serverless rag ynetnews bedrock demo
1.0.0
問答 (QA) 是一項重要任務,涉及提取以自然語言提出的事實查詢的答案。通常,QA 系統會處理針對包含結構化或非結構化資料的知識庫的查詢,並產生包含準確資訊的回應。確保高精度是開發有用、可靠且值得信賴的問答系統的關鍵,特別是對於企業用例。
Amazon Titan、Anthropic Claude 和 AI21 Jurassic 2 等生成式 AI 模型使用機率分佈來產生問題的答案。這些模型經過大量文字資料的訓練,這使它們能夠預測序列中接下來會發生什麼,或者特定單字後面可能會出現什麼單字。然而,這些模型無法為每個問題提供準確或確定性的答案,因為數據中總是存在一定程度的不確定性。
企業需要查詢特定領域和專有數據,並使用這些資訊來回答問題,更普遍的是,還需要查詢尚未訓練模型的數據。
在此儲存庫中,我們將探索以下 QA 模式:
我們使用檢索增強生成,它改進了第一個,我們將問題與盡可能多的相關上下文連接起來,這可能包含我們正在尋找的答案或資訊。這裡的挑戰是,可以使用多少上下文資訊是有限制的,這是由模型的令牌限制決定的。 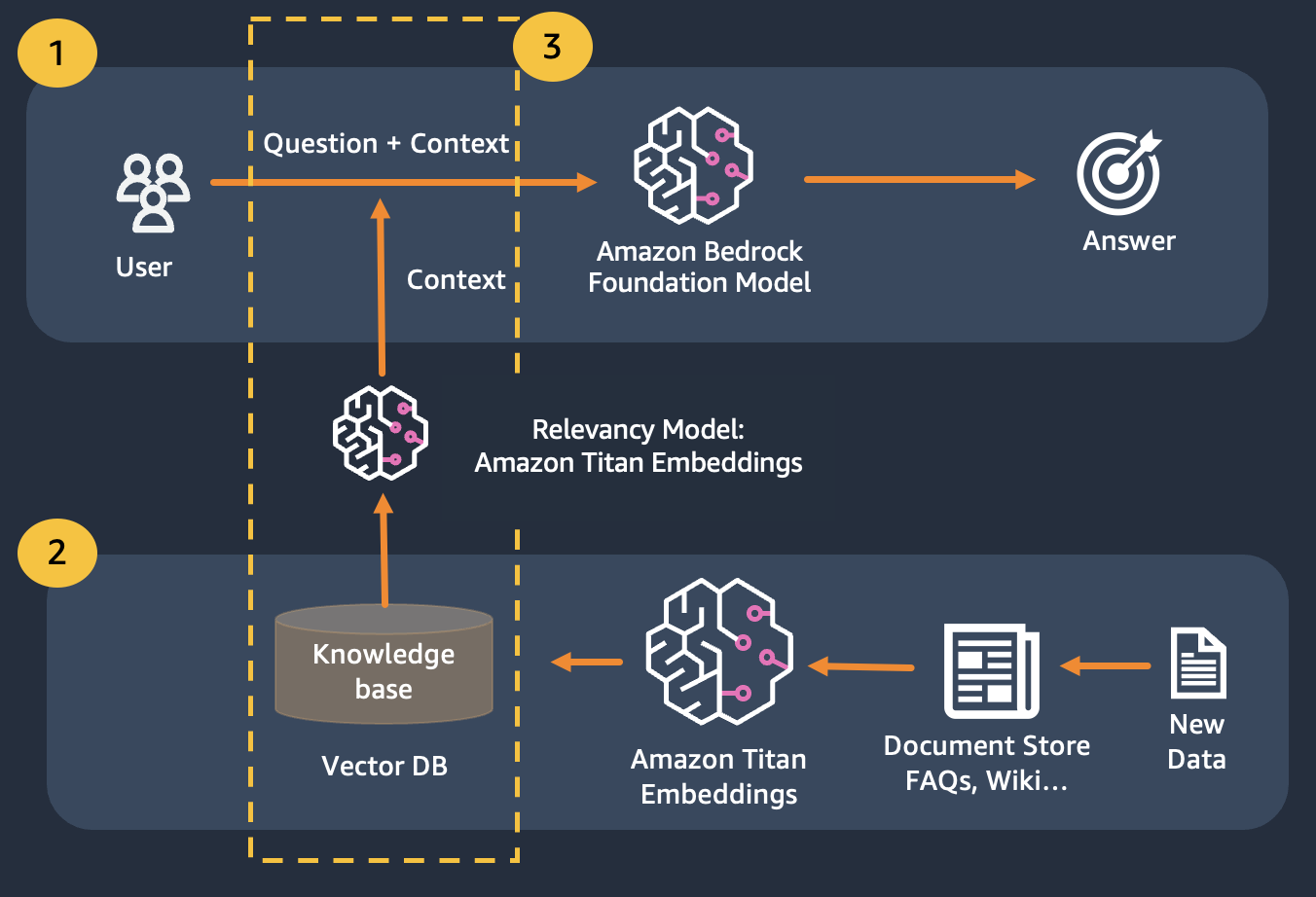
這可以透過使用檢索增強生成 (RAG) 來克服
RAG 結合使用嵌入來索引文件語料庫以建立知識庫,並使用 LLM 從知識庫中的文件子集提取資訊。
作為 RAG 的準備步驟,建構知識庫的文件被分割成固定大小的區塊(與所選嵌入模型的最大輸入大小相符),然後傳遞給模型以獲得嵌入向量。嵌入與文件的原始區塊和附加元資料一起儲存在向量資料庫中。向量資料庫經過最佳化,可以有效地執行向量之間的相似性搜尋。
擁有可能是私有的或經常變化的資料儲存的客戶。 RAG 方法解決了 2 個問題,面臨以下挑戰的客戶可以從實驗室中受益。
學完本模組後,您應該對以下內容有一個很好的理解:
在本模組中,我們將引導您了解如何使用 Bedrock 實作 QA 模式。此外,我們還為您準備了要載入到向量資料庫中的嵌入。
請注意,您可以使用 Titan Embeddings 取得使用者問題的嵌入,然後使用這些嵌入從向量資料庫中檢索最相關的文檔,建立一個連接前 3 個文檔的提示,並透過 Bedrock 呼叫 LLM 模型。


