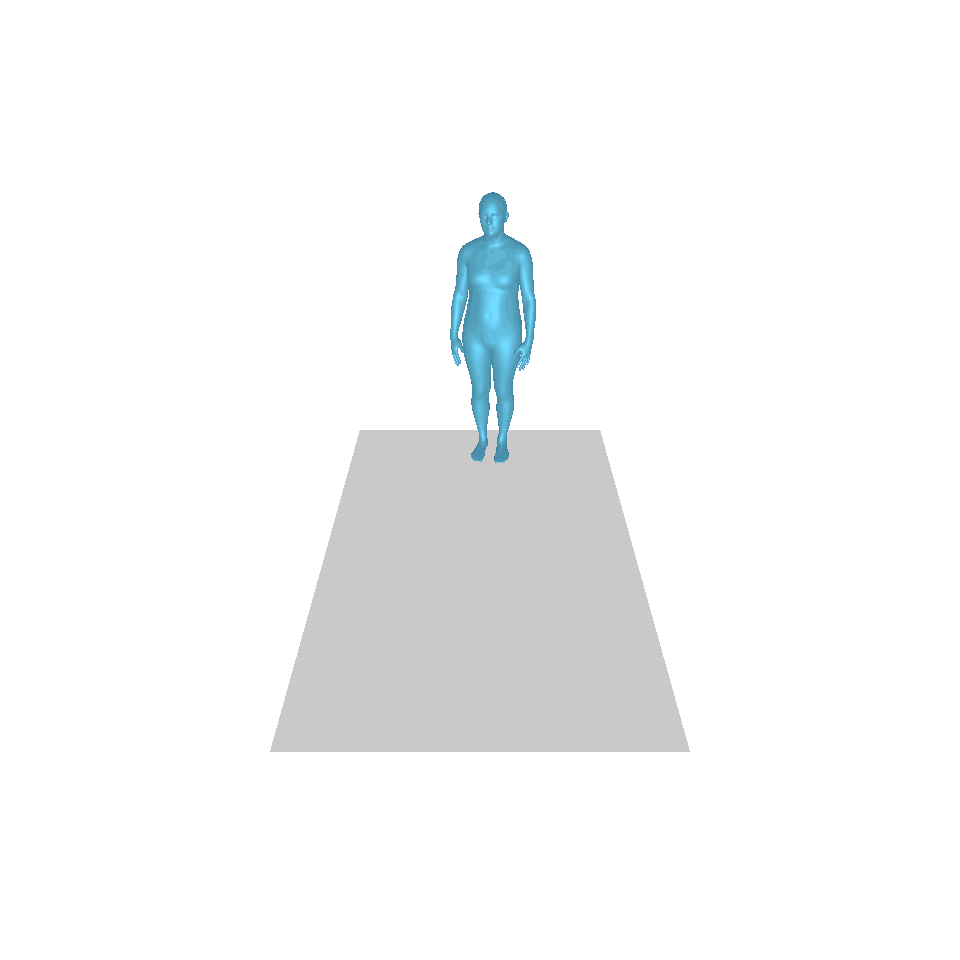 |
| 文:一個人從地上站起來,繞了一圈,然後坐回地上。 | ||||
| GT | T2M | 主資料管理 | 運動漫反射 | 我們的 |
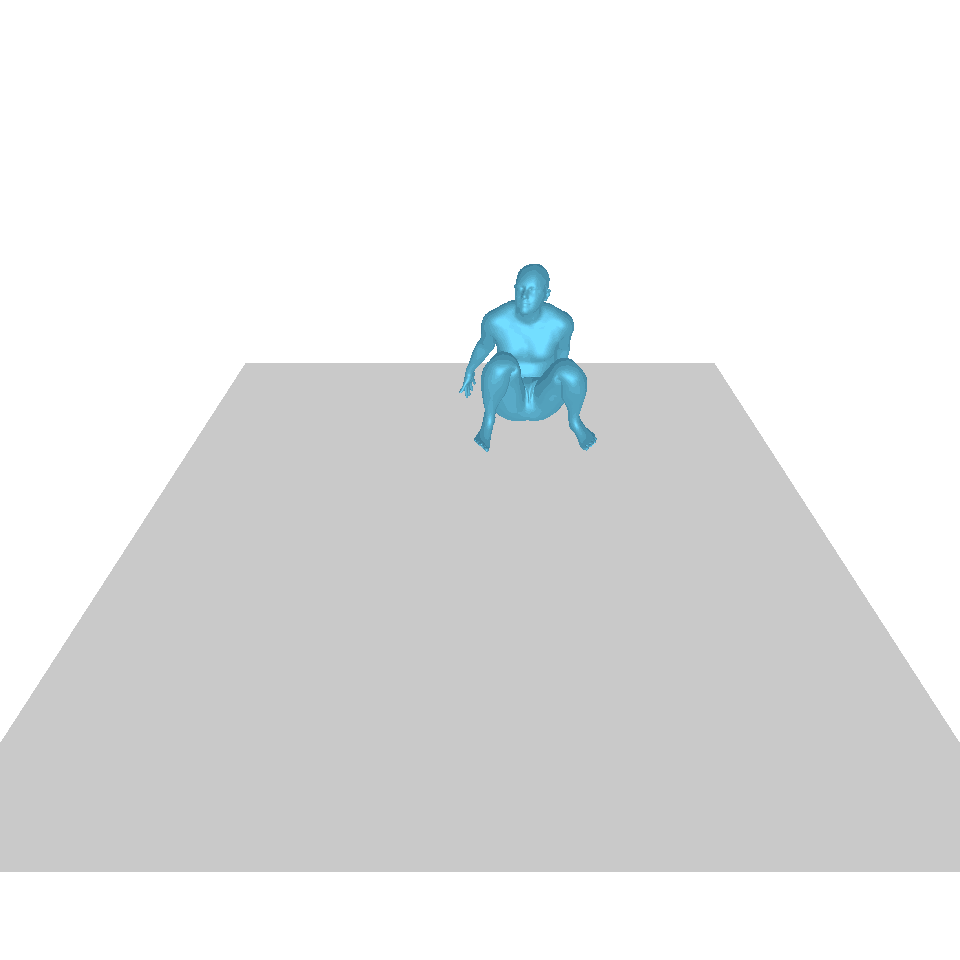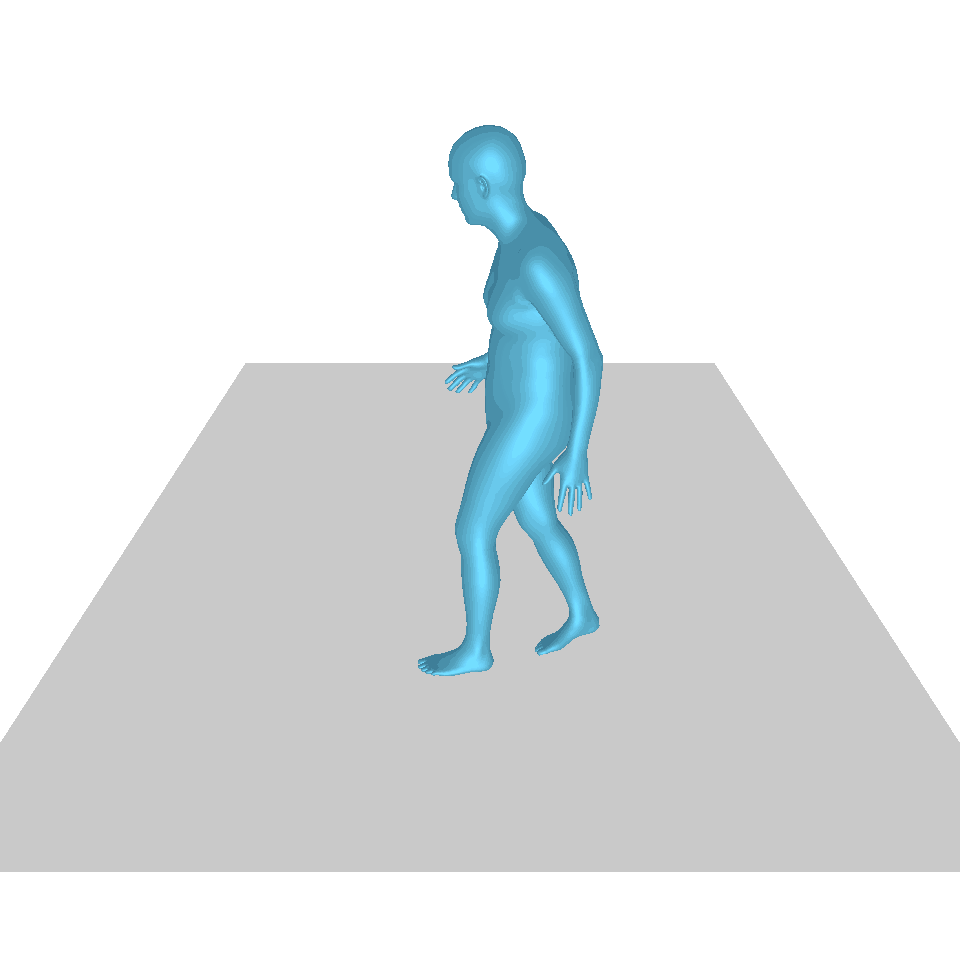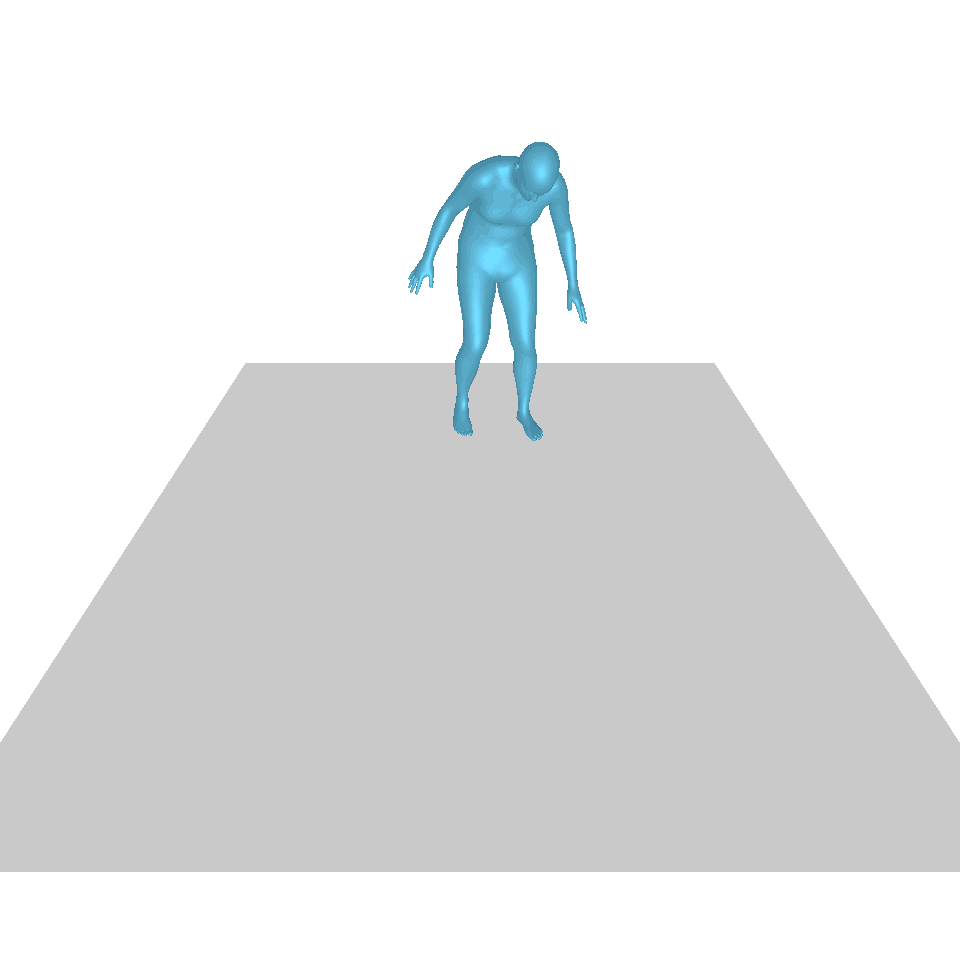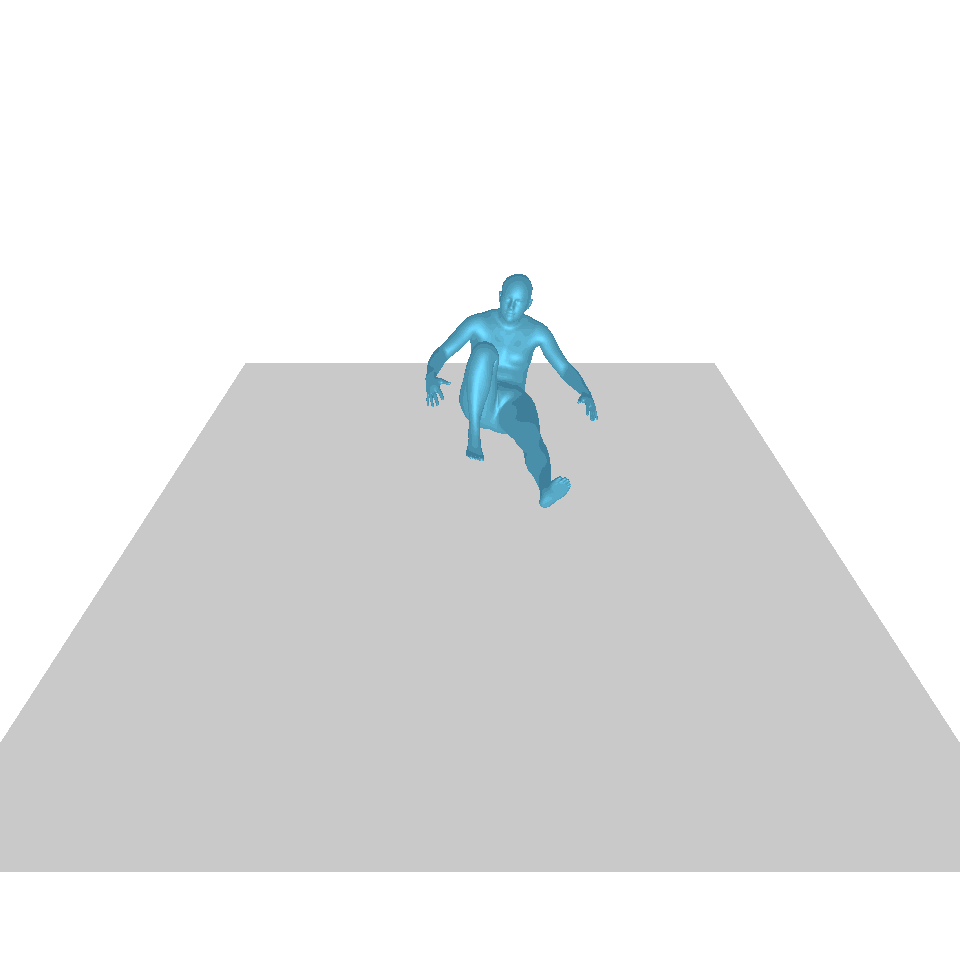 | 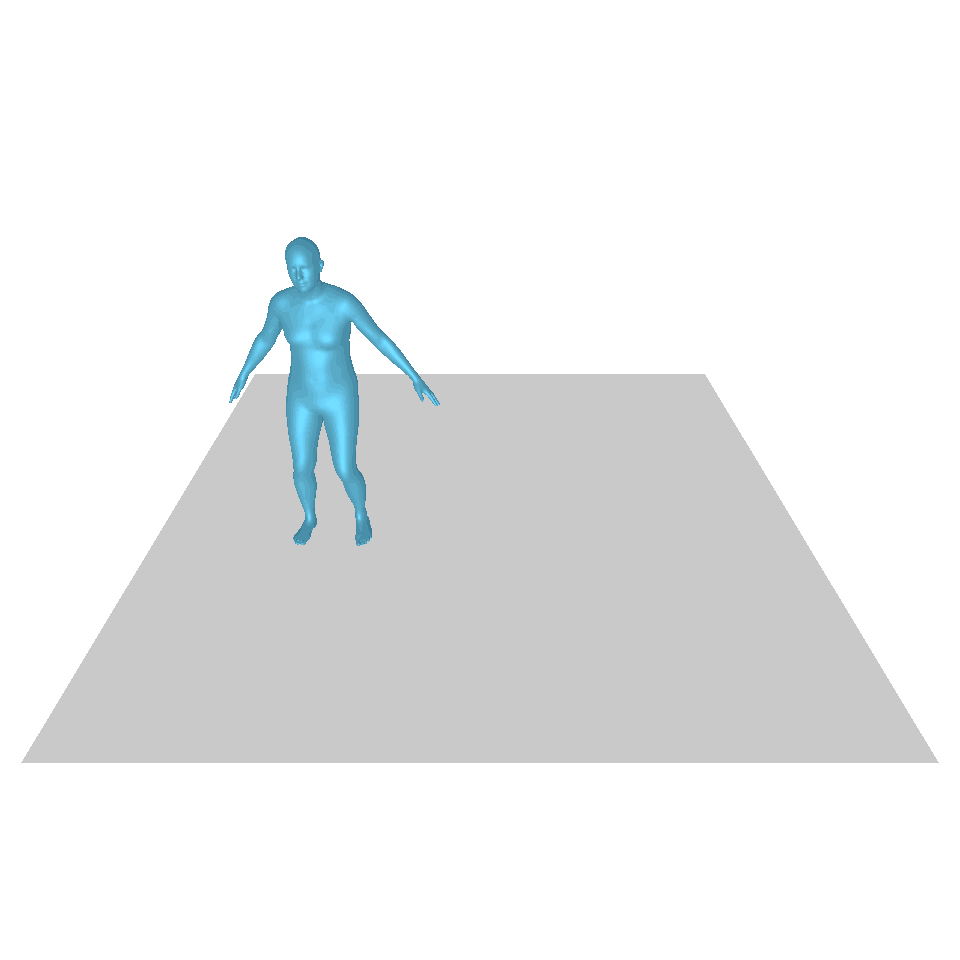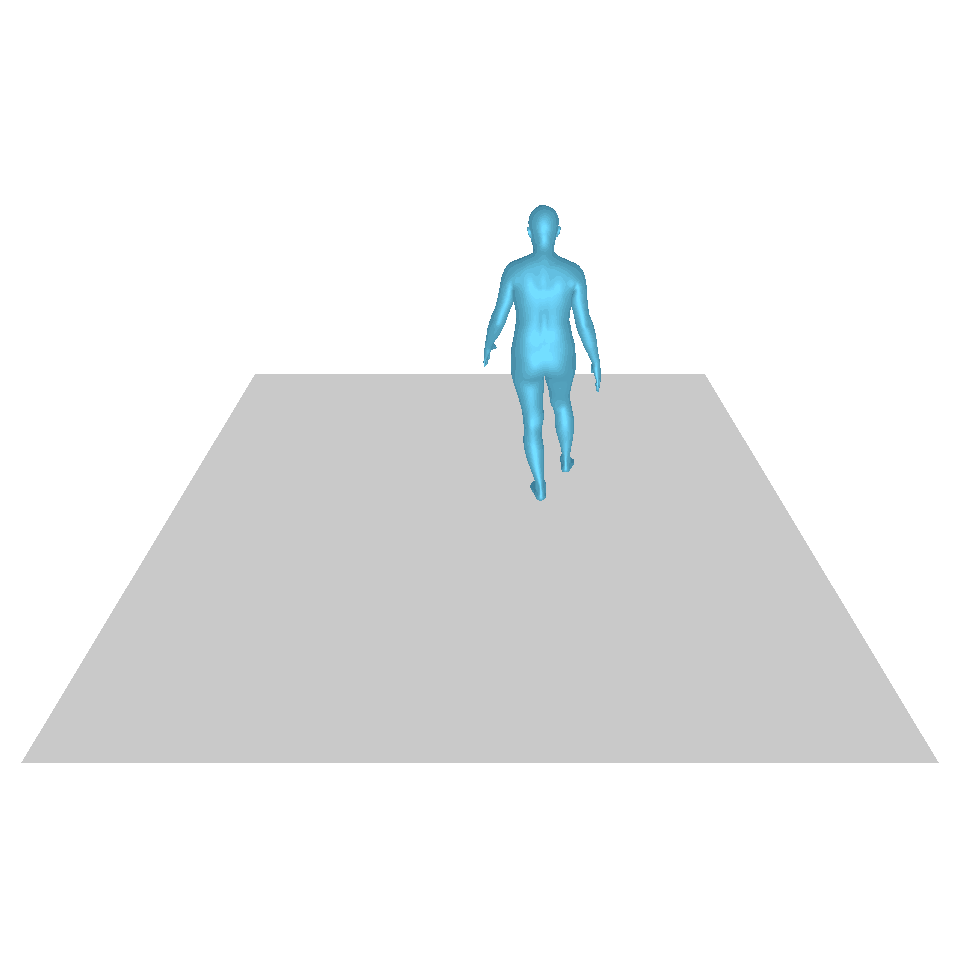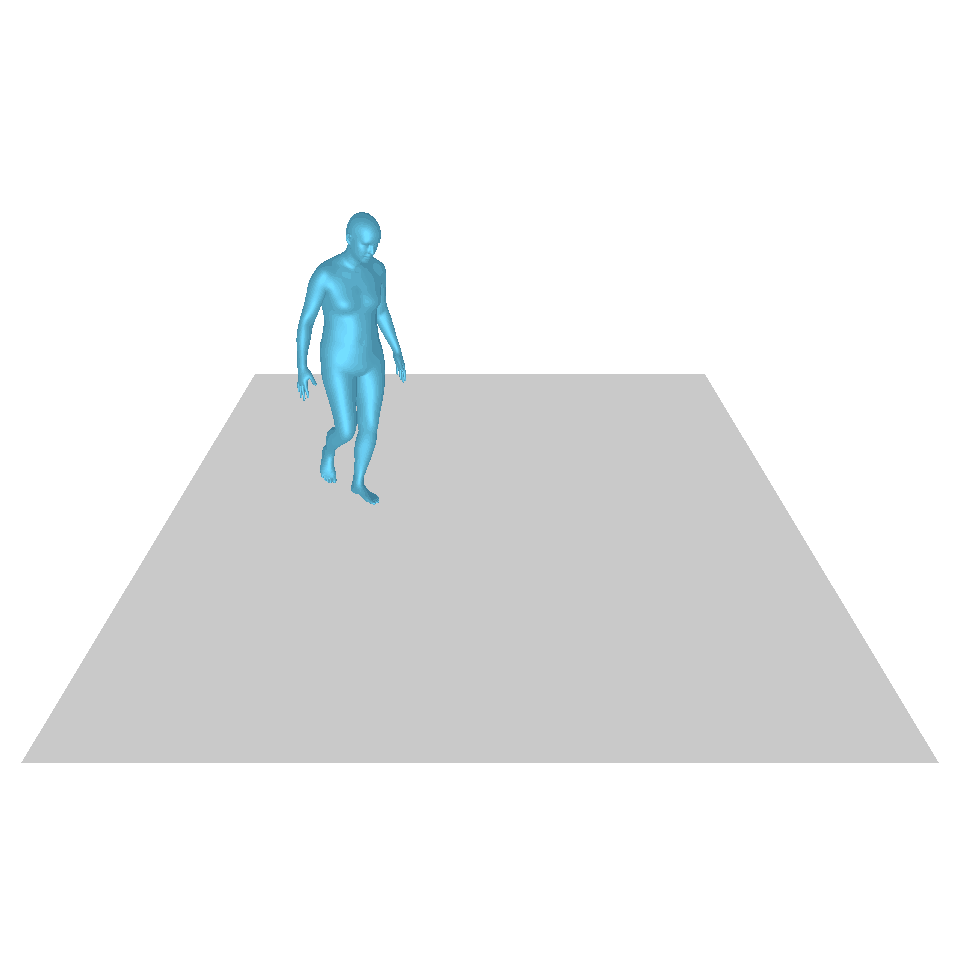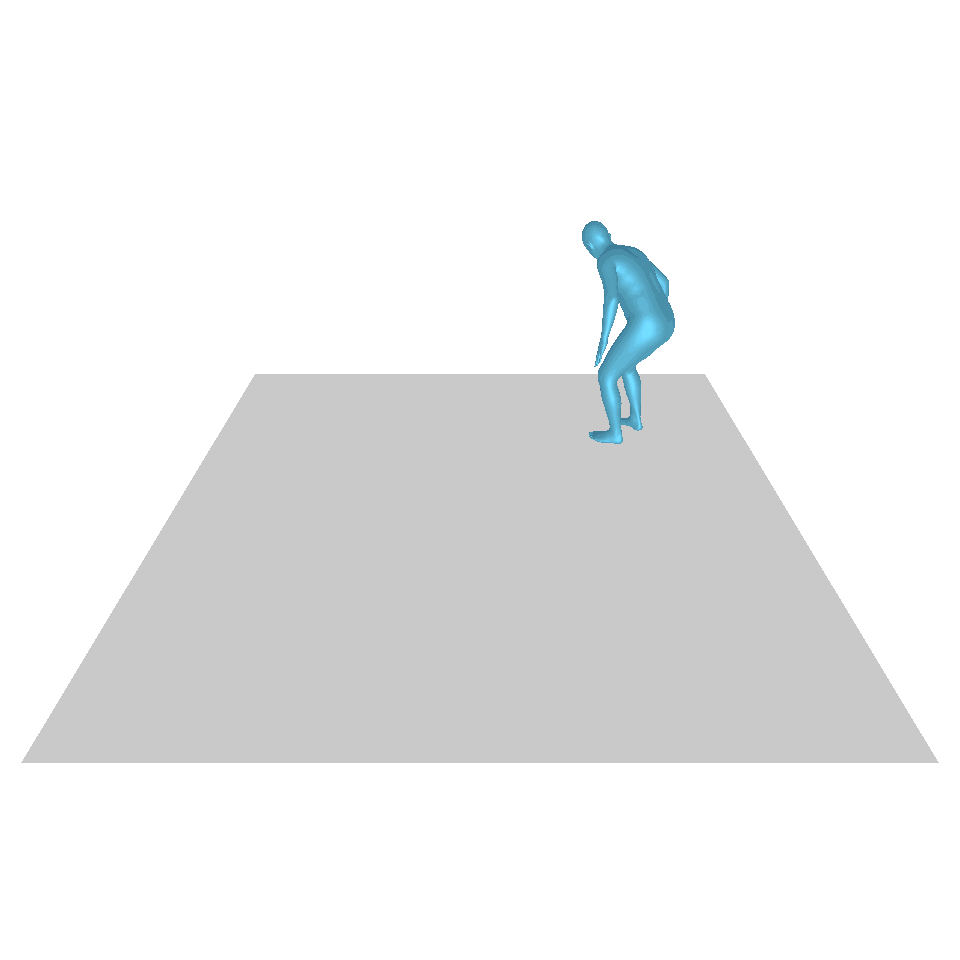 | 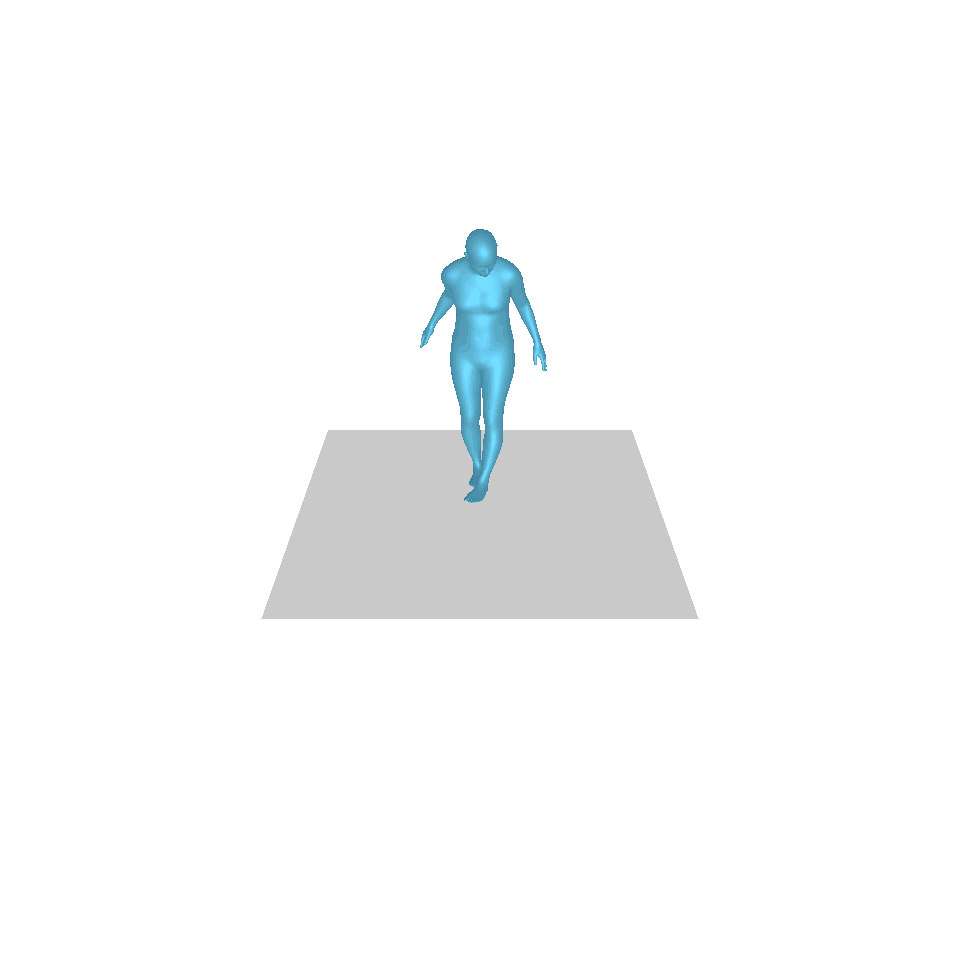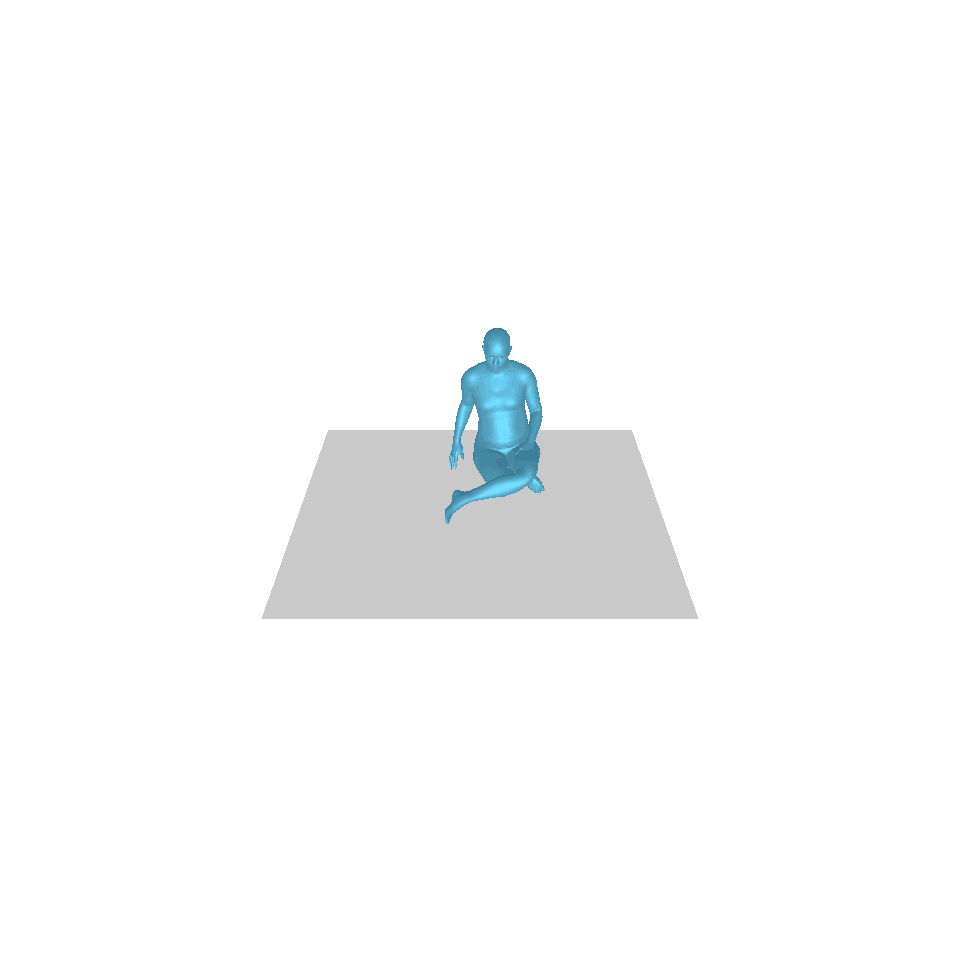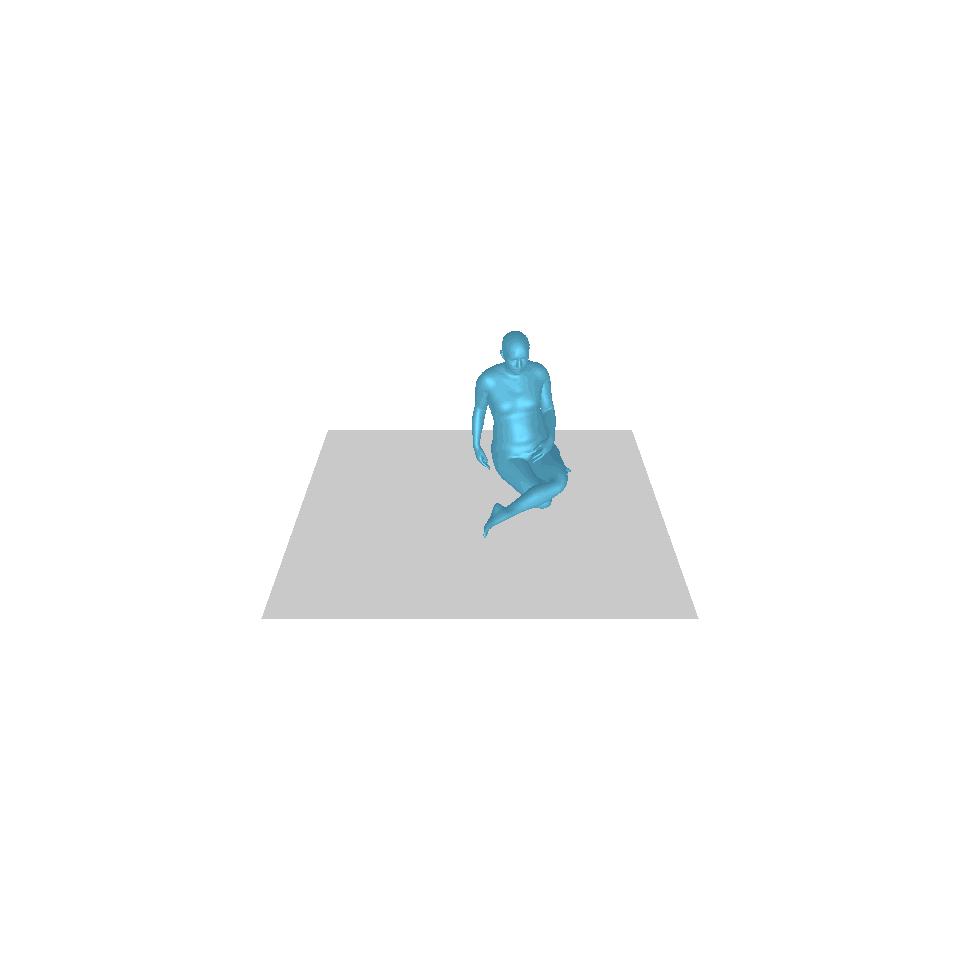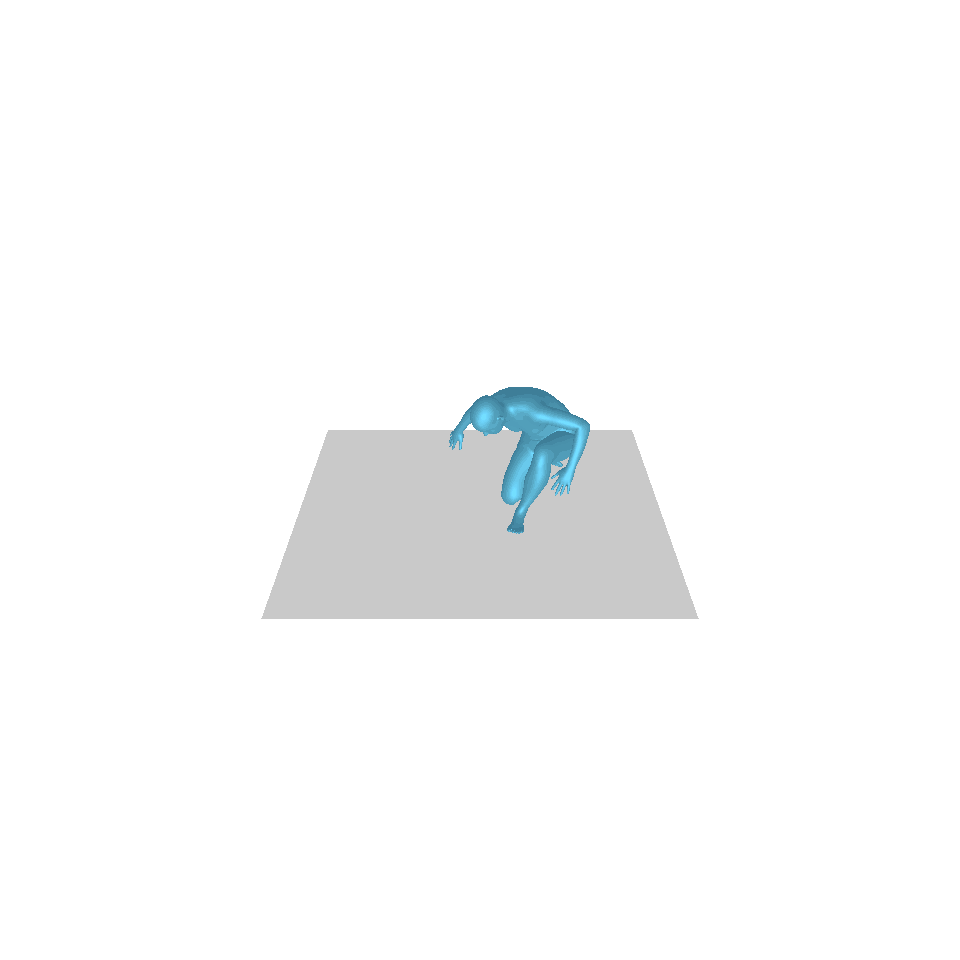 |  |  |
我們的模型可以在單一 GPU V100-32G中學習
conda env create -f environment.yml
conda activate T2M-GPT程式碼在 Python 3.8 和 PyTorch 1.8.1 上進行了測試。
bash dataset/prepare/download_glove.sh我們使用兩個 3D 人體動作語言資料集:HumanML3D 和 KIT-ML。對於這兩個資料集,您可以在[此處]找到詳細資訊以及下載連結。
