spelltest
v0.0.4
?如果您覺得這個項目有用,請考慮給它一顆星!您的支持是我不斷進步的動力! ?
當今的人工智慧驅動的應用程式在很大程度上依賴 GPT-4 等大型語言模型 (LLM) 來提供創新的解決方案。然而,確保他們在每種情況下都能提供相關且準確的回應是一項挑戰。 Spelltest 透過使用合成使用者角色模擬 LLM 回應以及自動評估這些回應的評估技術(但仍需要人工監督)來解決這個問題。
spellforge.yaml檔案中描述你的模擬: project_name : ...
# describe users
users :
...
# describe quality metrics
metrics :
...
# describe prompts of your LLM app
prompts :
...
# finally describe simulations
simulations :
...

現在您可以透過 Google Colab 在基於網路的互動環境中嘗試這個專案!無需安裝。
只需點擊上面的徽章即可開始!
有保證的品質:模擬使用者互動以獲得最佳回應。
效率和節省:節省手動測試成本。
流暢的工作流程整合:無縫融入您的開發流程。
請注意,這是拼字測驗的早期版本。因此,它尚未在不同的環境和用例中進行廣泛的測試。決定使用此版本即表示您接受使用 Spelltest 框架並自行承擔風險。我們強烈鼓勵使用者報告他們遇到的任何問題或錯誤,以協助改進專案。
關於營運成本,需要注意的是,使用 Spelltest 運行模擬會根據 OpenAI API 的使用情況產生費用。目前沒有成本估算或預算限制。就上下文而言,運行一批 100 個模擬可能花費約 0.7 到 1.8 美元 (gpt-3.5-turbo),具體取決於包括特定 LLM 和模擬複雜性在內的多個因素。
考慮到這些成本,我們強烈建議從少量的模擬開始,這既可以降低初始成本,又可以幫助您更好地估計未來的費用。隨著您更加熟悉框架及其成本影響,您可以根據您的預算和需求調整模擬數量。
請記住,Spelltest 的目標是確保 LLM 提供高品質的回應,同時在 AI 開發和測試過程中盡可能保持成本效益。

Spelltest 採用獨特的品質保證方法。透過使用合成使用者角色,我們不僅可以模擬交互,還可以捕捉獨特的使用者期望,為測試提供豐富的上下文環境。這種背景深度使我們能夠以密切反映現實世界應用的方式評估法學碩士回答的品質。
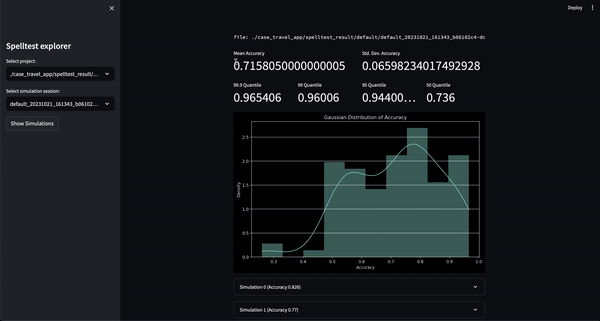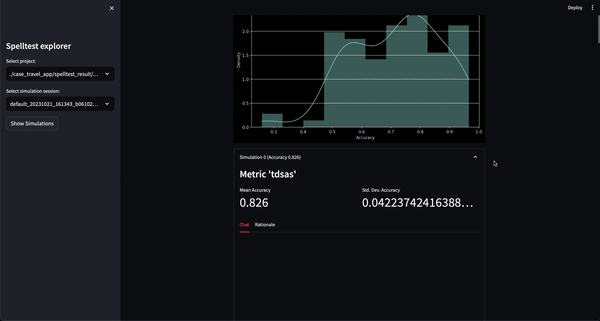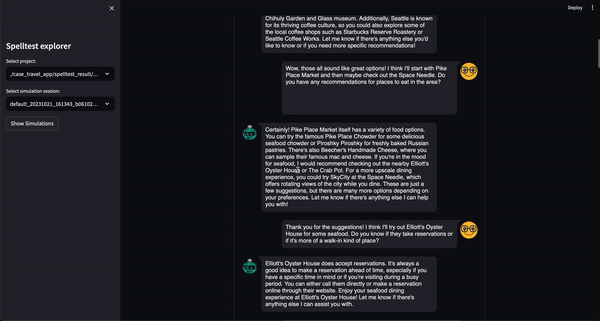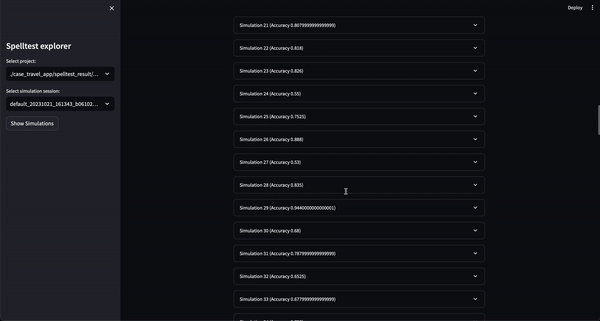
結果呢?品質分數範圍從 0.0 到 1.0,充當您的應用程式在與真實用戶見面之前的全面彩排。無論是在聊天或完成模式下,Spelltest 都能確保 LLM 回應與使用者期望緊密結合,從而提高整體使用者滿意度。
使用 pip 安裝框架:
pip install spelltest.spellforge.yaml是 Spelltest 的核心,包含綜合使用者設定檔、指標、提示和模擬。下面是其結構的細分:
合成用戶模仿現實世界的用戶,每個用戶都有獨特的背景、期望和對應用程式的理解。合成用戶的配置包括:
子提示:這些是為使用者設定檔提供上下文的描述性元素。它們包括:
description :關於合成使用者的簡介。expectation :使用者對互動的期望。user_knowledge_about_app :對應用程式的熟悉程度。每個合成用戶還有一個:
name :合成使用者的識別碼。llm_name :要使用的 LLM 模型(僅在 OpenAI 模型上測試)。temperature : ...綜合用戶設定範例:
...
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
...指標用於評估法學碩士的回答並對其進行評分。每個指標包含一個子提示description ,提供有關指標評估內容的上下文。
簡單指標配置範例:
...
metrics :
accuracy :
description : " Accuracy "
...複雜/自訂指標配置範例:
...
metrics :
tpas :
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
...提示是應用程式提出的問題或任務。這些用於模擬,以測試法學碩士產生合適回應的能力。每個提示都定義有description和實際的prompt文字或任務。
...
prompts :
book_flight :
file : book-flight-prompt.txt
