paperchat
1.0.0
歡迎來到 arXivchat!
arXivchat 是基於法學碩士的軟體,可讓您以對話方式談論 arXiv 發表的論文。它作為 cli 工具、API 提供者和 ChatGPT 插件運行。
由轉發運營商製造。我們與一些最聰明的人合作開展法學碩士和機器學習相關課程。
非常歡迎您做出貢獻!
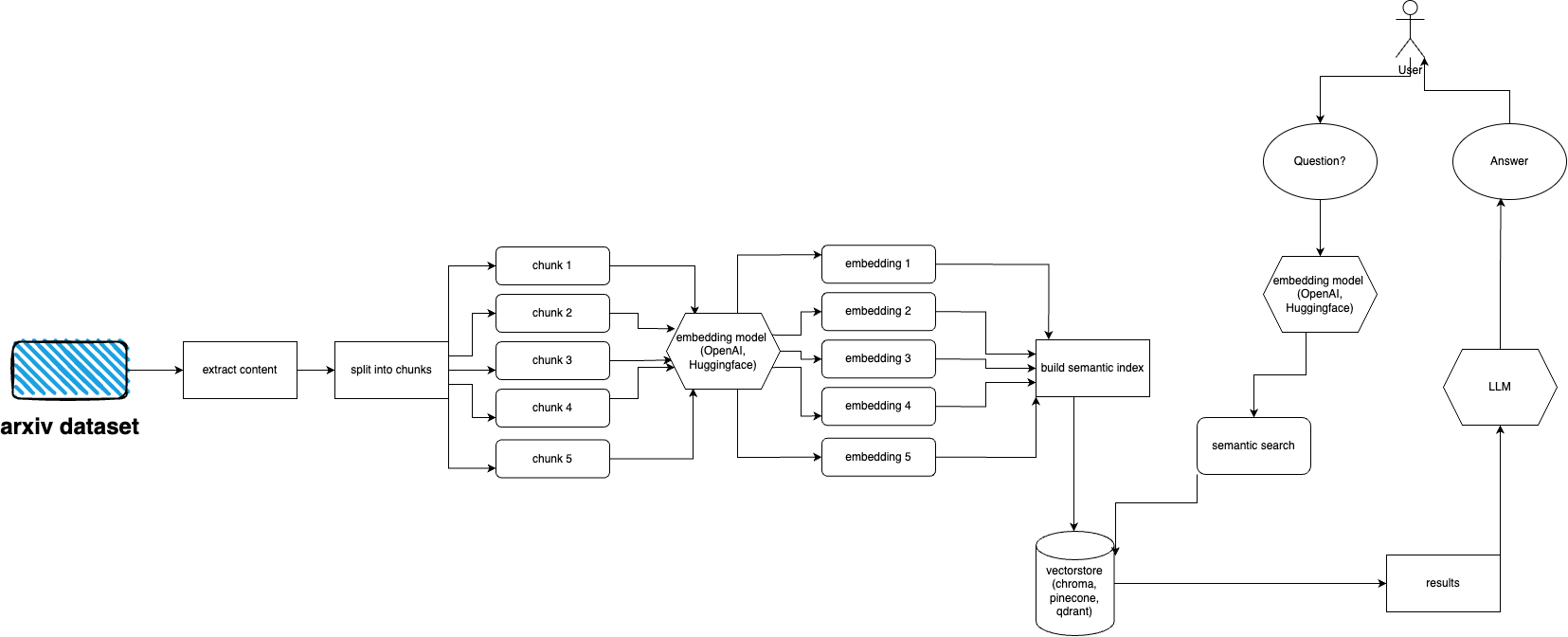
請依照以下步驟快速設定和執行 arXiv 外掛:
如果尚未安裝,請安裝 Python 3.10。
複製儲存庫: git clone https://github.com/Forward-Operators/arxivchat.git
導航到克隆的儲存庫目錄: cd /path/to/arxivchat
安裝詩歌: pip install poetry
使用Python 3.10建立新的虛擬環境: poetry env use python3.10
啟動虛擬環境: poetry shell
安裝應用程式依賴項: poetry install
設定所需的環境變數:
export DATABASE= < your_datastore >
export OPENAI_API_KEY= < your_openai_api_key >
# Add the environment variables for your chosen vector DB.
# Pinecone
export PINECONE_API_KEY= < your_pinecone_api_key >
export PINECONE_ENVIRONMENT= < your_pinecone_environment >
export PINECONE_INDEX= < your_pinecone_index >
# Qdrant
export QDRANT_URL= < your_qdrant_url >
export QDRANT_PORT= < your_qdrant_port >
export QDRANT_GRPC_PORT= < your_qdrant_grpc_port >
export QDRANT_API_KEY= < your_qdrant_api_key >
export QDRANT_COLLECTION= < your_qdrant_collection >
# Chroma
export CHROMA_HOST= < your_chroma_host >
export CHROMA_PORT= < your_chroma_port >
export CHROMA_COLLECTION= < your_chroma_collection >
# Embeddings
export EMBEDDINGS= < openai or huggingface >
export CUDA_ENABLED= < True or False > - needed for huggingface
本機運行 API: cd app/; gunicorn --worker-class uvicorn.workers.UvicornWorker --config ./gunicorn_conf.py main:app
造訪 http://0.0.0.0:8000/docs 處的 API 文件並測試 API 端點。
arXiv 擁有近 200 萬篇出版物的資料集。從他們的網站獲取太多數據是違反 arXiv 的服務條款的(因為它會產生負載)。此資料集可透過 Google Cloud Storage 儲存桶免費獲取,並每週更新。
現在的主要問題是 - 如果我們不想攝取超過 5 TB 的 pdf 文件,如何只取得整個資料集的子集?資料集按月、按年分為多個目錄,因此如果您想獲取 2021 年 9 月以來的所有出版物,您可以運行: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/2109/ ./local_directory
如果您想要取得整個資料集: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/ ./a_local_directory/
但如果您只想取得子集(對於給定的類別和日期),請查看download.py檔案。
預設情況下,ingester 期望此檔案位於/mnt/dataset/arxiv/pdf中,其中包含所有 pdf 檔案。
檢查並運行python scripy.py來提取資料。如果出現問題,您也可以在那裡啟用偵錯。
TODO:也許將其更改為目錄載入器TODO:實現 celery 部署並使用工作器進行攝取
python cli.py 
詢問有關您之前輸入資料庫的主題的問題。也傳回有關來源的信息,連續運作。另一個選擇是使用 REST API(從app目錄執行uvicorn main:app --reload --host 0.0.0.0 --port 8000 )或將其用作 ChatGPT 插件(部署後)
deployment目錄中有 terraform 檔案。使用最適合您的一種。每個文件中都有 README 文件和說明。您還可以建立一個 Docker 映像並在任何您想要的地方運行它。不過影像檔相當大。
目前可以使用 docker 映像部署為 Cloud Run,因此它只是 API 部署。資料攝取必須在其他機器上運行(我建議使用支援 GPU 的運算引擎,特別是如果您想使用 Hugging Face 嵌入,並且因為您可以使用gcsfuse直接從Google Storage 安裝資料集)使用GCS 儲存桶與雲端的潛在解決方案跑步
目前它可以部署為容器應用程式(僅 API 部署,您需要另一個部署來進行攝取)
尚不支援 AWS。即將推出。
arxivchat 預設為 OpenAI 使用text-embedding-ada-002 ,您可以在app/tools/factory.py中更改它
現在您可以使用任何適用於sentence_transformers的型號。您可以在app/tools/factory.py中更改模型
如果您有任何問題,請使用 GitHub issues 回報。
我們希望您能幫助我們讓 arXivchat 變得更好!如需貢獻,請依照以下步驟操作:
arXivchat 是根據 MIT 許可證發布的。


