BinaryVectorDB
1.0.0
該存儲庫包含一個二進制向量資料庫,用於對大型資料集進行有效搜索,旨在用於教育目的。
大多數嵌入模型將其向量表示為 float32:它們會消耗大量內存,並且搜尋速度非常慢。在 Cohere,我們引入了第一個具有本機 int8 和二進制支援的嵌入模型,它可以為您提供出色的搜尋質量,而成本只需一小部分:
| 模型 | 搜尋品質奇蹟 | 搜尋 100 萬份文件的時間 | 需要 250M 內存 維基百科嵌入 | AWS 上的價格(x2GB 實例) |
|---|---|---|---|---|
| OpenAI 文字嵌入-3-小 | 44.9 | 680毫秒 | 1431 GB | $65,231 / 年 |
| OpenAI 文字嵌入-3-large | 54.9 | 1240 毫秒 | 2861 GB | $130,463 / 年 |
| Cohere Embed v3(多國語言) | ||||
| 嵌入 v3 - float32 | 66.3 | 460毫秒 | 954GB | $43,488 / 年 |
| 嵌入 v3 - 二進位 | 62.8 | 24 毫秒 | 30GB | $1,359 / 年 |
| 嵌入 v3 - 二進位 + int8 重新評分 | 66.3 | 28 毫秒 | 30GB記憶體+240GB磁碟 | $1,589 / 年 |
我們創建了一個演示,讓您在 100M 維基百科嵌入中搜尋 VM,每月僅需 15 美元:演示 - 搜尋 100M 維基百科嵌入,每月僅需 15 美元
您可以輕鬆地對自己的資料使用 BinaryVectorDB。
設定很簡單:
pip install BinaryVectorDB
要使用下面的一些範例,您需要來自 cohere.com 的Cohere API 金鑰(免費或付費)。您必須將此 API 金鑰設定為環境變數: export COHERE_API_KEY=your_api_key
稍後我們將展示如何根據您自己的資料建立向量資料庫。首先,讓我們使用預先建立的二進位向量資料庫。我們在 https://huggingface.co/datasets/Cohere/BinaryVectorDB 上託管各種預先建置資料庫。您可以下載這些並在本地使用它們。
讓我們從維基百科的簡單英文版本開始:
wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/wikipedia-2023-11-simple.zip
然後解壓縮這個文件:
unzip wikipedia-2023-11-simple.zip
您可以透過將資料庫指向上一步中解壓縮的資料夾來輕鬆載入資料庫:
from BinaryVectorDB import BinaryVectorDB
# Point it to the unzipped folder from the previous step
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db = BinaryVectorDB ( "wikipedia-2023-11-simple/" )
query = "Who is the founder of Facebook"
print ( "Query:" , query )
hits = db . search ( query )
for hit in hits [ 0 : 3 ]:
print ( hit )該資料庫有 646,424 個嵌入,總大小為 962 MB。然而,記憶體中僅載入了 80 MB 的二進位嵌入。文件及其 int8 嵌入保存在磁碟上,僅在需要時載入。
記憶體中的二進位嵌入和磁碟上的 int8 嵌入和文件的這種分割使我們能夠擴展到非常大的資料集,而無需大量記憶體。
建立您自己的二進制向量資料庫非常容易。
from BinaryVectorDB import BinaryVectorDB
import os
import gzip
import json
simplewiki_file = "simple-wikipedia-example.jsonl.gz"
#If file not exist, download
if not os . path . exists ( simplewiki_file ):
cmd = f"wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/simple-wikipedia-example.jsonl.gz"
os . system ( cmd )
# Create the vector DB with an empty folder
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db_folder = "path_to_an_empty_folder/"
db = BinaryVectorDB ( db_folder )
if len ( db ) > 0 :
exit ( f"The database { db_folder } is not empty. Please provide an empty folder to create a new database." )
# Read all docs from the jsonl.gz file
docs = []
with gzip . open ( simplewiki_file ) as fIn :
