StableDiffusionEndToEndGuide
1.0.0
我開始對使用 SD 生成軍事應用圖像感興趣。大部分資源取自 4chan 的 NSFW 版塊,因為 anons 使用 SD 製作無盡。有趣的是,規範的 SD WebUI 具有動漫/無盡圖像板的內建功能...DALL-E 之後 SD 的第一個用例就是生成動漫女孩,因此跳到無盡並不奇怪。
無論如何,這些怪人的技術適用於各種應用,尤其是 LoRA,它就像模型微調器。這個想法是與特定的 LoRA(例如,軍用車輛、飛機、武器等)合作,產生用於訓練視覺模型的合成圖像資料。訓練新的、有用的 LoRA 也很有趣。稍後的內容可能包括針對擾動進行修復。
Every link here may contain NSFW content, as most of the cutting-edge work on SD and LoRAs is with porn or hentai. So, please be wary when you are working with these resources. ALSO, Rentry.org pages are the main resources linked to in this guide. If any of the rentry pages do not work, change the .org to .co and the link should work. Otherwise, use the Wayback machine.
-TP
您實際上可以用 SD 做什麼? Huggingface 和其他一些公司在瀏覽器中為您提供了一些應用程式。和他們一起玩,看看它們的威力!在本指南中我們要做的是獲得完整的、可擴展的 WebUI,以便我們可以做任何我們想做的事情。
進入這個領域有點令人畏懼……但 4channers 做得很好,讓這個變得平易近人。以下是我採取的最簡單的步驟。您的目的是讓 Stable Diffusion WebUI(使用 Gradio 建置)在本機上運行,以便您可以開始提示和製作映像。
稍後我們將進行 Google Colab Pro 設置,這樣我們就可以在任何我們想要的任何裝置上運行 SD;但首先,讓我們在 PC 上設定 WebUI。您需要 16GB RAM、具有 2GB VRAM 的 GPU、Windows 7+ 和 20+GB 磁碟空間。
127.0.0.1:7860 (不要使用 Ctrl + C,因為此命令可以關閉 CLI)stable-diffusion-webuioutputstxt2img-images<date>git pull 
如果您使用的是 Windows,請完全忽略這一點。我也設法讓它在 Linux 上運行,儘管它有點複雜。我開始遵循這個指南,但它寫得相當糟糕,所以以下是我讓它在 Linux 中運行的步驟。我使用的是 Linux Mint 20,它是 Ubuntu 20 發行版。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitstable-diffusion-webui/models/Stable-diffusionsudo apt install python3 python3-pip python3-virtualenv wget git wget https://repo.anaconda.com/miniconda/Minconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
conda create --name sdwebui python=3.10.6conda activate sdwebui./webui.sh sudo apt update
