horovod
v0.28.1: Build fixes (ROCm, GCC 12)
Horovod 是一個適用於 TensorFlow、Keras、PyTorch 和 Apache MXNet 的分散式深度學習訓練框架。 Horovod 的目標是讓分散式深度學習變得快速且易於使用。
Horovod 由 LF AI & Data Foundation(LF AI & Data)主辦。如果您是一家致力於在人工智慧、機器和深度學習領域使用開源技術的公司,並且希望支援這些領域的開源專案社區,請考慮加入 LF AI & Data Foundation。有關誰參與以及 Horovod 如何發揮作用的詳細信息,請閱讀 Linux 基金會公告。
內容
該專案的主要動機是讓單一 GPU 訓練腳本變得容易,並成功地將其擴展為跨多個 GPU 並行訓練。這有兩個面向:
在 Uber 內部,我們發現 MPI 模型比以前的解決方案(例如具有參數伺服器的分散式 TensorFlow)要簡單得多,並且需要的程式碼變更要少得多。一旦使用 Horovod 編寫了可擴展的訓練腳本,它就可以在單 GPU、多 GPU 甚至多主機上運行,而無需任何進一步的程式碼變更。有關更多詳細信息,請參閱“用法”部分。
除了易於使用之外,Horovod 的速度也很快。下面的圖表代表了在 128 台伺服器上完成的基準測試,這些伺服器配備 4 個 Pascal GPU,每個伺服器都透過支援 RoCE 的 25 Gbit/s 網路連接:
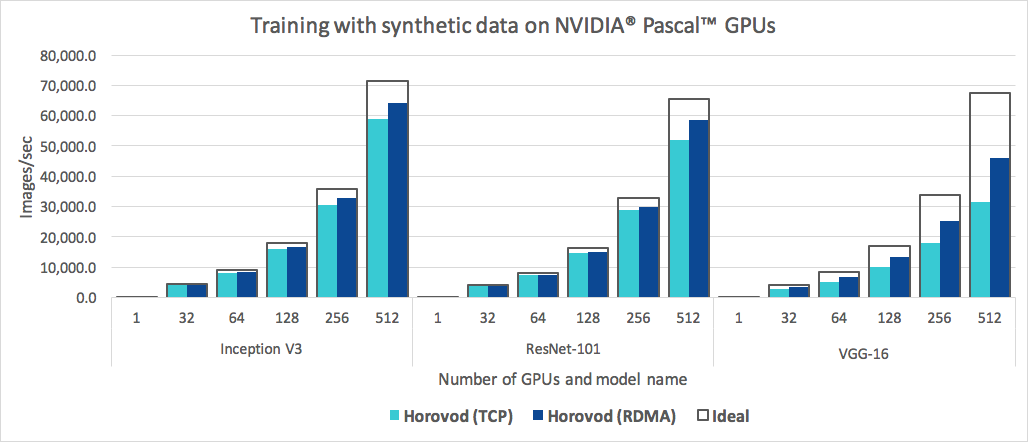
Horovod 對 Inception V3 和 ResNet-101 實現了 90% 的縮放效率,對 VGG-16 實現了 68% 的縮放效率。請參閱基準以了解如何重現這些數字。
雖然安裝 MPI 和 NCCL 本身可能看起來很麻煩,但處理基礎設施的團隊只需要完成一次,而公司中建造模型的其他人都可以享受大規模訓練模型的簡單性。
要在 Linux 或 macOS 上安裝 Horovod:
如果您從 PyPI 安裝了 TensorFlow,請確保安裝了g++-5或更高版本。從 TensorFlow 2.10 開始,需要使用符合 C++17 的編譯器(例如g++8或更高版本)。
如果您從 PyPI 安裝了 PyTorch,請確保安裝了g++-5或更高版本。
如果您已從 Conda 安裝了任一軟體包,請確保已安裝了gxx_linux-64 Conda 軟體包。
安裝horovod pip 軟體包。
要在 CPU 上運行:
$ pip install horovod若要使用 NCCL 在 GPU 上執行:
$ HOROVOD_GPU_OPERATIONS=NCCL pip install horovod有關安裝具有 GPU 支援的 Horovod 的更多詳細信息,請閱讀 GPU 上的 Horovod。
有關 Horovod 安裝選項的完整列表,請閱讀安裝指南。
如果您想使用 MPI,請閱讀 Horovod with MPI。
如果您想使用 Conda,請閱讀為 Horovod 建立具有 GPU 支援的 Conda 環境。
如果您想使用 Docker,請閱讀 Docker 中的 Horovod。
若要從原始程式碼編譯 Horovod,請按照貢獻者指南中的說明進行操作。
Horovod 核心原則是基於 MPI 概念,例如大小、等級、本地等級、 allreduce 、 allgather 、 broadcast和alltoall 。請參閱此頁面以了解更多詳細資訊。
請參閱以下頁面以了解 Horovod 範例和最佳實務:
要使用 Horovod,請在您的程式中添加以下內容:
hvd.init()來初始化 Horovod。將每個 GPU 固定到單一流程以避免資源爭用。
對於每個進程一個 GPU 的典型設置,將其設定為localrank 。伺服器上的第一個進程將分配第一個 GPU,第二個進程將分配第二個 GPU,依此類推。
根據工作人員數量調整學習率。
同步分散式訓練中的有效批次大小會根據工作人員數量進行縮放。學習率的增加可以補償批量大小的增加。
將優化器包裝在hvd.DistributedOptimizer中。
分散式最佳化器將梯度計算委託給原始最佳化器,使用allreduce或allgather平均梯度,然後套用這些平均梯度。
將初始變數狀態從 0 級廣播到所有其他進程。
當使用隨機權重開始訓練或從檢查點恢復訓練時,這是確保所有工作人員的一致初始化所必需的。
使用 TensorFlow v1 的範例(請參閱範例目錄以取得完整的訓練範例):
import tensorflow as tf
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf . ConfigProto ()
config . gpu_options . visible_device_list = str ( hvd . local_rank ())
