distrifuser
v0.0.1beta0
[2024 年 7 月 29 日] ColossalAI 支持 DistriFusion!
【2024年4月4日】 DistriFusion入選CVPR 2024亮點海報!
[2024年2月29日] DistriFusion 被 CVPR 2024 接受!我們的程式碼是公開的!
 我們引入了 DistriFusion,這是一種免訓練演算法,可利用多個 GPU 來加速擴散模型推理,而不會犧牲影像品質。 Naïve Patch(概述 (b))因缺乏補丁互動而存在碎片問題。所提供的範例是使用 SDXL 使用 50 步歐拉採樣器以 1280×1920 解析度產生的,並在 A100 GPU 上測量延遲。
我們引入了 DistriFusion,這是一種免訓練演算法,可利用多個 GPU 來加速擴散模型推理,而不會犧牲影像品質。 Naïve Patch(概述 (b))因缺乏補丁互動而存在碎片問題。所提供的範例是使用 SDXL 使用 50 步歐拉採樣器以 1280×1920 解析度產生的,並在 A100 GPU 上測量延遲。
DistriFusion:高解析度擴散模型的分散式平行推理
Muyang Li*、Tianle Cai*、Jiaxin Cao、Qinsheng Zhang、Han Cai、Junjie Bai、Yangqing Jia、Ming-Yu Liu、Kai Li 與 Song Han
麻省理工學院、普林斯頓大學、Lepton AI 和 NVIDIA
在 CVPR 2024 中。
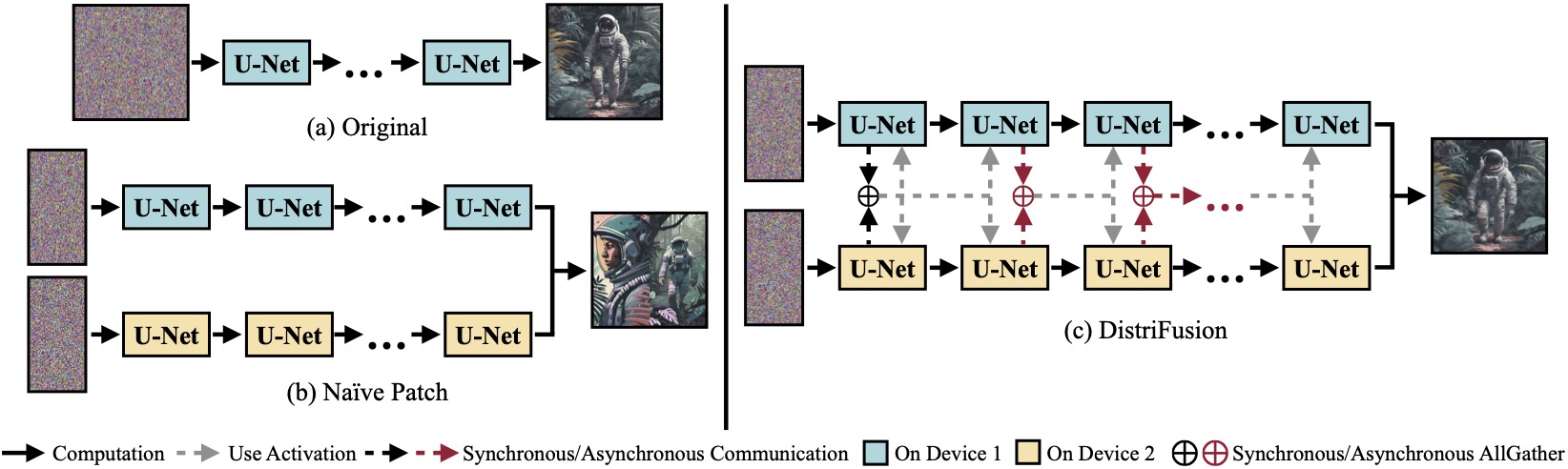 (a)在單一裝置上運行的原始擴散模型。 (b)由於補丁之間缺乏交互,將圖像天真地分成跨 2 個 GPU 的 2 個補丁,因此邊界處有明顯的接縫。 (c)我們的 DistriFusion 在第一步採用同步通訊進行修補程式互動。之後,我們透過非同步通訊重複使用上一個步驟中的啟動。透過這種方式,通訊開銷可以隱藏到計算管道中。
(a)在單一裝置上運行的原始擴散模型。 (b)由於補丁之間缺乏交互,將圖像天真地分成跨 2 個 GPU 的 2 個補丁,因此邊界處有明顯的接縫。 (c)我們的 DistriFusion 在第一步採用同步通訊進行修補程式互動。之後,我們透過非同步通訊重複使用上一個步驟中的啟動。透過這種方式,通訊開銷可以隱藏到計算管道中。
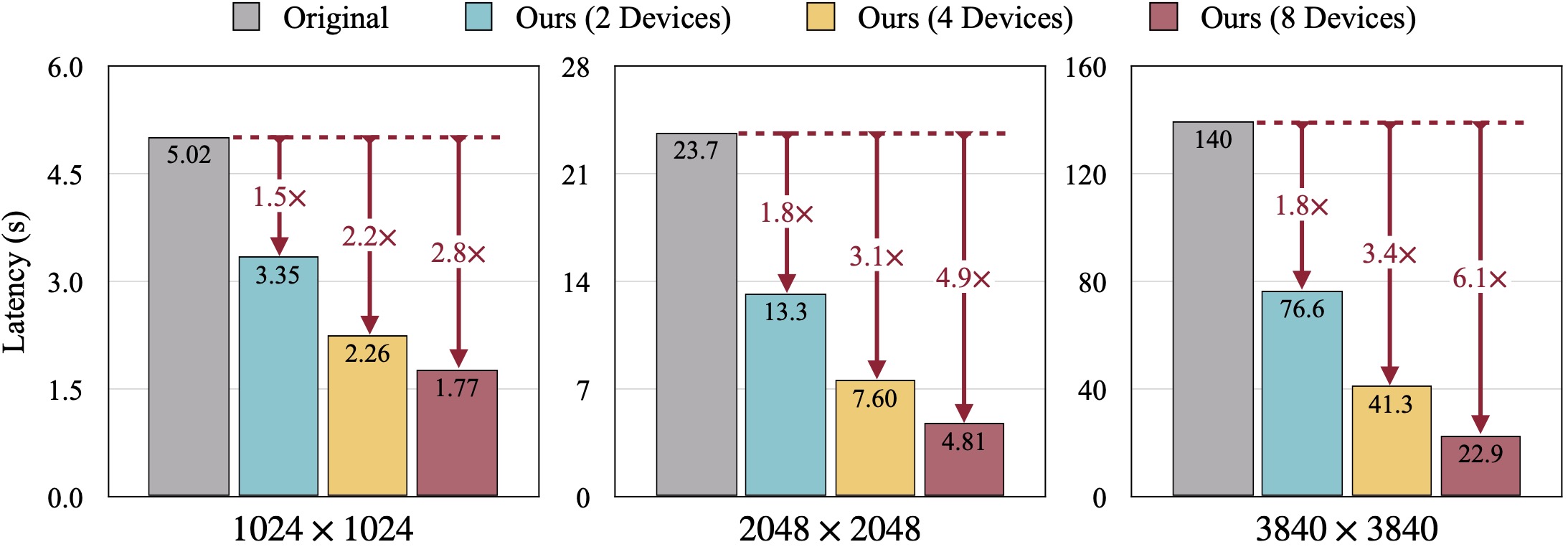
 SDXL 的定性結果。 FID 是根據真實影像計算的。我們的 DistriFusion 可以根據使用的裝置數量減少延遲,同時保持視覺保真度。
SDXL 的定性結果。 FID 是根據真實影像計算的。我們的 DistriFusion 可以根據使用的裝置數量減少延遲,同時保持視覺保真度。
參考:
安裝 PyTorch 後,您應該可以使用 PyPI 安裝distrifuser
pip install distrifuser或透過 GitHub:
pip install git+https://github.com/mit-han-lab/distrifuser.git或本地開發
git clone [email protected]:mit-han-lab/distrifuser.git
cd distrifuser
pip install -e .在scripts/sdxl_example.py中,我們提供了用於使用 DistriFusion 運行 SDXL 的最小腳本。
import torch
from distrifuser . pipelines import DistriSDXLPipeline
from distrifuser . utils import DistriConfig
distri_config = DistriConfig ( height = 1024 , width = 1024 , warmup_steps = 4 )
pipeline = DistriSDXLPipeline . from_pretrained (
distri_config = distri_config ,
pretrained_model_name_or_path = "stabilityai/stable-diffusion-xl-base-1.0" ,
variant = "fp16" ,
use_safetensors = True ,
)
pipeline . set_progress_bar_config ( disable = distri_config . rank != 0 )
image = pipeline (
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k" ,
generator = torch . Generator ( device = "cuda" ). manual_seed ( 233 ),
). images [ 0 ]
if distri_config . rank == 0 :
image . save ( "astronaut.png" )具體來說,我們的distrifuser與擴散器共享相同的 API,並且可以以類似的方式使用。您只需要定義一個DistriConfig並使用我們包裝的DistriSDXLPipeline來載入預先訓練的 SDXL 模型。然後,我們可以產生像擴散器中的StableDiffusionXLPipeline一樣的影像。運行命令是
torchrun --nproc_per_node= $N_GPUS scripts/sdxl_example.py其中$N_GPUS是您要使用的 GPU 數量。
我們也在scripts/sd_example.py中提供了一個用於使用 DistriFusion 運行 SD1.4/2 的最小腳本。用法是一樣的。
我們的基準測試結果使用 PyTorch 2.2 和擴散器 0.24.0。首先,您可能需要安裝一些額外的依賴項:
pip install git+https://github.com/zhijian-liu/torchprofile datasets torchmetrics dominate clean-fid您可以使用scripts/generate_coco.py產生帶有COCO 標題的圖像。命令是
torchrun --nproc_per_node=$N_GPUS scripts/generate_coco.py --no_split_batch
其中$N_GPUS是您要使用的 GPU 數量。預設情況下,產生的結果將儲存在results/coco中。您也可以使用--output_root對其進行自訂。您可能需要調整的一些其他參數:
--num_inference_steps :推理步驟數。我們預設使用 50。--guidance_scale :無分類器的指導尺度。我們預設使用 5。--scheduler :擴散採樣器。我們預設使用 DDIM 採樣器。您也可以使用euler作為 Euler 取樣器,使用dpm-solver作為 DPM 求解器。--warmup_steps :額外預熱步驟的數量(預設為 4)。--sync_mode :不同的 GroupNorm 同步模式。預設情況下,它使用我們修正後的非同步 GroupNorm。--parallelism :您使用的平行範例。預設情況下,它是補丁並行。您可以使用tensor來實現張量並行性,使用naive_patch來實現樸素補丁。產生所有映像後,您可以使用我們的腳本scripts/compute_metrics.py來計算PSNR、LPIPS和FID。用法是
python scripts/compute_metrics.py --input_root0 $IMAGE_ROOT0 --input_root1 $IMAGE_ROOT1其中$IMAGE_ROOT0和$IMAGE_ROOT1是您嘗試比較的映像資料夾的路徑。如果IMAGE_ROOT0是真實資料夾,請新增--is_gt標誌以調整大小。我們還提供了一個腳本scripts/dump_coco.py來轉儲真實圖像。
您可以使用scripts/run_sdxl.py來對不同方法的延遲進行基準測試。命令是
torchrun --nproc_per_node= $N_GPUS scripts/run_sdxl.py --mode benchmark --output_type latent其中$N_GPUS是您要使用的 GPU 數量。與scripts/generate_coco.py類似,您也可以更改一些參數:
--num_inference_steps :推理步驟數。我們預設使用 50。--image_size :產生的圖片大小。預設情況下,它是1024×1024。--no_split_batch :停用批次分割以實現無分類器指導。--warmup_steps :額外預熱步驟的數量(預設為 4)。--sync_mode :不同的 GroupNorm 同步模式。預設情況下,它使用我們修正後的非同步 GroupNorm。--parallelism :您使用的平行範例。預設情況下,它是補丁並行。您可以使用tensor來實現張量並行性,使用naive_patch來實現樸素補丁。--warmup_times / --test_times :預熱/測試運行的次數。預設情況下,它們分別為 5 和 20。 如果您使用此程式碼進行研究,請引用我們的論文。
@inproceedings { li2023distrifusion ,
title = { DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models } ,
author = { Li, Muyang and Cai, Tianle and Cao, Jiaxin and Zhang, Qinsheng and Cai, Han and Bai, Junjie and Jia, Yangqing and Liu, Ming-Yu and Li, Kai and Han, Song } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2024 }
}我們的程式碼是基於huggingface/diffusers和lmxyy/sige開發的。我們感謝 torchprofile 進行 MAC 測量,以及 clean-fid 進行 FID 計算,以及 Lightning-AI/torchmetrics 進行 PSNR 和 LPIPS。
我們感謝朱俊彥和朱立庚的有益討論和寶貴回饋。該計畫得到了 MIT-IBM Watson AI 實驗室、亞馬遜、麻省理工學院科學中心和國家科學基金會的支持。