sudo apt purge *nvidia*
sudo add-apt-repository ppa:graphics-drivers/ppasudo apt-get update更新sudo apt-get install nvidia-driver-530將其安裝在終端機中nvidia-smi ;如果成功,它應該會列印一個表格;如果沒有,它會說“無法連接到 GPU;請確保安裝了最新的驅動程式” sudo apt update
sudo apt install apt-transport-https ca-certificates gnupg
sudo apt install nvidia-cuda-toolkit
nvcc-version
python3 -c 'import venv'
python3 -m venv venv/
然後轉到/stable-diffusion-webui資料夾並運行:
rm -rf venv/
python3 -m venv venv/
在那之後,它對我有用。
提示中的單字順序會產生影響:較早的單字優先。一個好的提示的一般結構,來自這裡:
<general positives> <descriptors of subject> <descriptors of background> <post-processing, camera, etc.>
另一個很好的指南說提示應該遵循以下結構:
<subject> <medium> <style> <artist> <website> <resolution> <additional details> <color> <lighting>
關於提示工程 txt2img 模型的開創性論文,請參閱此處。有關 LLM 提示的權威資源,請按此處。
無論您提示什麼,請嘗試遵循某種結構,以便您的流程是可複製的。以下是必要的提示語法元素:
1girl standing on grass in front of castle AND castle in background 預設模型非常簡潔,但正如歷史上通常的情況一樣,性驅動了大多數事情。 NovelAI(NAI)是一家專注於動漫的 SD 內容生成服務,其主要模型被洩露。您看到的大多數 SD 生成的動漫男女圖像(無論是否是 NSFW)都來自這個洩漏的模型。
無論如何,它確實非常擅長生成人物,並且您將玩合併的大多數模型或 LoRA 都與它兼容,因為它們是在動漫圖像上進行訓練的。此外,人類還提供了一個非常好的起始用例,可以精確調整您想要用於專業目的的 LoRA。您將需要解決很多問題,並且大多數指南都是針對女性的圖像。稍後我們將介紹變數自動編碼器(VAE),它為模型帶來了真正的真實感。
stable-diffusion-webuimodelsStable-diffusion並選擇其中的模型後,您應該等待幾分鐘,CLI 會載入 VAE 權重低秩適應 (LoRA) 允許對給定模型進行微調。有關 LoRA 的更多資訊請參閱此處。在WebUI中,您可以將LoRA添加到模型中,就像錦上添花一樣。訓練新的 LoRA 也非常容易。還有其他「祖先」的微調方法(例如文字反轉和超網路),但 LoRA 是最先進的。
我將在整個指南中使用 LoRA 坦克。請注意,這不是一個很好的 LoRA,因為它適用於動漫風格的圖像,但玩起來還是不錯的。
stable-diffusion-webuiextensionssd-webui-additional-networksmodelslora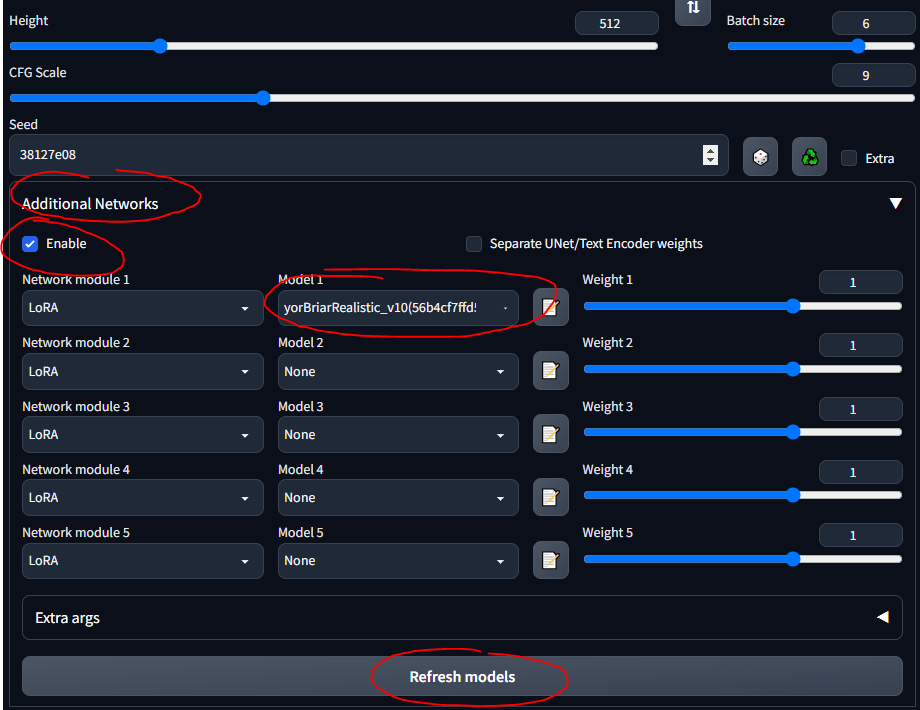
基於上一節...不同的模型有不同的訓練資料和訓練關鍵字...因此在某些模型上使用 booru 標籤效果不太好。以下是我玩過的一些模型以及它們的「說明」。
SDG Model Motherload,用於獲取大部分型號,我只是在這裡總結一下說明,以供快速參考;大多數模型都是針對真實色情的,我專注於現實的模型。點擊連結以查看範例提示、圖像以及使用它們的詳細說明。
CivitAI 用於獲取所有其他內容。您需要註冊一個帳戶,否則您將無法看到 NSFW 的物品,包括武器和軍事裝備。在 CivitAI 上,一些模型(檢查點)包含 VAE;如果有說明,請也下載它並將其放在模型旁邊。
可變自動編碼器可讓影像看起來更好、更清晰、更少過曝。有些還修復手和臉。但這主要是飽和度和陰影的問題。在這裡和這裡(NSFW)進行了解釋。常用的是NovelAI / Anything VAE。它基本上是模型的附加元件,就像 LoRA 一樣。
在 VAE 清單中尋找 VAE:
stable-diffusion-webuimodelsVAE中以下是我一路上學到的一些一般性註釋和有用的東西,不一定符合本指南的時間順序。
一個好的學習方法是在 CivitAI、AIbooru 或其他 SD 網站(4chan、Reddit 等)上瀏覽很酷的圖像,打開你喜歡的並將生成參數複製到 WebUI 中。全面披露:準確地重新創建圖像並不總是可能的,如此處所述。但通常你可以非常接近。要真正發揮作用,請將 CFG 調低,這樣模型就可以變得更有創意。嘗試分批次,然後離開電腦,回到批次挑選。
WebUI工作流程的一般流程是:
find/pick models/LoRAs -> txt2img (repeat, change params, etc.) -> img2img -> inpainting -> extra ->
有時您想返回提示而不貼上圖像或從頭開始編寫它們。您可以儲存提示以便在 WebUI 中重複使用它們。
本節或多或少是本指南資訊的摘要。
使用已存在的 SD 產生的圖像進行工作;也許有人將其發送給您,或者您想重新創建一個您製作的:
stable-diffusion-webuioutputstxt2img-images<date>中請注意,某些網站在上傳圖片時會刪除 PNG 元資料(例如 4chan),因此請尋找完整圖片的 URL 或使用保留 SD 元資料的網站,例如 CivitAI 或 AIbooru。
我時不時地犯一些錯誤。大多數記憶體不足 (VRAM) 錯誤可透過降低某些參數的值來修復。有時會恢復面孔和員工。修復設定可能會導致此問題。在檔案stable-diffusion-webuiwebui-user.bat中,在set COMMANDLINE_ARGS=行上,您可以放置一些修復常見錯誤的標誌。
--disable-nan-check--no-half--medvram或對於土豆計算機,添加--lowvram一個非常常見的問題源自於 Python 版本或 Torch 版本不正確。您將收到諸如“無法安裝 Torch”或“Torch 找不到 GPU”之類的錯誤。最簡單的修復是:
Python資料夾和Python/Scripts資料夾)stable-diffusion-webui資料夾中的venv資料夾stable-diffusion-webuiwebui-user.bat並讓它正確重新建置 venv所有命令列參數都可以在這裡找到。
有些擴充功能可以讓 WebUI 更好使用。取得 Github 鏈接,前往「擴充功能」選項卡,從 URL 安裝;或者,在“擴展”選項卡中,單擊“可用”,然後單擊“加載自”,您可以在本地瀏覽擴展,這反映了擴展 Github wiki。
現在您已經有了一些模型、LoRA 和提示...您如何進行測試以了解哪種效果最好?在「其他網路」窗格下方,有一個「腳本」下拉清單。在這裡,點擊 X/Y/Z 圖。在X類型中,選擇Checkpoint name;在 X 值中,按一下右側的按鈕以貼上所有模型。在 Y 類型中,嘗試 VAE,或種子,或 CFG 規模。無論您選擇什麼屬性,貼上(或輸入)您想要繪製圖表的值。例如,如果您有 5 個模型和 5 個 VAE,您將建立一個包含 25 個影像的網格,比較每個模型與每個 VAE 的輸出方式。這是非常通用的,可以幫助您決定使用什麼。請注意,如果您的 X 或 Y 軸是 VAE 模型,則必須為每個組合載入模型或 VAE 權重,因此可能需要一段時間。
可以在這裡找到關於 SD 比較的非常好的資源 (NSFW)。有很多連結可供關注。您可以開始了解各種模型、VAE、LoRA、參數值等如何影響影像生成。
我採用了這裡的測試提示,並使用 LoRA 坦克製作了這個 X/Y 網格。您可以看到各種模型和採樣器如何相互配合。從這個測試中,我們可以評估:

下面給出了每個坦克圖像所使用的確切參數(不包括模型或採樣器)(同樣,取自此處):
在本節中,您可以在熟悉使用 WebUI 的 txt2image 標籤中的模型、LoRA、VAE、提示、參數、腳本和擴充功能後可以執行的更進階操作。
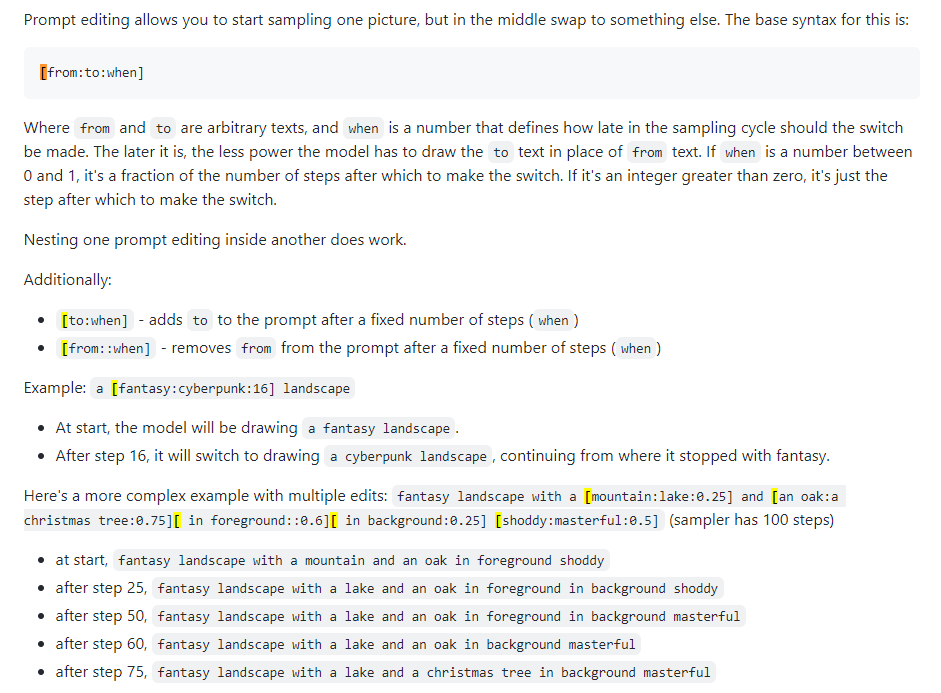
也稱為快速混合。提示編輯可讓您讓模型變更指定步驟的提示。下圖取自 4chan 帖子並描述了該技術。例如,如本指南所述,提示編輯可用於混合臉部。
Xformers,或交叉注意層。在 Nvidia GPU 上加速影像產生(以秒/迭代或 s/it 為單位)的方法,可以降低 VRAM 使用率,但會導致不確定性。僅當您擁有強大的 GPU 時才考慮這一點;事實上,您需要一台 Quadro。
不太常用,有點令人困惑的選項卡。可用於產生給定草圖的影像,例如 Huggingface Image to Image SD Playground 中。該選項卡有一個子選項卡“修復”,這是下一節的主題,也是 WebUI 的一項非常重要的功能。雖然您可以使用本節來產生您已經製作的更改後的圖像(輸出到stable-diffusion-webuioutputsimg2img-images ),但該功能對我來說很不穩定......它似乎使用了大量的內存並且我幾乎無法讓它工作。轉到下面的下一部分。
這就是內容創作者或對圖像擾動感興趣的人的力量所在。輸出位於stable-diffusion-webuioutputsimg2img-images中。
繪製是一個相當複雜的語意過程。外畫可以讓您拍攝影像並將其擴展任意多次,本質上是增加其邊界。此處描述了該過程。您一次只能將影像擴展 64 像素。有兩個用於此目的的 UI 工具(我可以找到):
此 WebUI 選項卡專門用於升級。如果您獲得了真正喜歡的圖像,可以在工作流程結束時在此處對其進行升級。升級後的影像儲存在stable-diffusion-webuioutputsextras-images中。在 txt2img 標籤中生成期間,與使用更強大的放大程式進行放大相關的一些記憶體問題(例如,4x+ 的圖像)不會在這裡發生,因為您沒有產生新圖像,而只是放大靜態圖像。
理解 ControlNet 功能的最佳方法就像是說「類固醇修復」。你給它一個輸入影像(SD 產生的或非 SD 產生的),它可以修改整個影像。 ControlNet 也可以實現姿勢。您可以為一個人提供一個參考姿勢,並根據您的典型提示產生相應的圖像。這裡是了解 ControlNet 的良好開端。
stable-diffusion-webuiextensionssd-webui-controlnetmodels

這一切都很好,但有時您需要更好的模型或 LoRA 來實現專業用例。由於大多數 SD 內容實際上是為了產生女性或色情內容,因此可能需要訓練特定模型和 LoRA。
請參閱有關 DreamBooth 的部分。
待辦事項