# Build model...
loss = ...
opt = tf . train . AdagradOptimizer ( 0.01 * hvd . size ())
# Add Horovod Distributed Optimizer
opt = hvd . DistributedOptimizer ( opt )
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [ hvd . BroadcastGlobalVariablesHook ( 0 )]
# Make training operation
train_op = opt . minimize ( loss )
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd . rank () == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf . train . MonitoredTrainingSession ( checkpoint_dir = checkpoint_dir ,
config = config ,
hooks = hooks ) as mon_sess :
while not mon_sess . should_stop ():
# Perform synchronous training.
mon_sess . run ( train_op )下面的範例指令展示如何執行分散式訓練。請參閱運行 Horovod 以了解更多詳細信息,包括 RoCE/InfiniBand 調整和處理掛起的技巧。
要在具有 4 個 GPU 的電腦上執行:
$ horovodrun -np 4 -H localhost:4 python train.py要在 4 台機器上運行,每台機器有 4 個 GPU:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py若要在不使用horovodrun包裝器的情況下使用 Open MPI 運行,請參閱使用 Open MPI 運行 Horovod。
要在 Docker 中運行,請參閱 Docker 中的 Horovod。
要在 Kubernetes 上運行,請參閱 Helm Chart、Kubeflow MPI Operator、FfDL 和 Polyaxon。
要在 Spark 上運行,請參閱 Spark 上的 Horovod。
要在 Ray 上運行,請參閱 Horovod on Ray。
要在 Singularity 中運行,請參閱 Singularity。
若要在 LSF HPC 叢集(例如 Summit)中運行,請參閱 LSF。
要在 Hadoop Yarn 上運行,請參閱 TonY。
Gloo 是 Facebook 開發的開源集體通訊庫。
Gloo 包含在 Horovod 中,允許用戶無需安裝 MPI 即可運行 Horovod。
對於同時支援 MPI 和 Gloo 的環境,您可以透過將--gloo參數傳遞給horovodrun來選擇在運行時使用 Gloo :
$ horovodrun --gloo -np 2 python train.pyHorovod 支援 Horovod 集體與其他 MPI 函式庫(例如 mpi4py)混合和匹配,前提是 MPI 是使用多執行緒支援建構的。
您可以透過查詢hvd.mpi_threads_supported()函數來檢查 MPI 多執行緒支援。
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Verify that MPI multi-threading is supported.
assert hvd . mpi_threads_supported ()
