stellar metrics
1.0.0
我們論文的代碼:Stellar:以人為中心的個人化文字到圖像方法的系統評估
作者:帕諾斯·阿赫利奧塔斯、亞歷山德羅斯·貝內塔托斯、約丹尼斯·福斯蒂羅普洛斯、迪米特里斯·斯科爾蒂斯
該程式碼庫由 Iordanis Fostiropoulos 維護。如有任何疑問,請與我們聯絡。
在下載或使用此儲存庫中的程式碼的任何部分之前,請查看並確認此儲存庫中包含的「授權條款」和「第三方授權條款」中規定的條款和條件。繼續下載和使用此儲存庫中的程式碼的任何部分即表示您同意這些條款和條件。
 注意:顯示的「輸入影像」和「附加影像」可在 CELEBMaksHQ 資料集中找到。
注意:顯示的「輸入影像」和「附加影像」可在 CELEBMaksHQ 資料集中找到。
這項工作是基於我們的技術手稿《Stellar:以人為中心的個人化文字到影像方法的系統評估》。我們提出了 5 個指標來評估以人為中心的個人化 Text-2-Image 模型。此儲存庫為 Text-2-Image 和 Image-2-Image 方法提供了 8 個附加基準指標的實作。
文獻中提供了幾個指標。我們用我們的工作中引入的那些來表示。
我們提供自己對現有指標的實現,並讓使用者參考他們的論文以了解其工作的技術細節。
| 姓名 | 評價類型 | 代碼名稱 | 參考 |
|---|---|---|---|
| 審美。 | 影像到影像 | aesth | 關聯 |
| 影像到影像 | clip | 關聯 | |
| 夢幻模擬 | 影像到影像 | dreamsim | 關聯 |
| 文字轉圖像 | clip | 關聯 | |
| HPSv1 | 文字轉圖像 | hps | 關聯 |
| HPSv2 | 文字轉圖像 | hps | 關聯 |
| 圖像獎勵 | 文字轉圖像 | im_reward | 關聯 |
| 挑選分數 | 文字轉圖像 | pick | 關聯 |
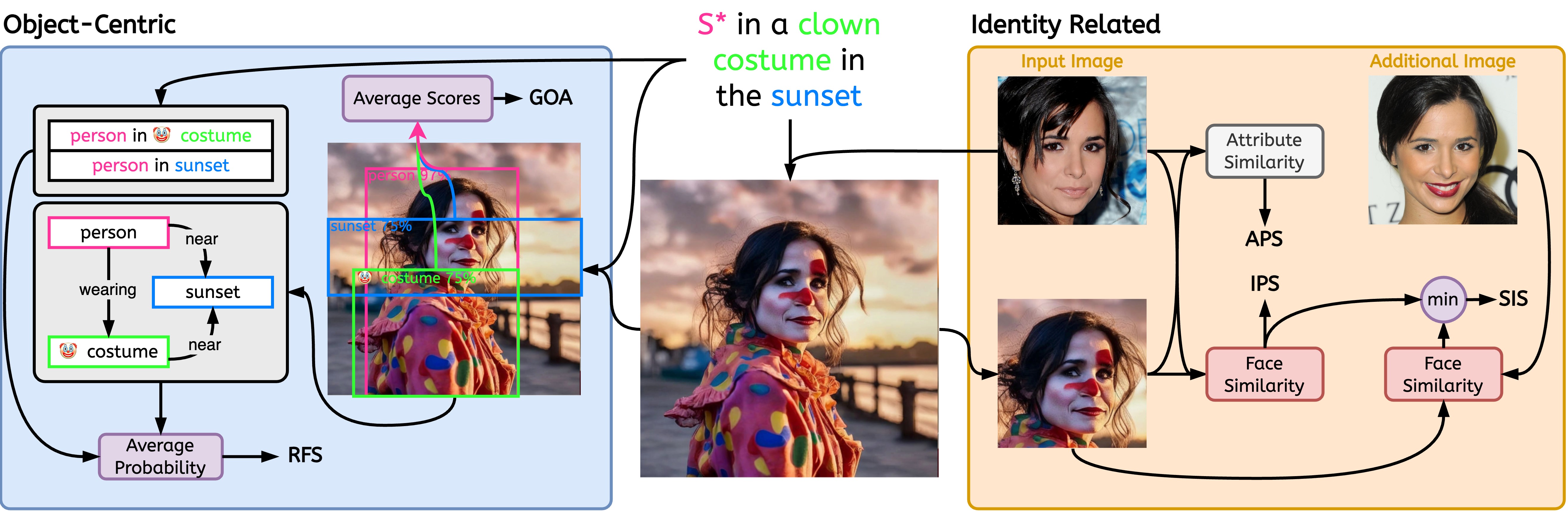
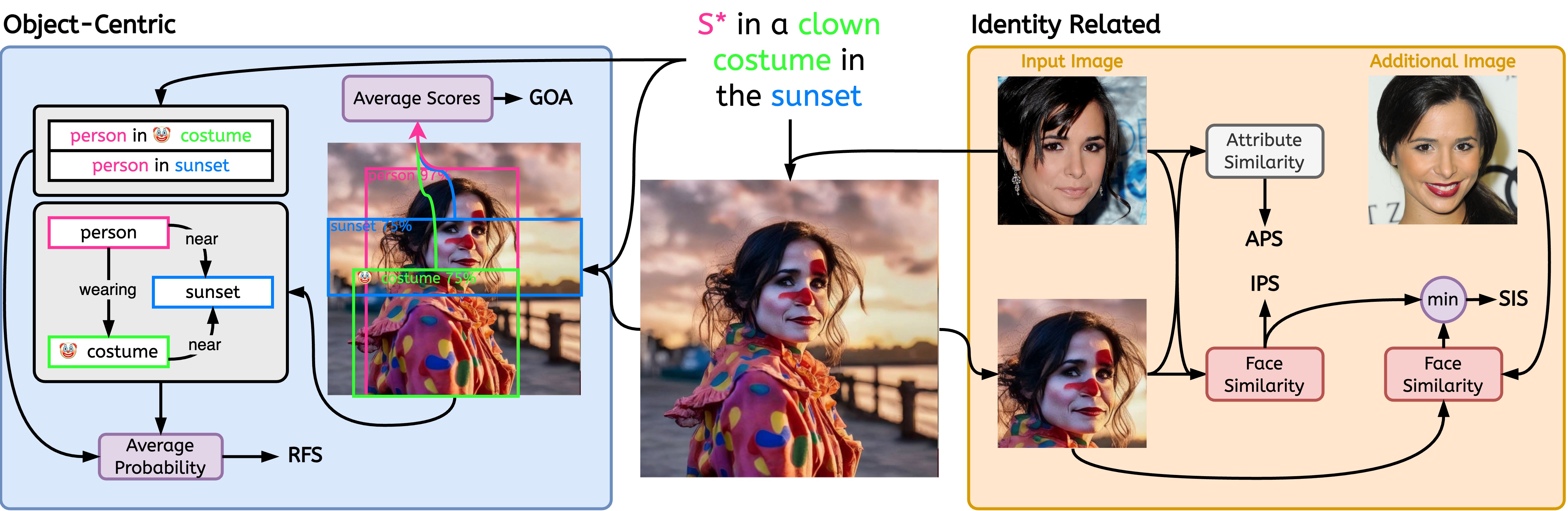
| APS | 個性化圖文轉換 | aps | 關聯 |
| 阿富汗政府 | 以物件為中心 | goa | 關聯 |
| IPS | 個性化圖文轉換 | ips | 關聯 |
| 以關係為中心 | rfs | 關聯 | |
| 安全資訊系統 | 個性化圖文轉換 | sis | 關聯 |
pip install git+https://github.com/stellar-gen-ai/stellar-metrics.git我們想要計算每個單獨圖像的度量。因此,它可以幫助診斷方法的失敗案例。