WebUI 中的檢查點合併標籤可讓您將兩個模型組合在一起,就像在鍋中混合兩種醬汁一樣,輸出是兩者組合的新醬汁。
待辦事項
訓練 LoRA 不一定很難,只是收集足夠資料的問題。
如果您必須遠離設備工作,這是重要的一步。 Google Colab Pro 每月 10 美元,為您提供 89 GB RAM 和優質 GPU,因此從技術上講,您可以透過手機運行提示,並讓它們在廷巴克圖的伺服器上為您工作。如果你不介意一點額外的費用,Google Colab Pro+ 每月 50 美元,甚至更好。
gdrive/MyDrive/sd/stable-diffusion-webui ,並且從這個基本資料夾中您可以使用您在本地中執行的相同資料夾結構內容網頁介面Google Colab 始終免費,您可以永久使用它,但速度可能有點慢。以每月 10 美元的價格升級到 Colab Pro 可為您提供更多功能。但每月 50 美元的 Colab Pro+ 才是真正的樂趣所在。即使關閉選項卡後,Pro+ 仍可讓您執行代碼 24 小時。
TODO當我將運行時 -> 運行時類型筆記本設定為高級 GPU 類別和高 RAM 時,我確實遇到了一個奇怪的錯誤,該錯誤破壞了我的 Pro 訂閱。這是因為 xFormers 不是基於 CUDA 支援建構的。這可以透過使用 TPU 或停用 xFormers 來解決,但我現在沒有耐心。嘗試 Colab 的問題。
MJ對於藝術家來說真的很好。它根本不像 WebUI 中的 SD 那樣可擴展或強大(NSFW 是不可能的),但您可以產生一些非常棒的東西。您可以在 MJ Discord 中免費使用它(在他們的網站上註冊)以獲得一些提示,或者每月支付 8 美元的基本計劃,之後您可以在您自己的私人伺服器中使用它。所有 Discord 指令都可以在這裡和這裡找到。 MJ 的提示符號結構為:
/imagine <optional image prompt> <prompt> --parameters
這些適用於 MJ V4,與 MJ 5 基本相同。
待辦事項
DreamStudio(不是 DreamBooth)是 Stability AI 公司的旗艦平台。他們的網站是一個平台,DreamBooth Studio,您可以從中產生圖像。就開放功能而言,它介於 Midjourney 和 WebUI 之間。 DreamBooth Studio 似乎建立在 invoke.ai 平台之上,您可以像 WebUI 一樣在本地安裝和運行。
待辦事項
Stable Horde 是一項社區努力,旨在讓每個人都可以免費使用穩定擴散。它本質上就像 Torrenting 或比特幣哈希一樣,每個人都貢獻一些 GPU 能力來產生 SD 內容。可以在此處存取部落應用程式。
待辦事項
DreamBooth(不是 DreamStudio)是 Google 實作的穩定擴散模型微調技術。簡而言之:您可以用它來用自己的圖片訓練模型。您可以直接從此處或此處使用它。當您實際訓練和序列化新模型時,它比僅僅下載模型並在 WebUI 中單擊要複雜得多。一些影片總結瞭如何做到這一點:
還有一些很好的指南:
DreamBooth 的 Google Colab:
還有一個模特兒訓練家叫EveryDream。可以在此處找到 DreamBooth 和 EveryDream 之間的完整比較。
待辦事項
從 2023 年 3 月左右開始,可以使用穩定擴散來產生影片。目前(2023 年 4 月),功能相當簡單,因為影片是從相似的圖像逐幀生成的,使影片具有「翻頁書」的外觀。您可以使用兩個主要的 WebUI 擴充功能:
我不太了解但需要研究的東西
您可以遵循一個流程來一遍又一遍地獲得良好的結果……這個流程會隨著時間的推移而完善。
chatgpt 整合?
外畫
達爾-E 2
deforum https://deforum.github.io/