from mpi4py import MPI
assert hvd . size () == MPI . COMM_WORLD . Get_size ()您也可以使用 mpi4py 子通訊器初始化 Horovod,在這種情況下,每個子通訊器將執行獨立的 Horovod 訓練。
from mpi4py import MPI
import horovod . tensorflow as hvd
# Split COMM_WORLD into subcommunicators
subcomm = MPI . COMM_WORLD . Split ( color = MPI . COMM_WORLD . rank % 2 ,
key = MPI . COMM_WORLD . rank )
# Initialize Horovod
hvd . init ( comm = subcomm )
print ( 'COMM_WORLD rank: %d, Horovod rank: %d' % ( MPI . COMM_WORLD . rank , hvd . rank ()))了解如何最佳化推理模型並從此處的圖表中刪除 Horovod 操作。
Horovod 的獨特之處之一是它能夠交錯通訊和運算,再加上批次小型allreduce作業的能力,從而提高效能。我們將這種批次功能稱為「張量融合」。
請參閱此處以了解完整詳細資訊和調整說明。
Horovod有能力記錄其活動的時間線,稱為Horovod時間線。
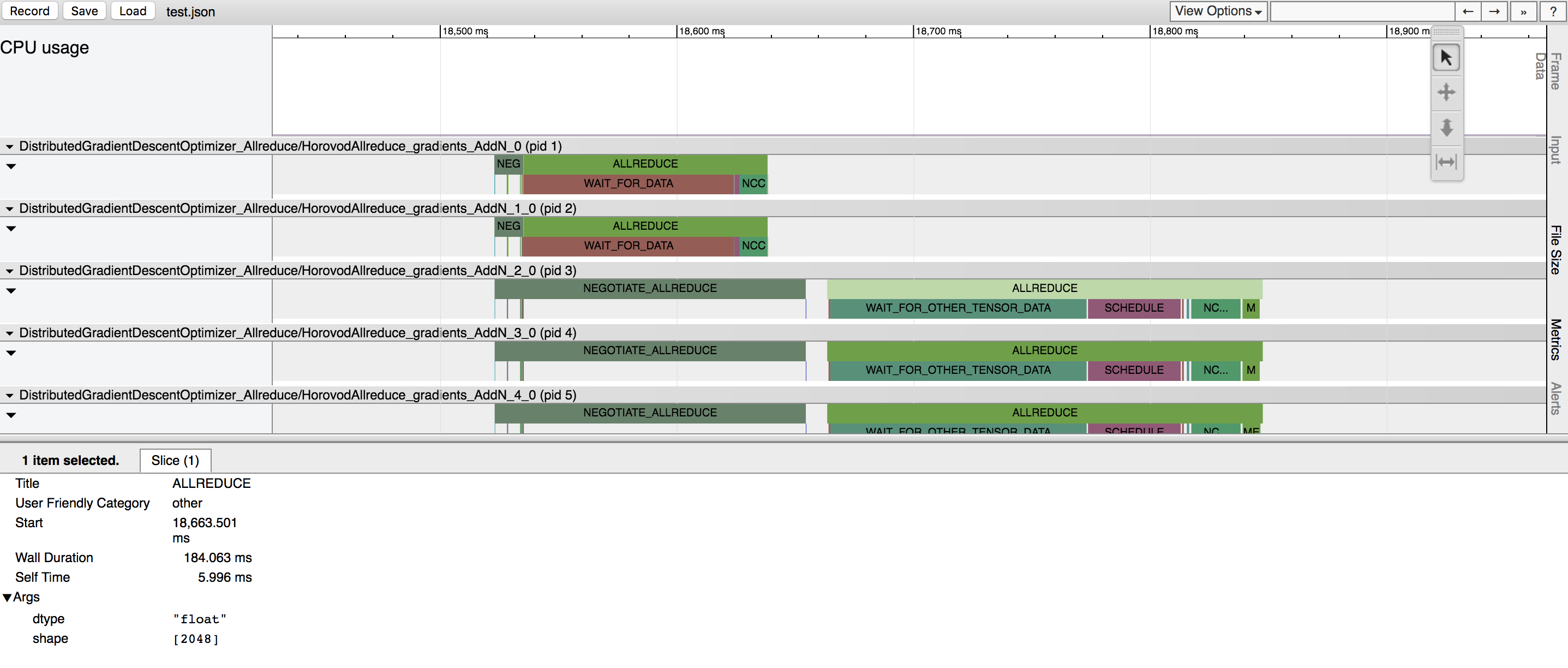
使用 Horovod 時間軸來分析 Horovod 表現。請參閱此處以了解完整詳細資訊和使用說明。
選擇正確的值來有效地利用 Tensor Fusion 和其他高級 Horovod 功能可能需要大量的試驗和錯誤。我們提供了一個稱為autotuning的系統來自動執行此效能最佳化過程,您可以使用horovodrun的單一命令列參數來啟用該系統。
請參閱此處以了解完整詳細資訊和使用說明。
Horovod 讓您在參與一次分散式訓練的不同進程組中同時執行不同的集體操作。設定hvd.process_set物件以利用此功能。
有關詳細說明,請參閱流程集。
向我們發送您想要在此網站上發布的任何用戶指南的鏈接
如果找不到答案,請參閱疑難排解並提交票證。
如果 Horovod 對您的研究有幫助,請在您的出版物中引用它:
@文章{sergeev2018horovod,
作者 = {亞歷山大·謝爾蓋耶夫和邁克·德爾·巴爾索},
期刊 = {arXiv 預印本 arXiv:1802.05799},
Title = {Horovod:{TensorFlow}中快速簡單的分散式深度學習},
年份 = {2018}
}
1. Sergeev, A.,Del Balso, M. (2017)認識 Horovod:Uber 的 TensorFlow 開源分散式深度學習架構。取自 https://eng.uber.com/horovod/
2.Sergeev, A. (2017) Horovod - 分散式 TensorFlow 變得簡單。取自 https://www.slideshare.net/AlexanderSergeev4/horovod-distributed-tensorflow-made-easy
3. Sergeev, A.,Del Balso, M. (2018) Horovod:TensorFlow 中快速且簡單的分散式深度學習。取自 arXiv:1802.05799
Horovod 原始碼是基於 Andrew Gibiansky 和 Joel Hestness 編寫的百度 tensorflow-allreduce 儲存庫。他們的原創工作在《將 HPC 技術引入深度學習》一文中進行了描述。