以HumanML3D為例,檔案目錄應如下圖所示:
./dataset/HumanML3D/
├── new_joint_vecs/
├── texts/
├── Mean.npy # same as in [HumanML3D](https://github.com/EricGuo5513/HumanML3D)
├── Std.npy # same as in [HumanML3D](https://github.com/EricGuo5513/HumanML3D)
├── train.txt
├── val.txt
├── test.txt
├── train_val.txt
└── all.txt
我們使用 t2m 提供的相同提取器來評估我們產生的運動。請下載提取器。
bash dataset/prepare/download_extractor.sh預先訓練的模型檔案將儲存在「pretrained」資料夾中:
bash dataset/prepare/download_model.sh如果你想渲染生成的運動,你需要安裝:
sudo sh dataset/prepare/download_smpl.sh
conda install -c menpo osmesa
conda install h5py
conda install -c conda-forge shapely pyrender trimesh mapbox_earcutdemo.ipynb 提供如何使用我們的程式碼的快速入門指南
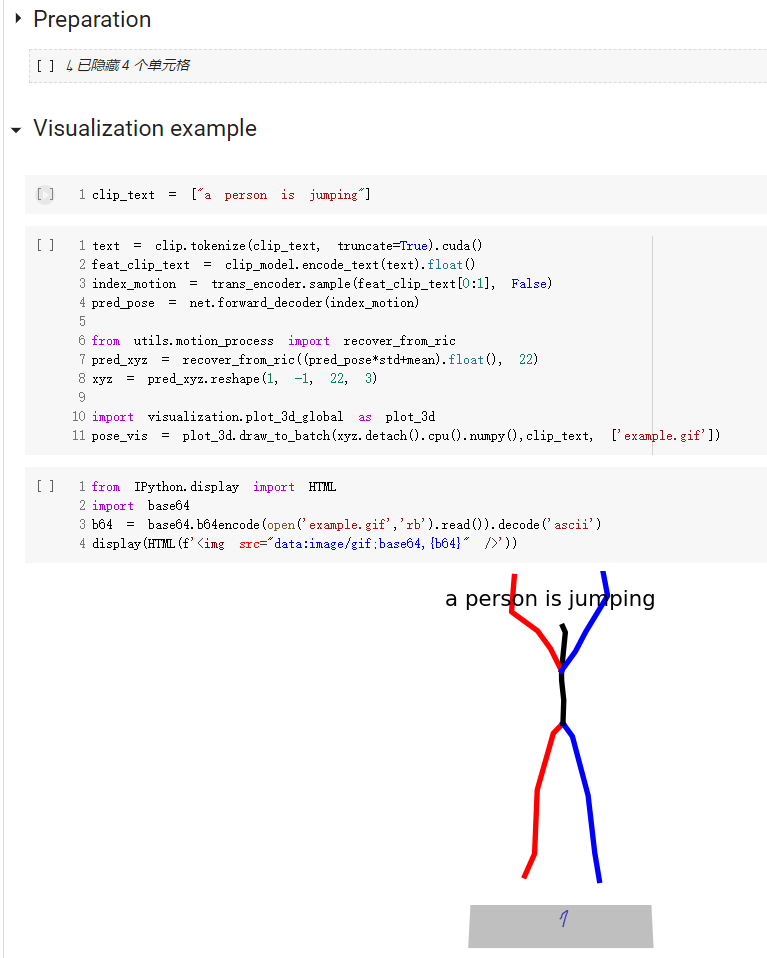
請注意,對於kit資料集,只需要設定'--dataname kit'。
結果保存在輸出資料夾中。
python3 train_vq.py
--batch-size 256
--lr 2e-4