...模擬指定測試場景。關鍵元素包括prompt 、 users 、 llm_name 、 temperature 、 size 、 chat_mode和quality_threshold 。
project_name : " Travel schedule app "
# describe users
users :
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
family_weekend :
name : " The Adventurous Family from Chicago "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a family of four (two adults and two children) based in Chicago looking to plan an exciting, yet relaxed weekend getaway outside the city. The objective is to explore a new environment that is kid-friendly and offers a mix of adventure and downtime. "
expectation : " A balanced travel schedule that combines fun activities suitable for children and relaxation opportunities for the entire family, considering travel times and kid-friendly amenities. "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
retired_couple :
name : " Retired Couple Exploring Berlin "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a retired couple from the US, wanting to explore Berlin and soak in its rich history and culture over a 10-day vacation. You’re looking for a mixture of sightseeing, cultural experiences, and leisure activities, with a comfortable pace suitable for your age. "
expectation : " A comprehensive travel plan that provides a relaxed pace, ensuring enough time to explore and enjoy each location, and includes historical and cultural experiences. It should also consider comfort and accessibility. "
user_knowledge_about_app : " The app accepts text input detailing travel requirements (i.e., destination, preferences, duration, and a brief description of travelers) and returns a well-organized travel itinerary tailored to those specifics. "
metrics : __all__
# describe quality metrics
metrics :
tpas : # name of your metric
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
# describe prompts
prompts :
smart-prompt :
file : ./smart-prompt # expected that prompt located in this file
# finally describe simulations
simulations :
test1 :
prompt : smart-prompt
users : __all__
llm_name : gpt-3.5-turbo
temperature : 0.7
size : 5