for line in fIn :
docs . append ( json . loads ( line ))
#Limit it to 10k docs to make the next step a bit faster
docs = docs [ 0 : 10_000 ]
# Add all documents to the DB
# docs2text defines a function that maps our documents to a string
# This string is then embedded with the state-of-the-art Cohere embedding model
db . add_documents ( doc_ids = list ( range ( len ( docs ))), docs = docs , docs2text = lambda doc : doc [ 'title' ] + " " + doc [ 'text' ])該文件可以是任何 Python 可序列化物件。您需要為docs2text提供一個函數,將文件對應到字串。在上面的範例中,我們連接標題和文字欄位。該字串被發送到嵌入模型以產生所需的文字嵌入。
新增/刪除/更新文件很容易。有關如何在資料庫中新增/更新/刪除文件的範例腳本,請參閱examples/add_update_delete.py。
我們宣布推出 Cohere int8 和二進位 Embeddings 嵌入,可將所需記憶體減少 4 倍和 32 倍。此外,它還能將向量搜尋速度提高 40 倍。
這兩種技術都結合在 BinaryVectorDB 中。舉個例子,我們假設英文維基百科有 42M 嵌入。正常的 float32 嵌入需要42*10^6*1024*4 = 160 GB記憶體來託管嵌入。由於 float32 上的搜尋相當緩慢(在 42M 嵌入上大約需要 45 秒),我們需要添加像 HNSW 這樣的索引,這會額外增加 20GB 內存,因此總共需要 180GB。
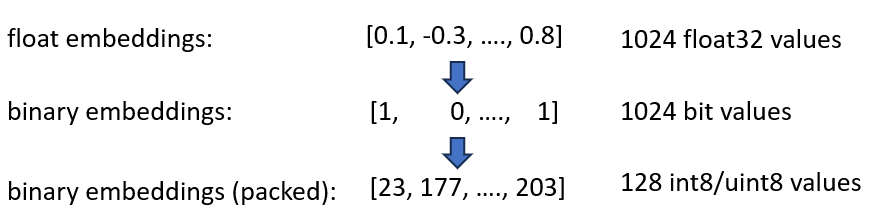
二進位嵌入將每個維度表示為 1 位元。這將記憶體需求減少到160 GB / 32 = 5GB 。此外,由於二進位空間中的搜尋速度提高了 40 倍,因此在許多情況下您不再需要 HNSW 索引。您將記憶體需求從 180 GB 減少到 5 GB,節省了 36 倍。
當我們查詢該索引時,我們也以二進位形式對查詢進行編碼並使用漢明距離。漢明距離測量 2 個向量之間的 1 位差異。這是一個非常快速的操作:要比較兩個二進位向量,您只需要 2 個 CPU 週期: popcount(xor(vector1, vector2)) 。 XOR 是 CPU 上最基本的運算,因此運作速度非常快。 popcount統計暫存器中1的個數,同樣只需要1個CPU週期。
總的來說,這為我們提供了一個保持大約 90% 搜尋品質的解決方案。
我們可以透過<float, binary>重新評分將上一步驟的搜尋品質從 90% 提高到 95%。
例如,我們取得步驟 1 中的前 100 個結果,並計算dot_product(query_float_embedding, 2*binary_doc_embedding-1) 。
假設我們的查詢嵌入是[0.1, -0.3, 0.4] ,二進位文件嵌入是[1, 0, 1] 。該步驟然後計算:
(0.1)*(1) + (-0.3)*(-1) + 0.4*(1) = 0.1 + 0.3 + 0.4 = 0.8

我們使用這些分數並對我們的結果重新評分。這將搜尋品質從 90% 提高到 95%。這個操作可以非常快速地完成:我們從嵌入模型中取得查詢浮點嵌入,二進位嵌入在記憶體中,所以我們只需要進行 100 次求和運算。
為了進一步提高搜尋質量,從 95% 提高到 99.99%,我們使用 int8 從磁碟重新評分。
我們將所有 int8 文件嵌入保存在磁碟上。然後,我們從上面的步驟中取出前 30 個,從磁碟載入 int8 嵌入,並計算cossim(query_float_embedding, int8_doc_embedding_from_disk)
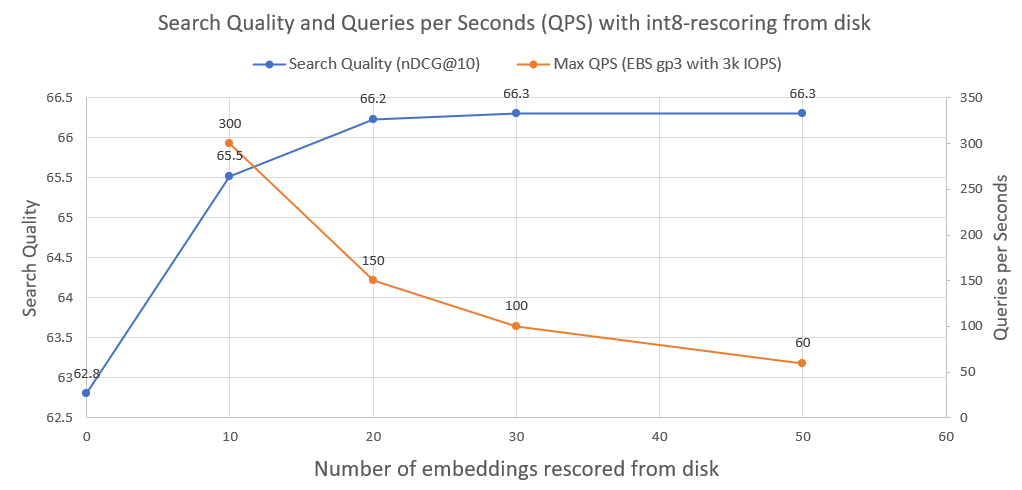
在下圖中,您可以看到 int8-rescoring 的程度並提高了搜尋效能:
我們也繪製了此類系統在普通 AWS EBS 網路磁碟機上以 3000 IOPS 運作時可以實現的每秒查詢數。正如我們所看到的,我們需要從磁碟載入的 int8 嵌入越多,QPS 就越少。
為了執行二分搜索,我們使用 faiss 的 IndexBinaryFlat 索引。它只存儲二進制嵌入,允許超快速索引和超快速搜尋。
為了儲存文件和 int8 嵌入,我們使用 RocksDict,這是一個基於 RocksDB 的 Python 磁碟鍵值儲存。
有關該類別的完整實現,請參閱 BinaryVectorDB。
並不真地。該存儲庫主要用於教育目的,以展示如何擴展到大型數據集的技術。重點更多地放在易用性上,而在實現中缺少一些關鍵方面,例如多進程安全性、回滾等。
如果您確實想投入生產,請使用 Vespa.ai 等適當的向量資料庫,它可以讓您獲得類似的結果。
在 Cohere,我們幫助客戶以極低的成本對數百億個嵌入運行語義搜尋。如果您需要可擴展的解決方案,請隨時聯絡 Nils Reimers。


