Q Bench
1.0.0
多模態法學碩士在低階電腦視覺方面表現如何?
吳浩寧1 * 、張子成2 * 、張二麗1 * 、陳超峰1 、廖亮1 、
王安南1 、李春怡2 、孫文秀3 、嚴瓊3 、翟廣濤2 、林偉思1 #
1南洋理工大學、 2上海交通大學、 3商湯研究院
*同等貢獻。 #通訊作者。
ICLR2024 聚焦
紙|項目頁面| GitHub |數據(LLVisionQA) |數據 (LLDescribe) |質衡 (Chinese-Q-Bench)


建議的 Q-Bench 包括低階視覺的三個領域:感知 (A1)、描述 (A2) 和評估 (A3)。
對於感知(A1)/描述(A2),我們收集了兩個基準資料集 LLVisionQA/LLDescribe。
我們願意對這兩項任務進行基於提交的評估。提交詳情如下。
對於評估 (A3),當我們使用公共資料集時,我們為任意 MLLM 提供了一個抽象評估程式碼,供任何人測試。
datasets API 一起使用對於Q-Bench-A1(帶有多項選擇題),我們已將它們轉換為HF格式的資料集,可以自動下載並與datasets API一起使用。請參考以下說明:
pip 安裝資料集
from datasets import load_datasetds = load_dataset("q-future/Q-Bench-HF")print(ds["dev"][0])### {'id': 0,### 'image': <PIL .JpegImagePlugin.JpegImageFile 圖片模式=RGB 大小=4160x3120>,### 'question': '這棟建築的照明怎麼樣? ',### 'option0': '高',### 'option1': '低',### '選項2': '中',### '選項3': '不適用',### 'question_type': 2,### 'question_concern': 3,### ' Correct_choice ':'B'} from datasets import load_datasetds = load_dataset("q-future/Q-Bench2-HF")print(ds["dev"][0])### {'id': 0,### 'image1': <PIL .Image.Image 映像模式=RGB size=4032x3024>,### 'image2': <PIL.JpegImagePlugin.JpegImageFile 映像模式=RGB size=864x1152>,### 'question': '# ,如何第二張圖片的清晰度是多少? ## ' option3': 'N/A',### 'question_type': 2,### 'question_concern': 0,### ' Correct_choice': 'B'}[2024/8/8] Q-bench+(也稱為Q-Bench2)的低階視覺比較任務部分剛被TPAMI接受!快來用 Q-bench+_Dataset 測試你的 MLLM。
[2024/8/1] Q-Bench已在VLMEvalKit 上發布,快來用“python run.py --data Q-Bench1_VAL Q-Bench1_TEST --model InternVL2-1B --verbose”這樣的命令測試您的LMM 。
[2024/6/17] Q-Bench 、 Q-Bench2 (Q-bench+)和A-Bench現已加入lmms-eval,這使得測試LMM變得更加容易!
[2024/6/3] A-Bench的 Github 倉庫上線。您想知道您的 LMM 是否是評估 AI 生成影像的高手嗎?快來A-Bench上測試一下吧!
[3/1] 我們在此發布Co-instruct ,走向開放式視覺品質比較。更多詳細資訊即將推出。
[2/27] 我們的工作Q-Insturct已被CVPR 2024接收,嘗試了解如何指導MLLM進行低階視覺的詳細資訊!
[2/23] Q-bench+的低階視覺比較任務部分現已在Q-bench+(資料集)發布!
