VideoX
1.0.0
這是我們的影片理解作品合集
SeqTrack (
@CVPR'23): SeqTrack:視覺物件追蹤的序列到序列學習
X-CLIP (
@ECCV'22 Oral):擴展用於通用視訊辨識的語言影像預訓練模型
MS-2D-TAN (
@TPAMI'21):使用自然語言進行矩定位的多尺度 2D 時間相鄰網絡
2D-TAN (
@AAAI'20):學習 2D 時態相鄰網絡,使用自然語言進行時刻定位
招募具有較強編碼能力的研究實習生:[email protected] | [email protected]
2023 年 4 月: SeqTrack代碼現已發布。
2023 年 2 月: SeqTrack被 CVPR'23 接受
2022 年 9 月: X-CLIP現已整合到
2022 年 8 月: X-CLIP代碼現已發布。
2022 年 7 月: X-CLIP作為 Oral 被 ECCV'22 接受
2021 年 10 月: MS-2D-TAN代碼現已發布。
2021 年 9 月: MS-2D-TAN被 TPAMI'21 接受
2019 年 12 月: 2D-TAN代碼現已發布。
2019年11月: 2D-TAN被AAAI'20接受
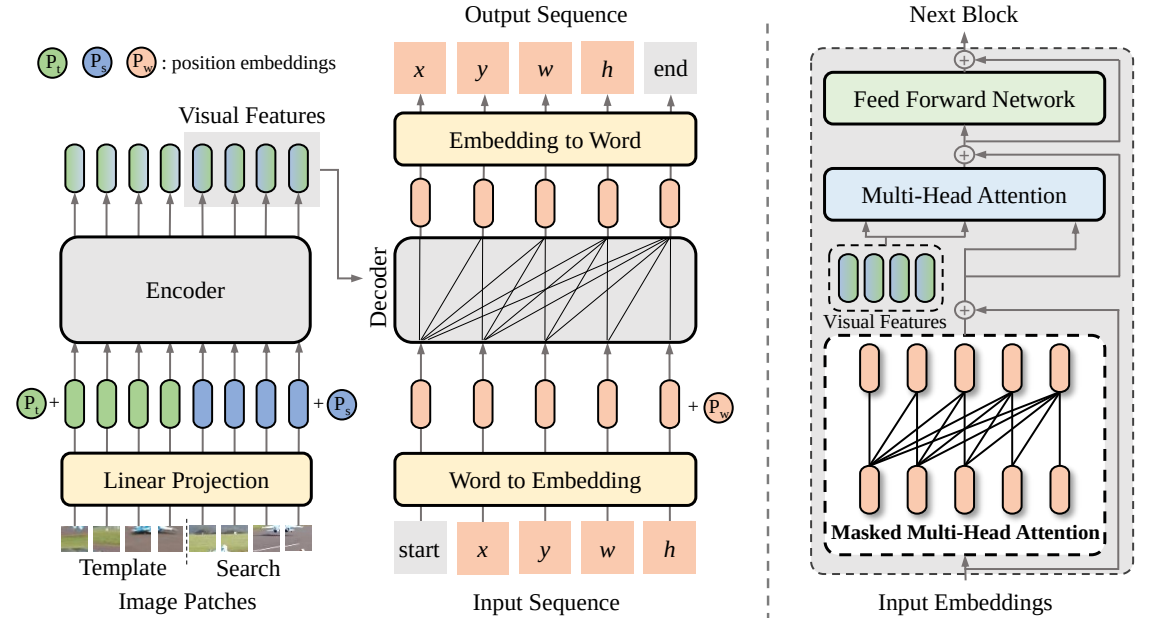
在本文中,我們提出了一種新的視覺追蹤序列到序列學習框架,稱為 SeqTrack。它將視覺追蹤視為序列生成問題,以自回歸方式預測物件邊界框。 SeqTrack僅採用簡單的編碼器-解碼器變壓器架構。編碼器使用雙向變換器提取視覺特徵,而解碼器使用因果解碼器自回歸產生一系列邊界框值。損失函數是一個簡單的交叉熵。這種序列學習範式不僅簡化了追蹤框架,而且在許多基準測試上實現了有競爭力的性能。
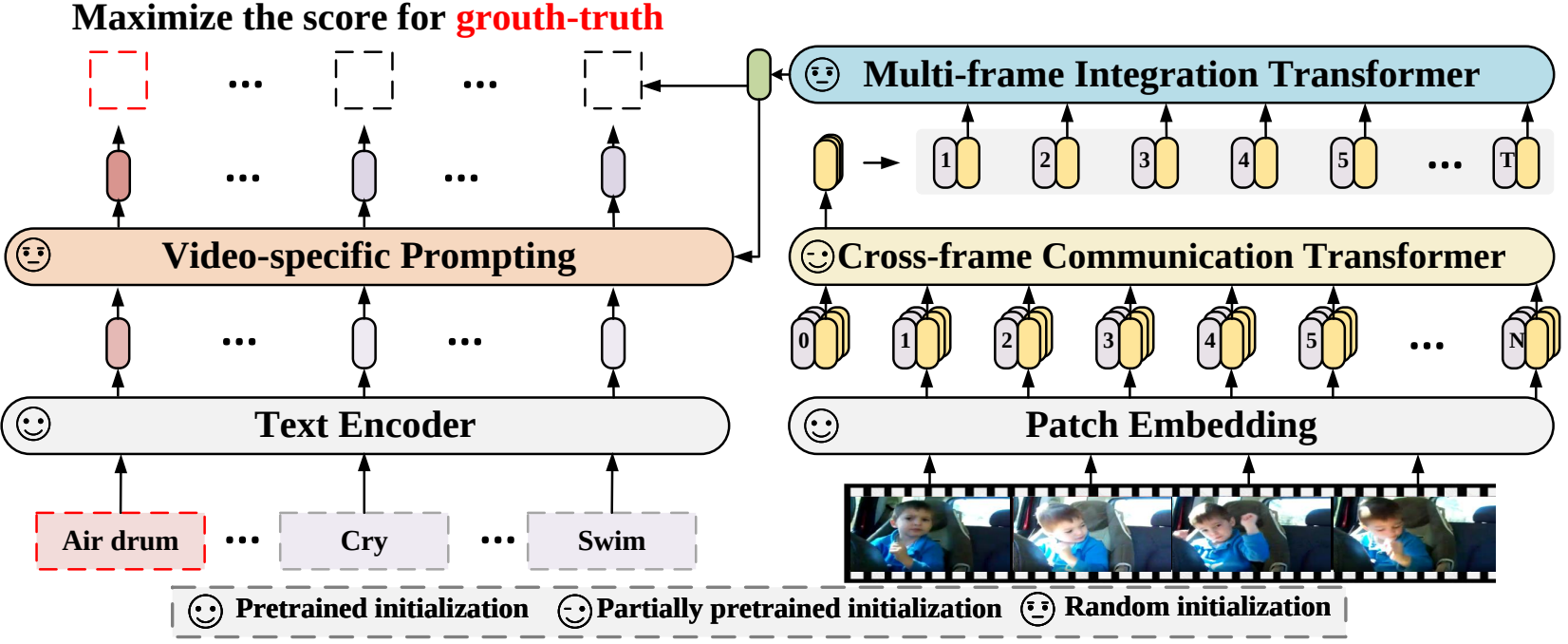
在本文中,我們提出了一種新的視訊辨識框架,該框架將預先訓練的語言影像模型應用於視訊辨識。具體來說,為了捕捉時間訊息,我們提出了一種跨幀注意機制,可以明確地跨幀交換資訊。為了利用影片類別中的文字訊息,我們設計了一種特定於影片的提示技術,該技術可以產生實例層級判別性文字表示。大量的實驗證明我們的方法是有效的,並且可以推廣到不同的影片辨識場景,包括完全監督、少樣本和零樣本。
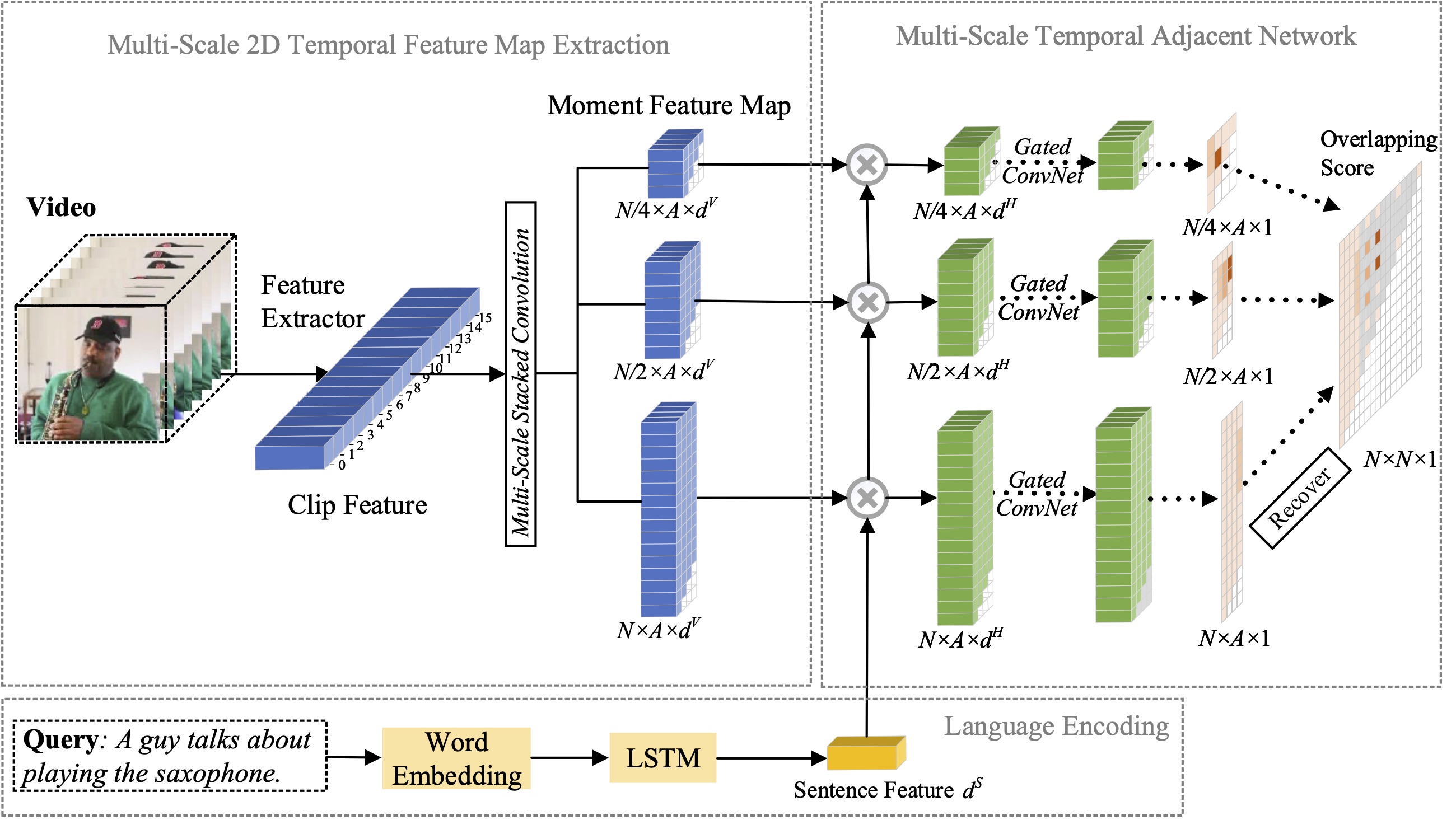