chat_mode : true # completion mode if `false`
quality_threshold : 80
帶有提示文件的完整配置在這裡。
OpenAI 成本:使用此框架可能會導致對 OpenAI 的大量請求,特別是在執行大量模擬時。這可能會導致您的 OpenAI 帳戶產生大量費用。確保您留意 OpenAI 預算並了解定價模型。我對由此產生的任何費用不承擔任何責任。
早期發布:此版本的 Spelltest 處於早期階段,沒有穩定性保證。請謹慎使用,並隨時提供回饋或回報問題。
export OPENAI_API_KEYS= < your api keys >
spelltest --config_file .spellforge.yaml檢查模擬結果。
spelltest --analyze將 Spelltest 整合到您的發布管道中可以透過合併一致的自動化測試來增強您的部署策略。這一關鍵步驟透過在發布之前系統地模擬和評估用戶互動來確保您的基於 LLM 的應用程式保持高品質標準。這種做法可以節省大量時間,減少手動錯誤,並提供有關更改或新功能將如何影響使用者體驗的關鍵見解。
本指南將引導您完成為專案設定和自動化持續整合的過程。
在開始之前,請確保您具備以下先決條件:
包含您的專案的 GitHub 儲存庫。
使用 API 金鑰存取 SpellForge。如果您沒有,可以從 SpellForge 網站取得。
用於使用 OpenAI 服務的 OpenAI API 金鑰。如果沒有,可以從 OpenAI 網站取得。
.spellforge.yaml在專案的根目錄中建立.spellforge.yaml檔案。該文件將包含拼字測驗的說明。
建立 GitHub Actions 工作流程文件,例如 .github/workflows/.spelltest.yaml,以自動執行 SpellForge 測試。將以下程式碼插入該文件:
# .spelltest.yaml
name : Spelltest CI
on :
push :
branches : [ "main" ]
env :
SPELLTEST_CONFIG_PATH : ${{ env.SPELLTEST_CONFIG_PATH }}
OPENAI_API_KEY : ${{ secrets.OPENAI_API_KEY }}
jobs :
test :
runs-on : ubuntu-latest
steps :
- uses : actions/checkout@v3
- name : Install SpellTest library
run : pip install spelltest
- name : Run tests
run : spelltest --config_file $SPELLTEST_CONFIG_PATH每次推送到主分支時都會觸發此工作流程,並將執行您的 SpellForge 測試。
前往 GitHub 儲存庫並導航至「設定」標籤。
在「秘密」下方新增兩個新秘密:
OPENAI_API_KEY :將此金鑰設定為您的 OpenAI API 金鑰。
新增GitHub環境變數:
SPELLTEST_CONFIG_PATH :將此變數設定為儲存庫中 .spellforge.yaml 檔案的完整路徑。
這些模擬具有特定特徵和期望的真實使用者互動。
使用者背景( .spellforge.yaml中的description欄位):一個子提示,概述了這個合成使用者是誰以及他們想要使用該應用程式解決的問題,例如,旅行者管理他們的日程安排。
使用者期望( expectation欄位):一個子提示,定義綜合使用者期望透過使用應用程式實現成功的互動或解決方案。
環境感知( user_knowledge_about_app欄位):確保綜合使用者了解應用程式上下文的子提示,確保真實的測試場景。
子提示,代表用於評估和評分 LLM 在模擬中產生的反應的標準或標準。指標的範圍可以從一般測量到更特定於應用程式的自訂指標。
一般指標範例:
語意相似度:衡量所提供的答案在意義上與預期答案的相似程度。
毒性:評估對任何可能被認為不適當或有害的語言或內容的回應。
結構相似性:將產生的反應的結構和格式與預先定義的標準或預期輸出進行比較。
更多自訂指標範例:
TPAS(旅行計劃準確度分數) :「此指標透過評估預期輸出的包含情況和建議旅行計劃的品質來衡量產生的響應的準確性。TPAS 是介於0 到100 之間的數值,其中100 代表完美與預期輸出匹配,0 表示結果不準確。
EES(同理心參與評分) :「EES 評估法學碩士回答的同理心共鳴。透過評估訊息中的理解、驗證和支持元素,對所傳達的同理心程度進行評分。EES 範圍從0 到100 ,其中100 表示高度同理心反應,而 0 表示缺乏同理心參與。
使用 Spelltest 讓您的 LLM 申請變得更好!