[2/10] 我們正在發布擴展的 Q-bench+,它在低級視覺上用單圖像和圖像對挑戰 MLLM。排行榜現場,快來看看你最喜歡的MLLM的低階視力能力吧!更多詳細資訊即將推出。
[1/16] 我們的工作「Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision」被ICLR2024 接受為 Spotlight Present 。

我們測試了三個閉源API模型,GPT-4V-Turbo( gpt-4-vision-preview ,替換不再可用的舊版本GPT-4V 結果)、Gemini Pro( gemini-pro-vision )和 Qwen -VL -Plus ( qwen-vl-plus )。與舊版本相比略有改進,GPT-4V 仍然在所有 MLLM 中名列前茅,幾乎達到了初級人類的表現。 Gemini Pro 和 Qwen-VL-Plus 緊隨其後,仍然優於最好的開源 MLLM(總體為 0.65)。
[2024/7/18]更新,我們很高興發布BlueImage-GPT (閉源)的新SOTA效能。
感知,A1-單人
| 參加者姓名 | 是還是不是 | 什麼 | 如何 | 失真 | 其他的 | 情境扭曲 | 上下文中的其他人 | 全面的 |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus ( qwen-vl-plus ) | 0.7574 | 0.7325 | 0.5733 | 0.6488 | 0.7324 | 0.6867 | 0.7056 | 0.6893 |
BlueImage-GPT( from VIVO新冠軍) | 0.8467 | 0.8351 | 0.7469 | 0.7819 | 0.8594 | 0.7995 | 0.8240 | 0.8107 |
Gemini-Pro ( gemini-pro-vision ) | 0.7221 | 0.7300 | 0.6645 | 0.6530 | 0.7291 | 0.7082 | 0.7665 | 0.7058 |
GPT-4V-Turbo ( gpt-4-vision-preview ) | 0.7722 | 0.7839 | 0.6645 | 0.7101 | 0.7107 | 0.7936 | 0.7891 | 0.7410 |
| GPT-4V(舊版) | 0.7792 | 0.7918 | 0.6268 | 0.7058 | 0.7303 | 0.7466 | 0.7795 | 0.7336 |
| 人類-1-初級 | 0.8248 | 0.7939 | 0.6029 | 0.7562 | 0.7208 | 0.7637 | 0.7300 | 0.7431 |
| 人類-2-高級 | 0.8431 | 0.8894 | 0.7202 | 0.7965 | 0.7947 | 0.8390 | 0.8707 | 0.8174 |
感知,A1 對
| 參加者姓名 | 是還是不是 | 什麼 | 如何 | 失真 | 其他的 | 比較 | 聯合的 | 全面的 |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus ( qwen-vl-plus ) | 0.6685 | 0.5579 | 0.5991 | 0.6246 | 0.5877 | 0.6217 | 0.5920 | 0.6148 |