在本文中,我們研究了自然語言的矩定位問題,並提出將我們先前提出的 2D-TAN 方法擴展到多尺度版本。核心思想是從不同時間尺度的二維時間圖中檢索時刻,將相鄰候選時刻視為時間脈絡。擴展版本能夠對不同尺度的相鄰時間關係進行編碼,同時學習用於將視訊時刻與引用表達相匹配的判別特徵。我們的模型設計簡單,與三個基準資料集上最先進的方法相比,實現了具有競爭力的性能。
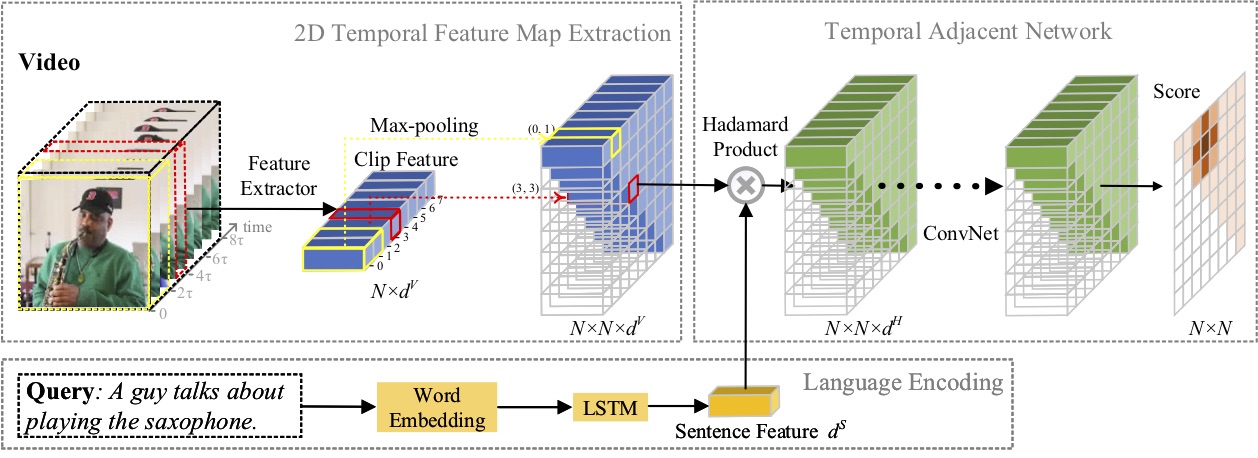
在本文中,我們研究了自然語言的矩定位問題,並提出了一種新穎的2D Temporal Adjacent Networks(2D-TAN)方法。核心思想是檢索二維時間圖上的時刻,它將相鄰候選時刻視為時間脈絡。 2D-TAN 能夠對相鄰時間關係進行編碼,同時學習用於將視訊時刻與參考表達進行匹配的判別特徵。我們的模型設計簡單,與三個基準資料集上最先進的方法相比,實現了具有競爭力的性能。
@InProceedings{SeqTrack,title={SeqTrack:視覺對象追蹤的序列到序列學習},作者={Chen,Xin and Peng,Houwen and Wang,Dong and Lu,Huchuan and Hu,Han},booktitle={CVPR}, year={2023}}@InProceedings{XCLIP, title={擴展用於通用視頻識別的語言-圖像預訓練模型},作者={Ni, Bolin and Peng, Houwen and Chen, Minghao and Zhu, Songyang and Meng, Summit and Fu ,建龍和項,石明和凌,海濱},書名={歐洲電腦視覺會議(ECCV)},年份={2022}}@InProceedings{Zhang2021MS2DTAN,
作者 = {張松陽、彭、侯文、付、建龍、陸、宜娟、羅傑波},
title = {用於自然語言矩定位的多尺度2D時間相鄰網路},
書名 = {TPAMI},
年 = {2021}}@InProceedings{2DTAN_2020_AAAI,
作者 = {張松陽、彭、侯文、付、建龍、羅、傑波},
title = {學習 2D 時態相鄰網路以使用自然語言進行時刻本地化},
書名 = {AAAI},
年 = {2020}}根據 MIT 許可證進行許可。


