Image to Speech GenAI Tool Using LLM
1.0.0
AI 工具,透過提示 GenAI LLM 模型、Hugging Face AI 模型以及 OpenAI 和 LangChain,根據上傳圖像的上下文生成音訊短篇故事。分別部署在Streamlit和Hugging Space雲端。
在 Streamlit 上啟動應用程式
在 HuggingFace 空間上啟動應用程式
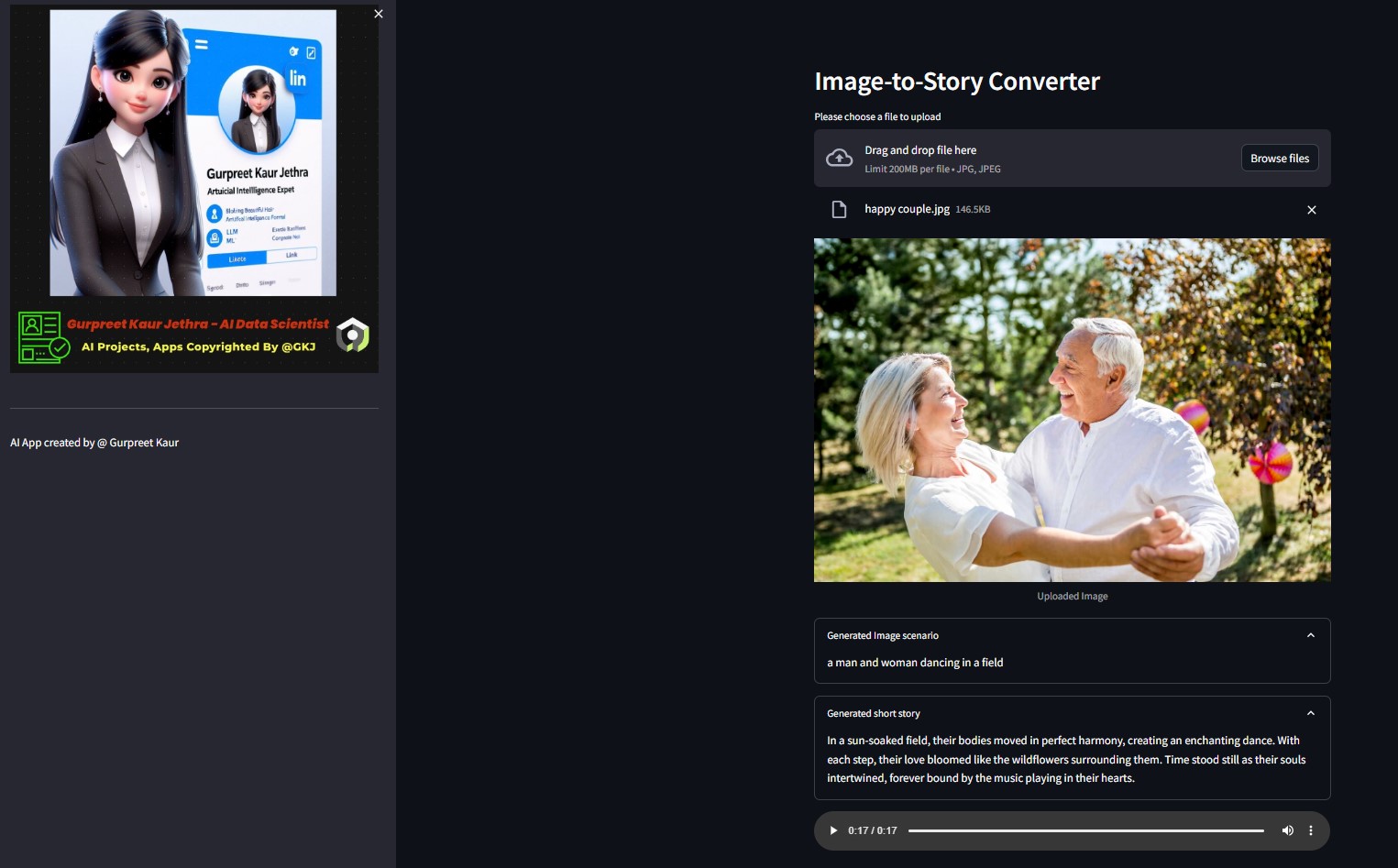
您可以在相應的img-audio資料夾中收聽此測試演示圖像的相應音訊文件
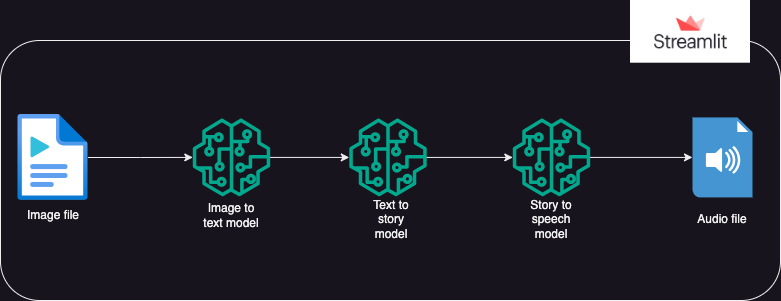
使用 Hugging Face AI 模型從圖像生成文字的應用程序,然後從文字生成音訊。
執行分為3部分:
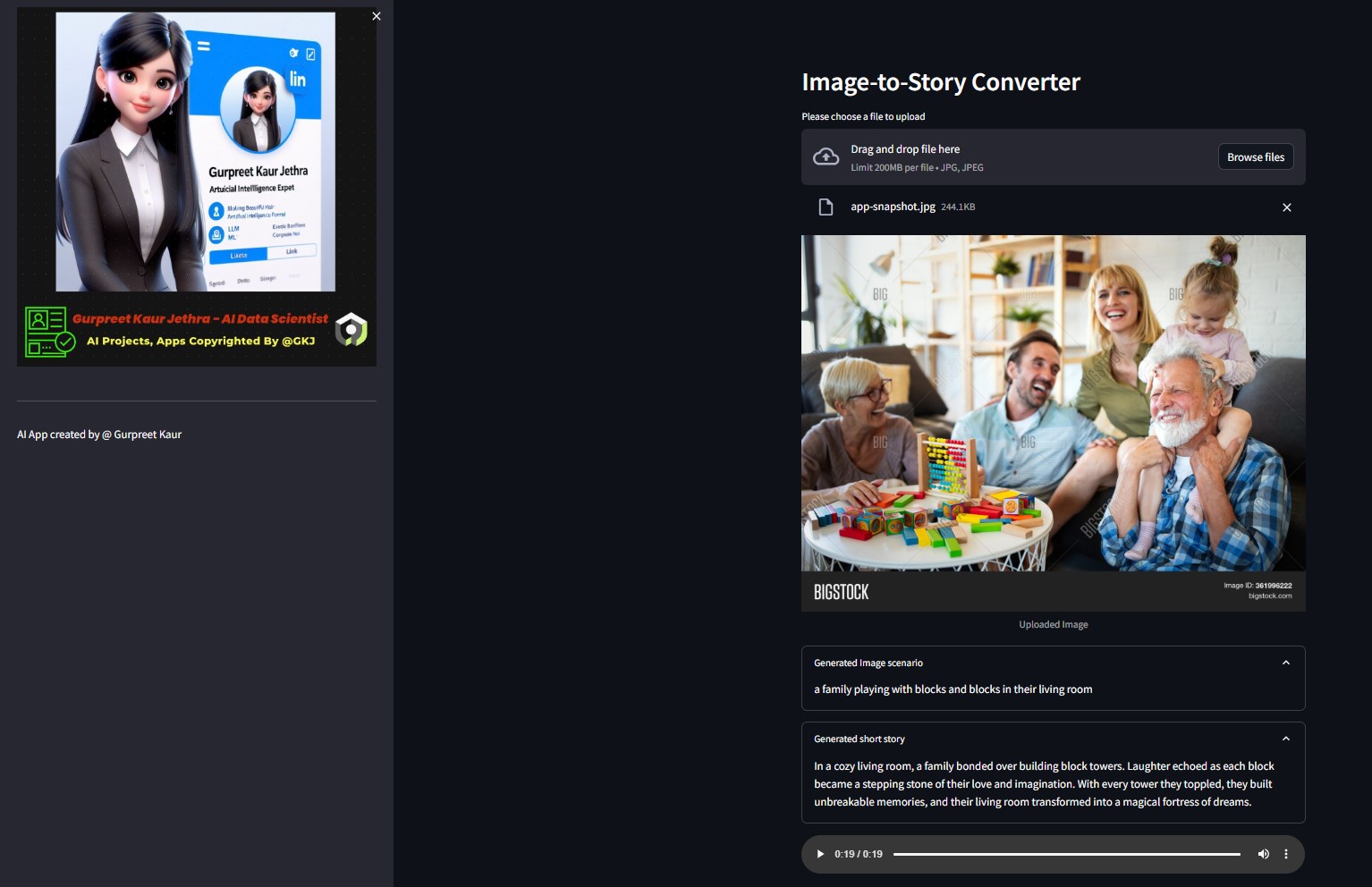 您可以在相應的
您可以在相應的img-audio資料夾中收聽此測試圖像的相應音訊文件
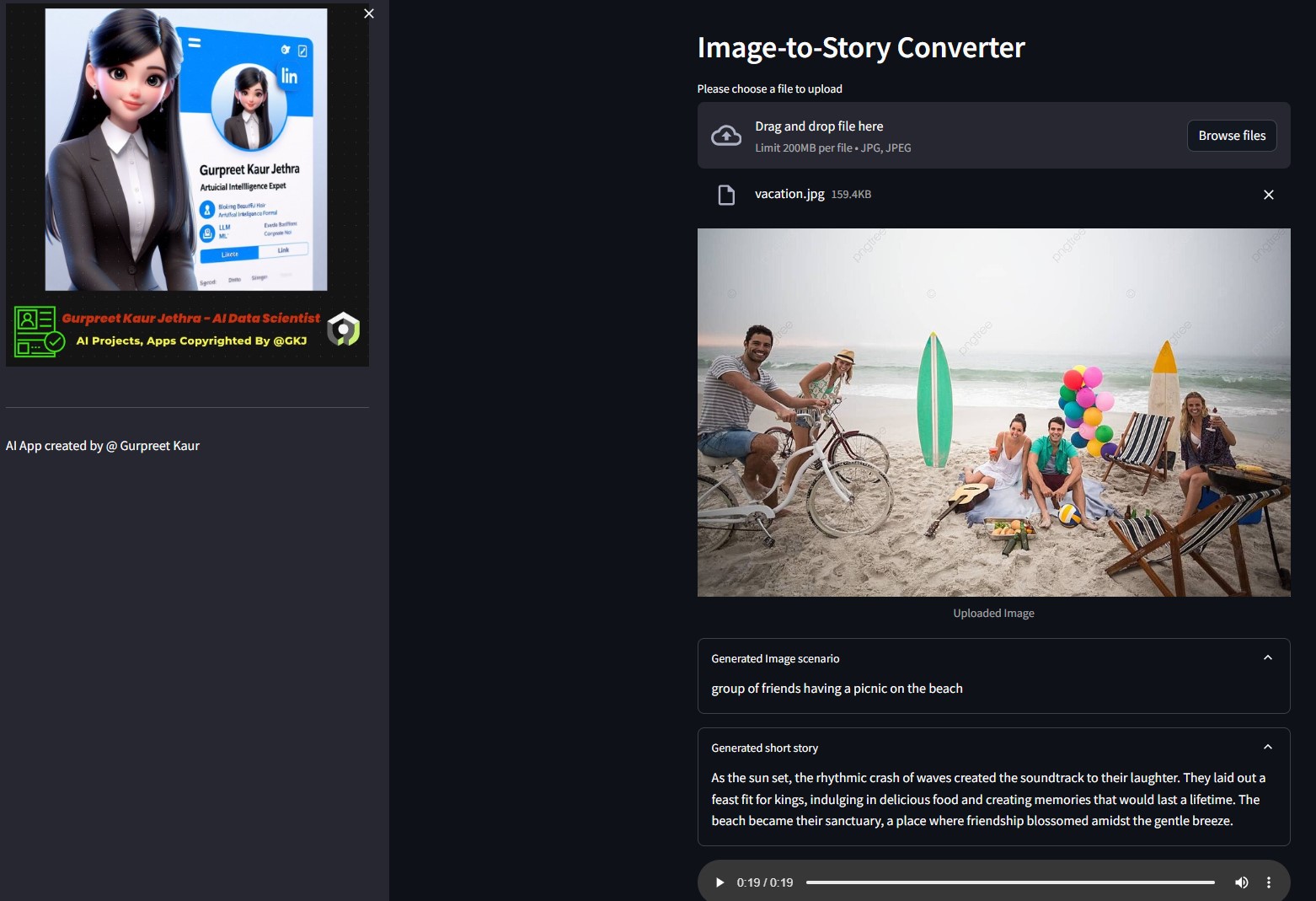
克隆儲存庫:
git clone https://github.com/GURPREETKAURJETHRA/Image-to-Speech-GenAI-Tool-Using-LLM.git
安裝所需的 Python 套件:
pip install -r requirements.txt
透過在專案的根目錄中建立包含以下內容的 .env 檔案來設定 OpenAI API 金鑰和 Hugging Face 令牌:
OPENAI_API_KEY=<your-api-key-here> HUGGINGFACE_API_TOKEN=<<your-access-token-here>
運行 Streamlit 應用程式:
streamlit run app.py
根據 MIT 許可證分發。請參閱LICENSE以了解更多資訊。