Qwen-VL-Max ( qwen-vl-max ) | 0.6765 | 0.6756 | 0.6535 | 0.6909 | 0.6118 | 0.6865 | 0.6129 | 0.6699 |
BlueImage-GPT( from VIVO新冠軍) | 0.8843 | 0.8033 | 0.7958 | 0.8464 | 0.8062 | 0.8462 | 0.7955 | 0.8348 |
Gemini-Pro ( gemini-pro-vision ) | 0.6578 | 0.5661 | 0.5674 | 0.6042 | 0.6055 | 0.6046 | 0.6044 | 0.6046 |
GPT-4V( gpt-4-vision ) | 0.7975 | 0.6949 | 0.8442 | 0.7732 | 0.7993 | 0.8100 | 0.6800 | 0.7807 |
| 初級人類 | 0.7811 | 0.7704 | 0.8233 | 0.7817 | 0.7722 | 0.8026 | 0.7639 | 0.8012 |
| 高階人力 | 0.8300 | 0.8481 | 0.8985 | 0.8313 | 0.9078 | 0.8655 | 0.8225 | 0.8548 |
我們最近也評估了幾個新的開源模型,並將很快發布他們的結果。
我們現在提供兩種下載資料集的方式(LLVisionQA&LLDescribe)
透過 GitHub 發布:請參閱我們的發布以了解詳細資訊。
透過 Huggingface 資料集:請參閱資料發布說明下載影像。
強烈建議將您的模型轉換為 Huggingface 格式,以便順利測試這些資料。請參閱 Huggingface 的 IDEFICS-9B-Instruct 的範例腳本作為範例,並針對您的自訂模型修改它們以在您的模型上進行測試。
請發送電子郵件至[email protected]以 json 格式提交您的結果。
您也可以將您的模型(可以是 Huggingface AutoModel 或 ModelScope AutoModel)連同您的自訂評估腳本一起提交給我們。您可以從適用於 LLaVA-v1.5(適用於 A1/A2)和此處(適用於影像品質評估)的範本腳本修改您的自訂腳本。
如果您不在中國大陸,請發送電子郵件至[email protected]提交您的模型。如果您在中國大陸,請發送電子郵件至[email protected]提交您的模型。
MLLM 低階感知能力的 LLVisionQA 基準資料集快照如下。請參閱此處的排行榜。
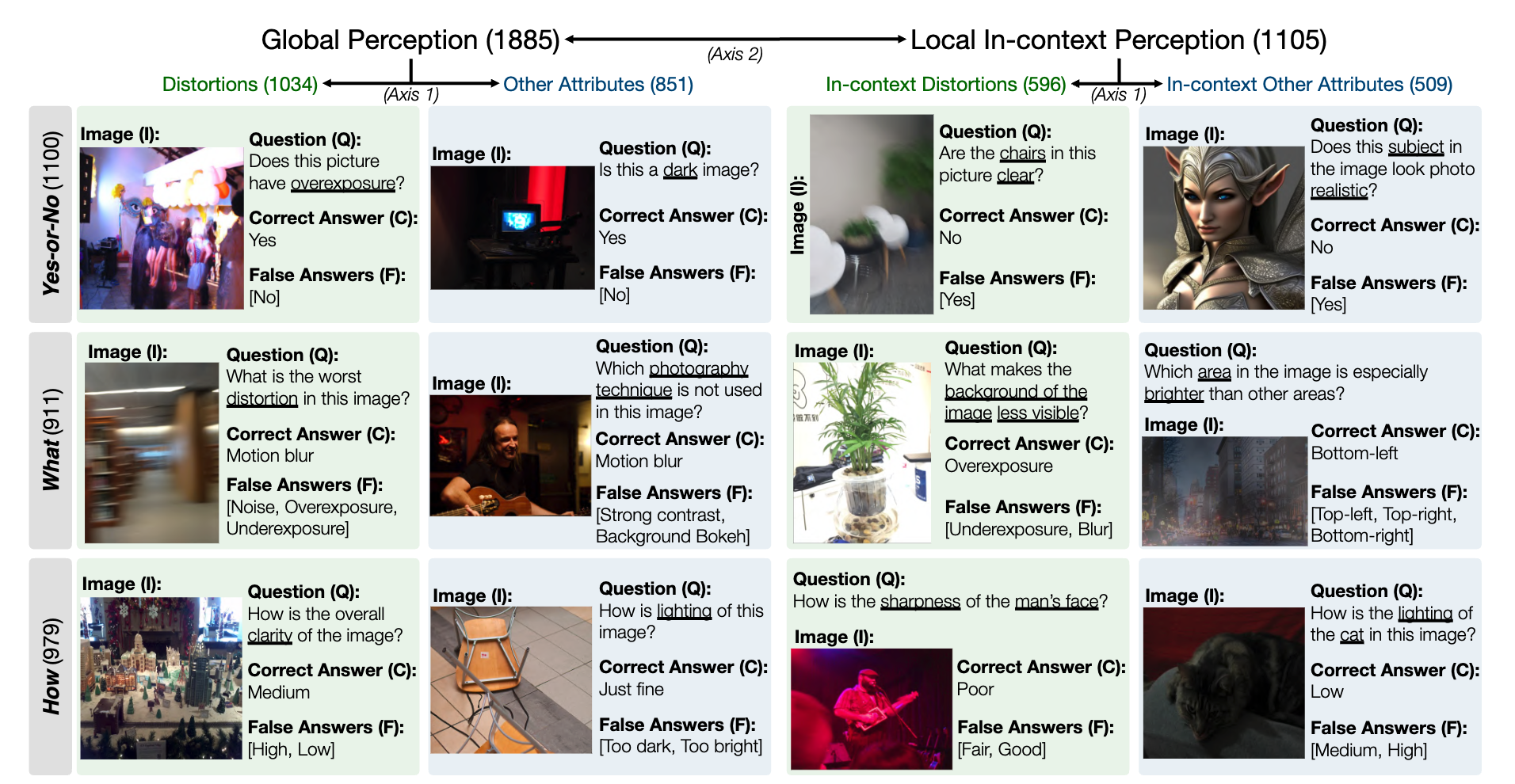
我們在這裡衡量 MLLM(提供問題和所有選擇)的答案準確性作為指標。
MLLM 低階描述能力的 LLDescribe 基準資料集快照如下。請參閱此處的排行榜。

我們衡量 MLLM 描述的完整性、精確性和相關性作為此處的指標。
MLLM 能夠預測 IQA 的定量分數,這是一項令人興奮的能力!
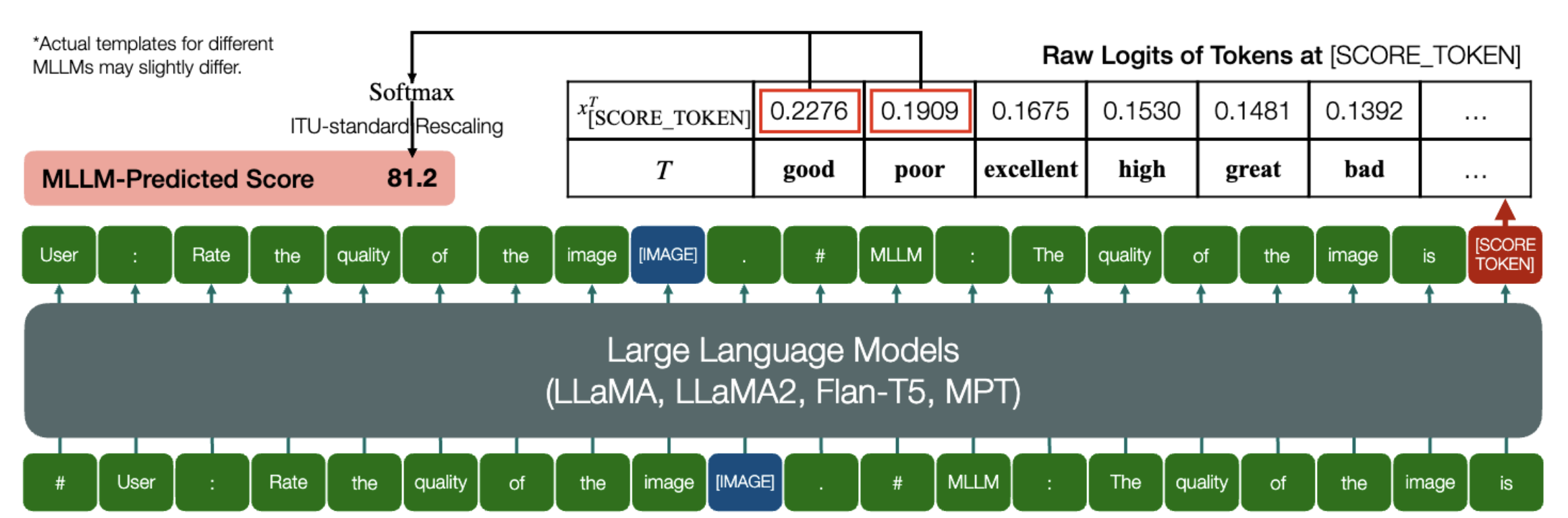
與上面類似,只要一個模型(基於因果語言模型)具有以下兩個方法: embed_image_and_text (允許多模態輸入)和forward (用於計算logits),就可以用該模型進行圖像品質評估(IQA)可以通過如下方式實現:
from PIL import Imagefrom my_mllm_model import Model, Tokenizer, embed_image_and_textmodel, tokenizer = Model(), Tokenizer()prompt = "##User: 評價影像的品質.n"
"##Assistant: 影像品質為" ### 這行可以根據 MLLM 的預設行為進行修改。 image_for_iqa.jpg")input_embeds = embed_image_and_text(圖像,提示)output_logits = model(input_embeds=input_embeds).logits[0,-1]q_pred = (output_logits[[good_idx, 100,-1]q_pred = (output_logits[[good_idx, 100] 0]*請注意,您可以根據模型的預設格式修改第二行,例如對於Shikra,「##Assistant:圖像的品質是」修改為「##Assistant:答案是」。如果您的 MLLM 首先回答“好的,我想幫忙!圖像品質是”,沒關係,只需將其替換為提示的第 2 行即可。
我們進一步在 IQA 上提供 IDEFICS 的全面實施。請參閱有關如何使用此 MLLM 運行 IQA 的範例。其他 MLLM 也可以以相同的方式修改以用於 IQA。
我們為我們的基準測試中評估的七個 IQA 資料庫準備了 JSON 格式的人類意見評分 (MOS)。
詳細資訊請參閱IQA_databases。
移至排行榜。請點擊查看詳情。
如有疑問,請聯絡本文的第一作者。
吳浩寧, [email protected] ,@teowu
張子成, [email protected] , @zzc-1998
張二麗, [email protected] ,@ZhangErliCarl
如果您發現我們的工作有趣,請隨時引用我們的論文:
@inproceedings{wu2024qbench,author = {吳、浩寧和張、子成和張、二里和陳、朝風和廖、樑和王、安南和李、春一和孫、文秀和嚴、瓊和翟、廣濤和林, Weisi},title = {Q-Bench: 低水平視覺通用基礎模型的基準},booktitle = {ICLR},year = {2024}} 