$ python -m stellar_metrics --metric code_name --stellar-path ./stellar-dataset --syn-path ./model-output --save-dir ./save-dir您可以選擇為主幹指定--device 、 --batch-size和--clip-version
注意模型輸出和恆星資料集之間必須存在一對一的對應關係。 stellar-dataset用於計算一些指標,例如需要原始圖像的身份保留。 syn-path和stellar-path之間的錯誤配置可能會導致錯誤的結果。
計算IPS
$ python -m stellar_metrics --metric ips --stellar-path ./tests/assets/mock_stellar_dataset --syn-path ./tests/assets/stellar_net --save-dir ./save-dir計算剪輯
$ python -m stellar_metrics --metric clip --stellar-path ./tests/assets/mock_stellar_dataset --syn-path ./tests/assets/stellar_net --save-dir ./save-dir$ python -m stellar_metrics.analysis --save-dir ./save-dir以相當粗略但專門的方式評估輸入身份和生成的圖像之間的面部相似性。我們的指標使用臉部偵測器來隔離輸入影像和生成影像中的身分臉部。然後,它採用專門的臉部偵測模型從偵測到的區域中提取臉部表徵嵌入。
評估產生的影像如何很好地保持相關身分的特定細微屬性,例如年齡、性別和其他不變的臉部特徵(例如,高顴骨)。利用恆星影像中的註釋,我們可以評估這些二元面部特徵。
作為確定模型對同一個人的不同圖像的敏感程度的衡量標準;進一步推廣模型,無論輸入的影像不相關的變化(例如,照明條件、主體的姿勢)如何,主體的身份都能被一致地捕捉到。
為了實現這一目標, SIS需要存取人類受試者的多張影像(Stellar 資料集的設計滿足了這一條件);也是我們唯一一個要求如此苛刻的評價指標。
我們引入專門的、可解釋的指標來評估影像和提示之間對齊的兩個關鍵方面;物件表示的忠實性和所描繪的關係的保真度。
評估在生成的影像上表示所需的提示物件互動是否成功。考慮到即使是專門的場景圖生成(SGG)模型也難以理解視覺關係,該指標引入了對個性化模型忠實描述提示關係的能力的有價值的局部洞察。