--total-iter 300000
--lr-scheduler 200000
--nb-code 512
--down-t 2
--depth 3
--dilation-growth-rate 3
--out-dir output
--dataname t2m
--vq-act relu
--quantizer ema_reset
--loss-vel 0.5
--recons-loss l1_smooth
--exp-name VQVAE結果保存在輸出資料夾中。
python3 train_t2m_trans.py
--exp-name GPT
--batch-size 128
--num-layers 9
--embed-dim-gpt 1024
--nb-code 512
--n-head-gpt 16
--block-size 51
--ff-rate 4
--drop-out-rate 0.1
--resume-pth output/VQVAE/net_last.pth
--vq-name VQVAE
--out-dir output
--total-iter 300000
--lr-scheduler 150000
--lr 0.0001
--dataname t2m
--down-t 2
--depth 3
--quantizer ema_reset
--eval-iter 10000
--pkeep 0.5
--dilation-growth-rate 3
--vq-act relupython3 VQ_eval.py
--batch-size 256
--lr 2e-4
--total-iter 300000
--lr-scheduler 200000
--nb-code 512
--down-t 2
--depth 3
--dilation-growth-rate 3
--out-dir output
--dataname t2m
--vq-act relu
--quantizer ema_reset
--loss-vel 0.5
--recons-loss l1_smooth
--exp-name TEST_VQVAE
--resume-pth output/VQVAE/net_last.pth按照文字到動作的評估設置,我們評估我們的模型 20 次並報告平均結果。由於多模態部分我們需要從同一文本產生 30 個動作,因此評估需要很長時間。
python3 GPT_eval_multi.py
--exp-name TEST_GPT
--batch-size 128
--num-layers 9
--embed-dim-gpt 1024
--nb-code 512
--n-head-gpt 16
--block-size 51
--ff-rate 4
--drop-out-rate 0.1
--resume-pth output/VQVAE/net_last.pth
--vq-name VQVAE
--out-dir output
--total-iter 300000
--lr-scheduler 150000
--lr 0.0001
--dataname t2m
--down-t 2
--depth 3
--quantizer ema_reset
--eval-iter 10000
--pkeep 0.5
--dilation-growth-rate 3
--vq-act relu
--resume-trans output/GPT/net_best_fid.pth您應該輸入 npy 資料夾位址和動作名稱。這是一個例子:
python3 render_final.py --filedir output/TEST_GPT/ --motion-list 000019 005485我們感謝以下人員的協助:


