PointLLM
1.0.0
 PointLLM:使大型語言模型能夠理解點雲
PointLLM:使大型語言模型能夠理解點雲潤森 徐小龍 王泰 王以倫 陳江苗 龐* 林大華
香港中文大學上海人工智慧實驗室浙江大學

點LLM上線了!請在 http://101.230.144.196 或 OpenXLab/PointLLM 嘗試。
您可以與 PointLLM 討論 Objaverse 資料集的模型或您自己的點雲!
如果您有任何反饋,請隨時告訴我們! ?
| 對話1 | 對話2 | 對話3 | 對話4 |
|---|---|---|---|
 |  |  |  |
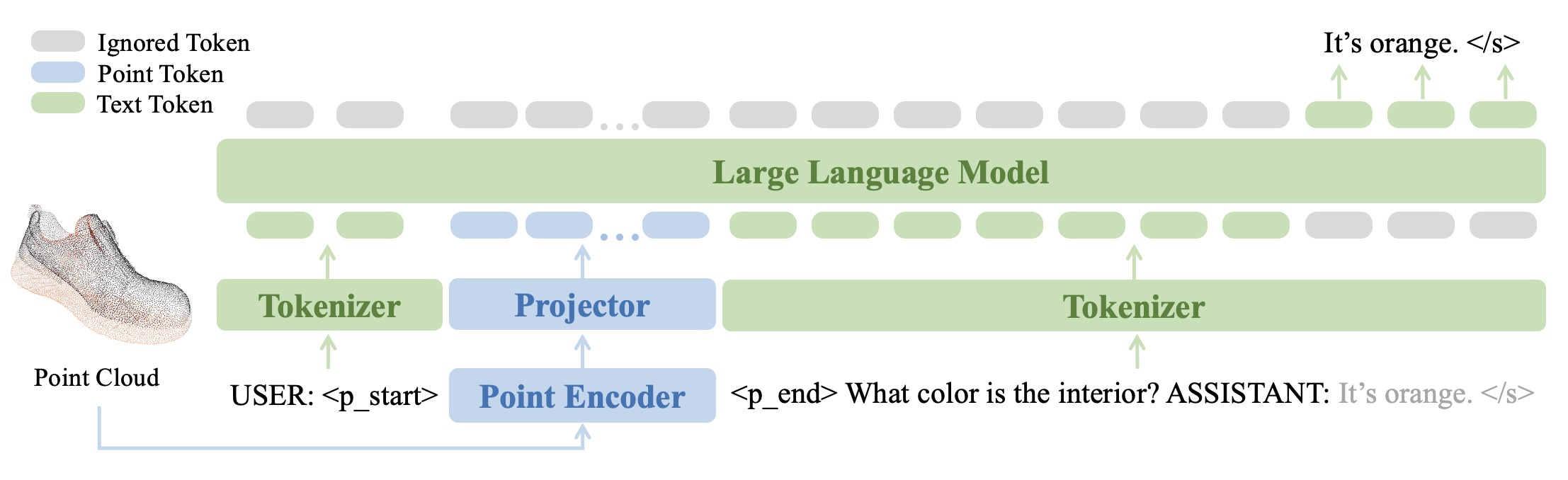
請參閱我們的論文以了解更多結果。
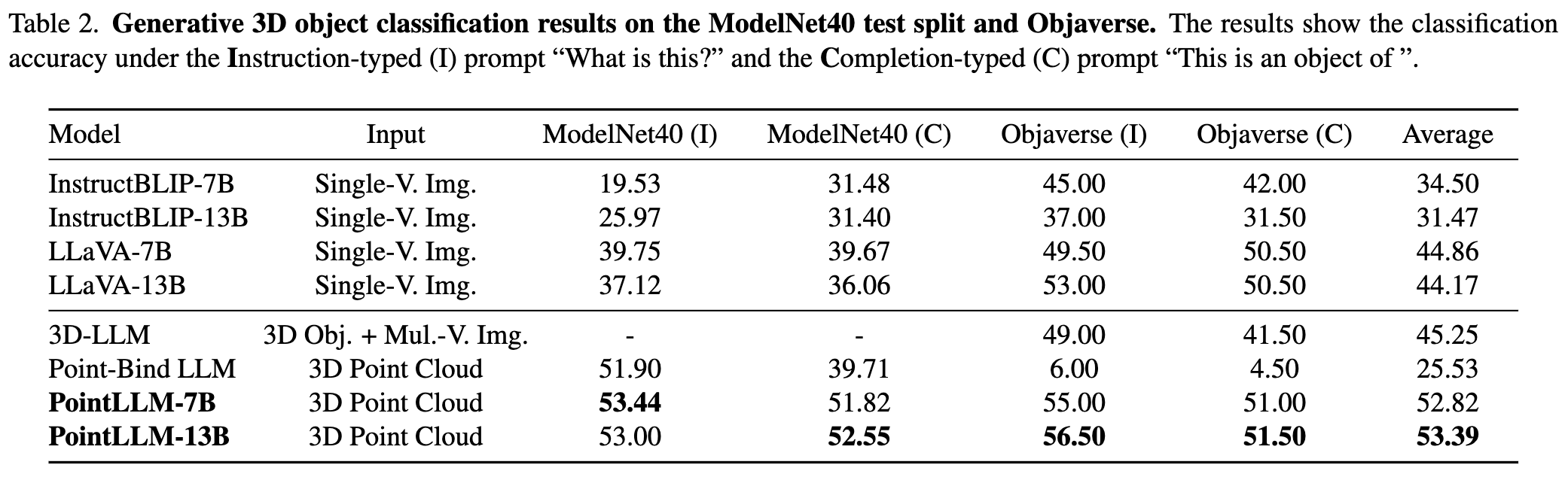
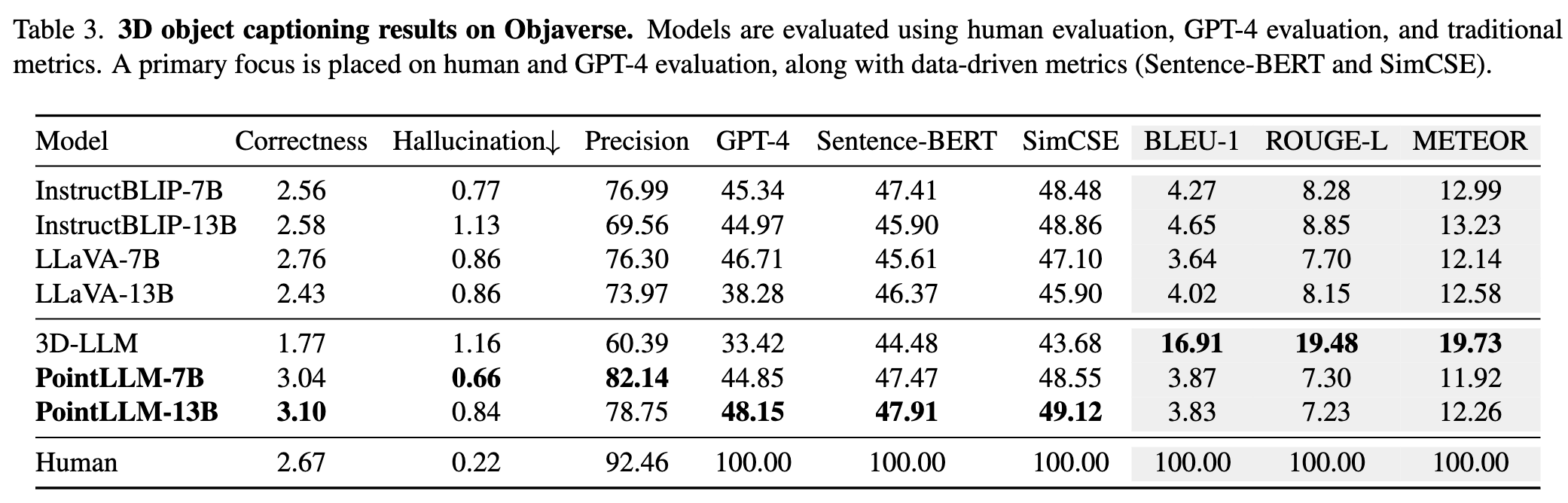
請參閱我們的論文以了解更多結果。

我們在以下環境下測試我們的程式碼:
開始:
git clone [email protected]:OpenRobotLab/PointLLM.git
cd PointLLMconda create -n pointllm python=3.10 -y
conda activate pointllm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# * for training
pip install ninja
pip install flash-attn8192_npy的資料夾,其中包含名為{Objaverse_ID}_8192.npy 660K 點雲檔案。每個檔案都是一個維度為 (8192, 6) 的 numpy 數組,其中前三個維度是xyz ,後三個維度是 [0, 1] 範圍內的rgb 。 cat Objaverse_660K_8192_npy_split_a * > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gzPointLLM資料夾中,建立一個資料夾data ,並在該目錄下建立一個指向未壓縮檔案的軟連結。 cd PointLLM
mkdir data
ln -s /path/to/8192_npy data/objaverse_dataPointLLM/data資料夾中,建立一個名為anno_data的目錄。anno_data目錄中。該目錄應如下所示: PointLLM/data/anno_data
├── PointLLM_brief_description_660K_filtered.json
├── PointLLM_brief_description_660K.json
└── PointLLM_complex_instruction_70K.jsonPointLLM_brief_description_660K_filtered.json是透過刪除我們保留作為驗證集的 3000 個物件從PointLLM_brief_description_660K.json中過濾出來的。如果您想重現我們論文中的結果,您應該使用PointLLM_brief_description_660K_filtered.json進行訓練。 PointLLM_complex_instruction_70K.json包含訓練集中的物件。pointllm/data/data_generation/system_prompt_gpt4_0613.txt 。 PointLLM_brief_description_val_200_GT.json ,並將其放入PointLLM/data/anno_data 。我們還提供了我們在訓練期間過濾的 3000 個物件 ID 以及它們相應的引用 GT,可用於對所有 3000 個物件進行評估。PointLLM/data中建立名為modelnet40_data的目錄。在此下載 ModelNet40 點雲modelnet40_test_8192pts_fps.dat的測試分割並將其放入PointLLM/data/modelnet40_data中。PointLLM資料夾中,建立一個名為checkpoints的目錄。checkpoints目錄中。 cd PointLLM
scripts/PointLLM_train_stage1.shscripts/PointLLM_train_stage2.sh通常情況下,您不必關心以下內容。它們僅用於重現我們 v1 論文 (PointLLM-v1.1) 中的結果。如果您想與我們的模型進行比較或使用我們的模型進行下游任務,請使用PointLLM-v1.2(參考我們的v2論文),它具有更好的效能。
PointLLM v1.1 和 v1.2 使用略有不同的預訓練點編碼器和投影機。如果要重現PointLLM v1.1,請編輯初始LLM和點編碼器權重目錄中的config.json文件,例如vim checkpoints/PointLLM_7B_v1.1_init/config.json 。
更改鍵"point_backbone_config_name"以指定另一個點編碼器配置:
# change from
" point_backbone_config_name " : " PointTransformer_8192point_2layer " # v1.2
# to
" point_backbone_config_name " : " PointTransformer_base_8192point " , # v1.1在scripts/train_stage1.sh中編輯點編碼器的檢查點路徑:
# change from
point_backbone_ckpt= $model_name_or_path /point_bert_v1.2.pt # v1.2
# to
point_backbone_ckpt= $model_name_or_path /point_bert_v1.1.pt # v1.1torch.float32資料類型啟動聊天機器人,以討論 Objaverse 的 3D 模型。模型檢查點將自動下載。您也可以手動下載模型檢查點並指定其路徑。這是一個例子: cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/PointLLM_chat.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data --torch_dtype float32您也可以輕鬆修改使用 Objaverse 以外的點雲的程式碼,只要輸入模型的點雲具有維度 (N, 6),其中前三個維度為xyz ,後三個維度為rgb (在[0, 1] 範圍內)。您可以對點雲進行採樣以獲得 8192 個點,因為我們的模型是在此類點雲上進行訓練的。
下表顯示了不同模型和資料類型的 GPU 要求。如果適用,我們建議使用torch.bfloat16 ,它在我們論文的實驗中使用。
| 模型 | 資料類型 | 顯存 |
|---|---|---|
| 點LLM-7B | 火炬.float16 | 14GB |
| 點LLM-7B | 火炬.float32 | 28GB |
| PointLLM-13B | 火炬.float16 | 26GB |
| PointLLM-13B | 火炬.float32 | 52GB |
cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/chat_gradio.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data cd PointLLM
export PYTHONPATH= $PWD
# Open Vocabulary Classification on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 # or --prompt_index 1
# Object captioning on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type captioning --prompt_index 2
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/eval_modelnet_cls.py --model_name RunsenXu/PointLLM_7B_v1.2 --prompt_index 0 # or --prompt_index 1{model_name}/evaluation中,格式如下: {
" prompt " : " " ,
" results " : [
{
" object_id " : " " ,
" ground_truth " : " " ,
" model_output " : " " ,
" label_name " : " " # only for classification on modelnet40
}
]
} cd PointLLM
export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
# Open Vocabulary Classification on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15
# Object captioning on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15Ctrl+C中斷評估過程。這將保存臨時結果。如果評估過程中發生錯誤,腳本也會儲存目前狀態。您可以透過再次執行相同的命令從中斷處恢復評估。{model_name}/evaluation中。部分指標解釋如下: " average_score " : The GPT-evaluated captioning score we report in our paper.
" accuracy " : The classification accuracy we report in our paper, including random choices made by ChatGPT when model outputs are vague or ambiguous and ChatGPT outputs " INVALID " .
" clean_accuracy " : The classification accuracy after removing those " INVALID " outputs.
" total_predictions " : The number of predictions.
" correct_predictions " : The number of correct predictions.
" invalid_responses " : The number of " INVALID " outputs by ChatGPT.
# Some other statistics for calling OpenAI API
" prompt_tokens " : The total number of tokens of the prompts for ChatGPT/GPT-4.
" completion_tokens " : The total number of tokens of the completion results from ChatGPT/GPT-4.
" GPT_cost " : The API cost of the whole evaluation process, in US Dollars ?.--start_eval標誌並指定--gpt_type在推理後立即開始評估。例如: python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 --start_eval --gpt_type gpt-4-0613python pointllm/eval/traditional_evaluator.py --results_path /path/to/model_captioning_output歡迎社區貢獻!如果您需要任何支持,請隨時提出問題或與我們聯絡。
如果您發現我們的工作和此程式碼庫有幫助,請考慮為該儲存庫加註星標?並引用:
@inproceedings { xu2024pointllm ,
title = { PointLLM: Empowering Large Language Models to Understand Point Clouds } ,
author = { Xu, Runsen and Wang, Xiaolong and Wang, Tai and Chen, Yilun and Pang, Jiangmiao and Lin, Dahua } ,
booktitle = { ECCV } ,
year = { 2024 }
}
本作品採用知識共享署名-非商業性-相同方式分享 4.0 國際授權。
讓我們一起讓 3D 法學碩士變得更偉大!


