LLM PuzzleTest
1.0.0
PuzzleVQA,我們的新資料集揭示了多模式法學碩士在理解簡單抽像模式方面面臨的嚴峻挑戰。紙|網站
我們正在發布 AlgoPuzzleVQA,這是一個新穎且具有挑戰性的多模態推理資料集!很快,我們將發布更多多模式拼圖資料集。敬請關注!紙|網站
我們很高興地宣布發布兩個以謎題為中心的新穎 VQA 資料集:
MLLM 在兩個資料集上的表現都明顯不足,這凸顯了對其多模態推理能力進行實質增強的迫切需求。
大型多模態模型透過整合多模態理解能力擴展了大型語言模型的令人印象深刻的功能。然而,目前尚不清楚它們如何模仿人類的一般智力和推理能力。由於辨識模式和抽象概念是通用智慧的關鍵,因此我們推出了 PuzzleVQA,這是一組基於抽像模式的謎題。透過此資料集,我們根據基本概念(包括顏色、數字、大小和形狀)評估具有抽像模式的大型多模態模型。透過我們對最先進的大型多模態模型的實驗,我們發現它們無法很好地推廣到簡單的抽像模式。值得注意的是,即使是 GPT-4V 也無法解決一半以上的難題。為了診斷大型多模態模型中的推理挑戰,我們逐步以視覺感知、歸納推理和演繹推理的真實推理解釋來指導模型。我們的系統分析發現,GPT-4V的主要瓶頸是視覺感知和歸納推理能力較弱。透過這項工作,我們希望闡明大型多模態模型的局限性以及它們如何在未來更好地模擬人類認知過程。
PuzzleVQA 可在此處和 Huggingface 上使用。
下圖顯示了一個涉及 PuzzleVQA 中顏色概念的範例問題,以及 GPT-4V 中的錯誤答案。解決過程中通常可以觀察到三個階段:視覺感知(藍色)、歸納推理(綠色)和演繹推理(紅色)。這裡,視覺感知不完整,導致演繹推理時出現錯誤。

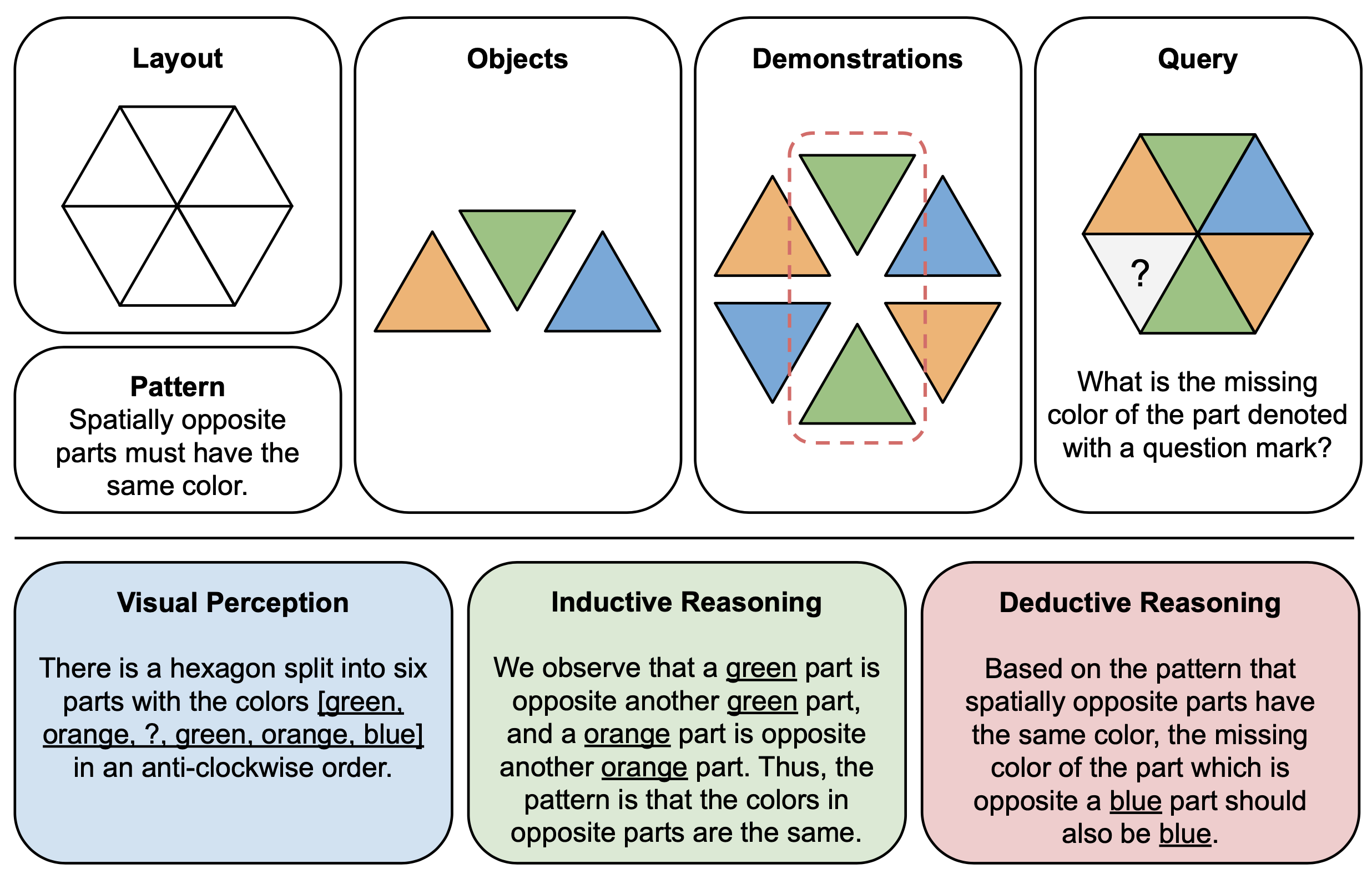
下圖顯示了 PuzzleVQA 中抽象謎題的組件(頂部)和推理解釋(底部)的圖示範例。為了建立每個拼圖實例,我們首先定義多模式模板的佈局和模式,並使用演示底層模式的合適物件填充模板。為了可解釋性,我們也建構了基本事實推理解釋來解釋難題並解釋一般解決方案階段。
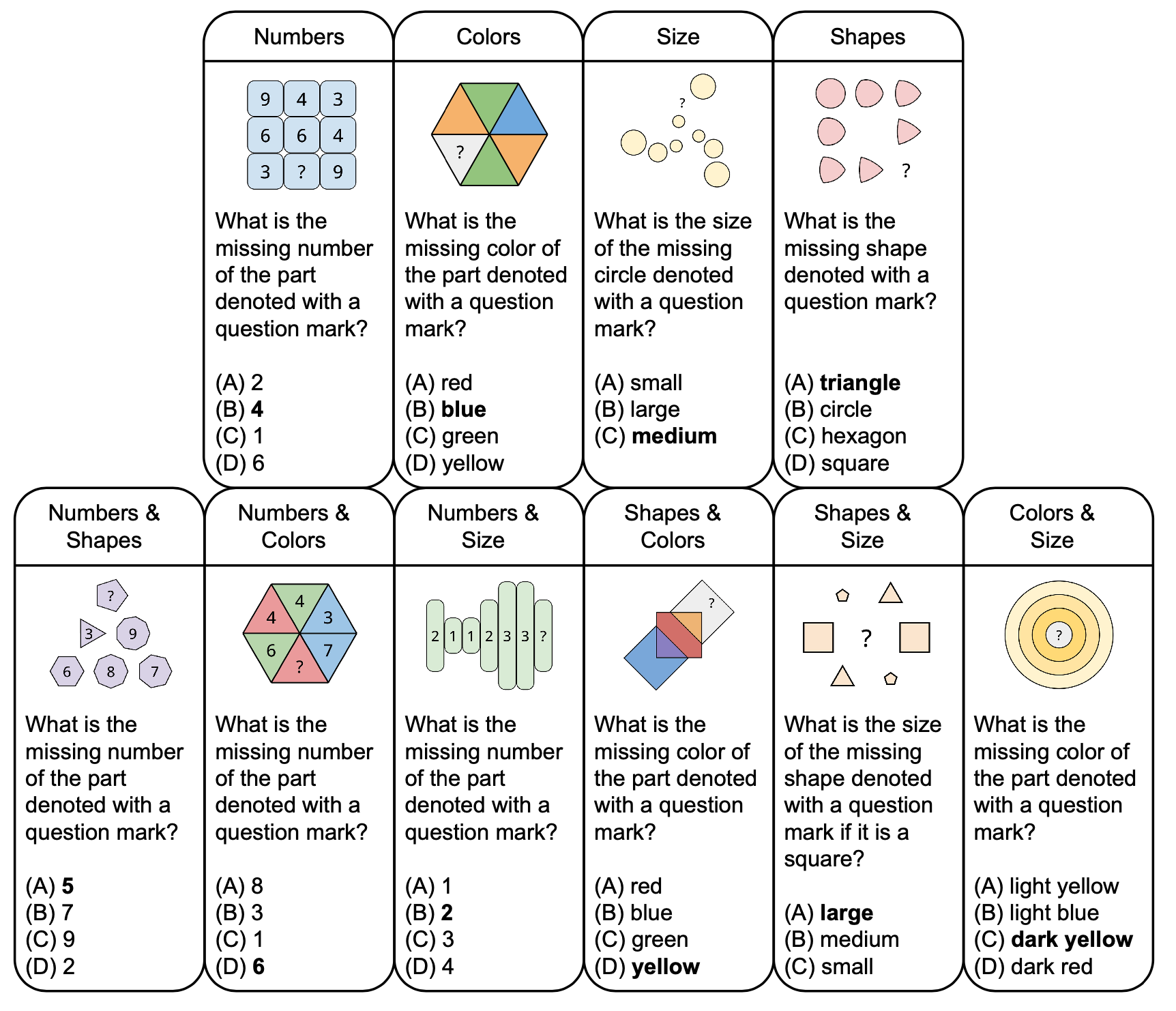
下圖顯示了 PuzzleVQA 中抽象謎題的分類,其中包含範例問題,基於顏色和大小等基本概念。為了增強多樣性,我們設計了單概念和雙概念謎題。
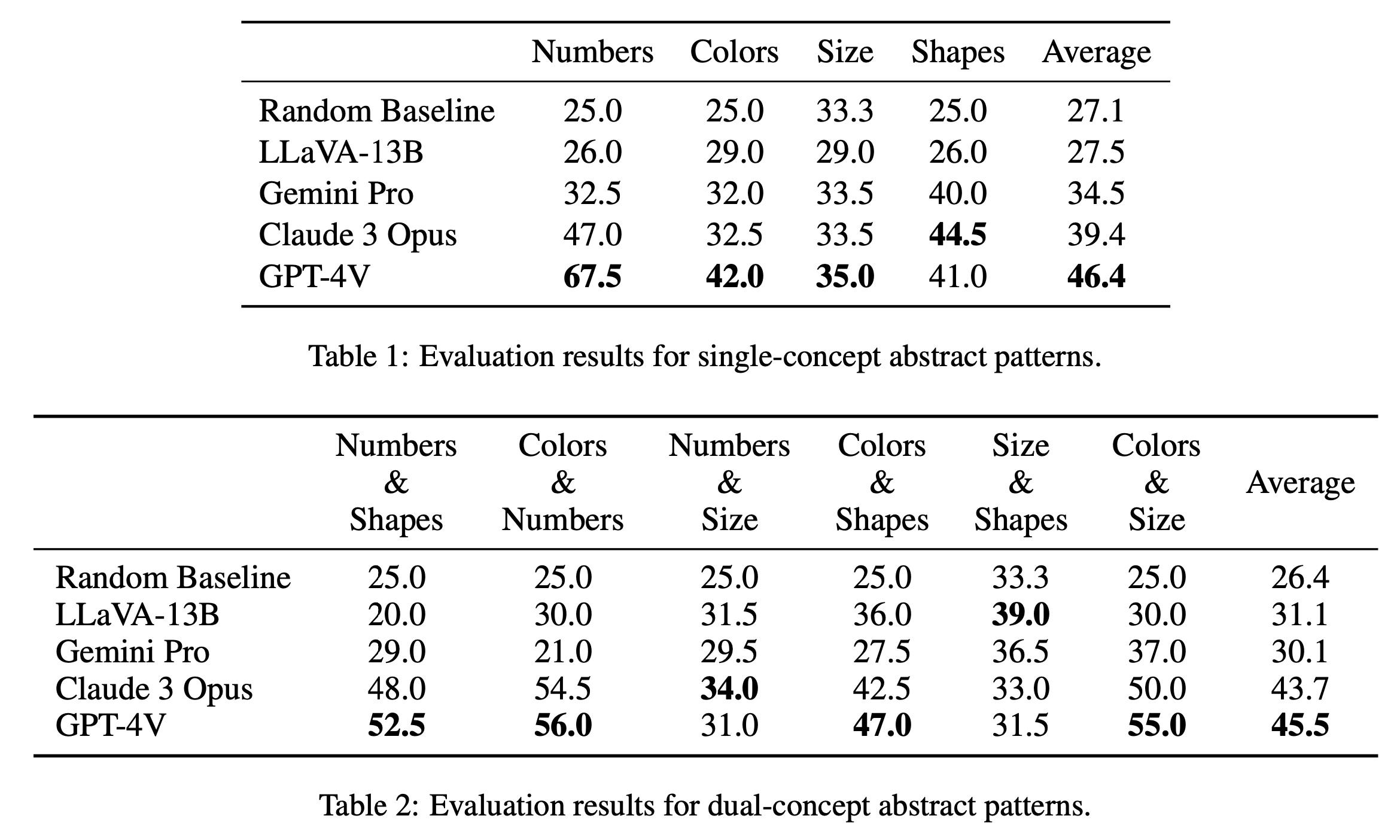
我們分別在表1和表2中報告了單概念和雙概念謎題的主要評估結果。單一概念謎題的評估結果如表 1 所示,揭示了開源模型和閉源模型之間的表現顯著差異。 GPT-4V 以 46.4 的最高平均分數脫穎而出,在數字、顏色和大小等單一概念謎題上展示了卓越的抽像模式推理能力。它特別在「數字」類別中表現出色,得分為 67.5,遠遠超過其他模型,這可能是由於它在數學推理任務中的優勢(Yang et al., 2023)。 《Claude 3 Opus》以 39.4 的總平均分緊隨其後,以 44.5 的最高分顯示了其在「形狀」類別中的實力。其他模型(包括 Gemini Pro 和 LLaVA-13B)落後於平均分數分別為 34.5 和 27.5,在幾個類別上的表現與隨機基線類似。
在雙概念拼圖的評測中,如表2所示,GPT-4V再次脫穎而出,平均分數高達45.5。它在“顏色和數字”和“顏色和尺寸”等類別中表現尤其出色,得分分別為 56.0 和 55.0。 Claude 3 Opus 緊隨其後,平均分為 43.7,在“Numbers & Size”中表現強勁,最高分為 34.0。有趣的是,LLaVA-13B 儘管總體平均值較低,為 31.1,但在「尺寸和形狀」類別中得分最高,為 39.0。另一方面,Gemini Pro 的各類別表現較為均衡,但整體平均值略低,為 30.1。總體而言,我們發現模型對於單概念和雙概念模式的平均表現相似,這表明它們能夠將顏色和數字等多個概念聯繫在一起。
@misc{chia2024puzzlevqa,
title={PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns},
author={Yew Ken Chia and Vernon Toh Yan Han and Deepanway Ghosal and Lidong Bing and Soujanya Poria},
year={2024},
eprint={2403.13315},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
我們介紹了在視覺問答的背景下解決多模式謎題的新穎任務。我們提出了一個新的資料集 AlgoPuzzleVQA,旨在挑戰和評估多模態語言模型解決演算法難題的能力,這些演算法需要視覺理解、語言理解和複雜的演算法推理。我們創建的謎題涵蓋了各種數學和演算法主題,例如布林邏輯、組合學、圖論、優化、搜尋等,旨在評估視覺數據解釋和演算法解決問題技能之間的差距。該資料集是根據人類編寫的程式碼自動產生的。我們所有的謎題都有精確的解決方案,可以從演算法中找到,無需繁瑣的人工計算。它確保我們的資料集可以在推理複雜性和資料集大小方面任意擴展。我們的調查表明,GPT4V 和 Gemini 等大型語言模型 (LLM) 在解謎任務中表現有限。我們發現,在針對大量謎題的多項選擇問答設定中,他們的表現幾乎是隨機的。研究結果強調了整合視覺、語言和演算法知識來解決複雜推理問題的挑戰。
PuzzleVQA 可在此處和 Huggingface 上使用。
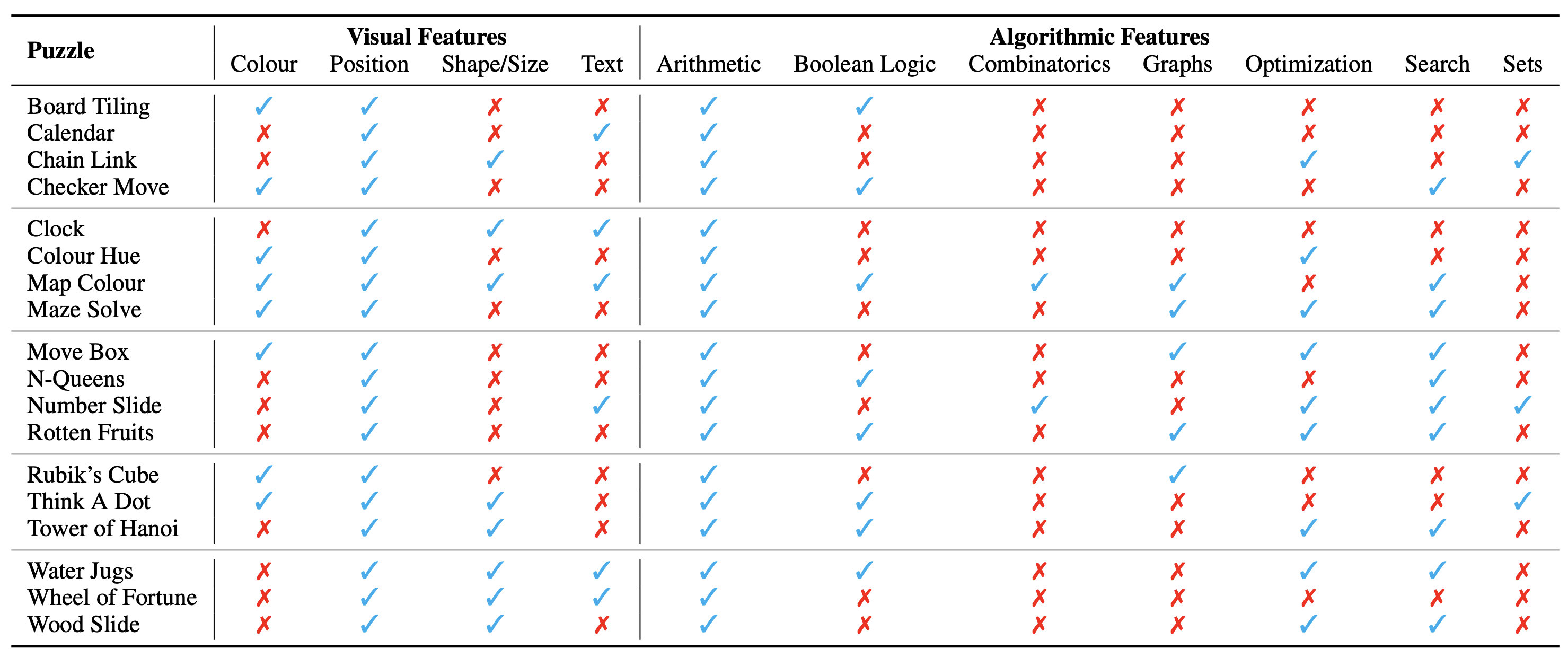
謎題/問題的配置顯示為圖像,構成其視覺上下文。我們確定了影響謎題性質的視覺環境的以下基本面向:

我們也確定了解決謎題所需的演算法概念,即回答謎題實例的問題。它們如下:

演算法類別並不互相排斥,因為我們需要使用兩個或更多類別來得出大多數謎題的答案。
資料集可在此處以這些格式取得。我們總共創建了 18 個不同的謎題,涵蓋各種演算法和數學主題。其中許多謎題在各種娛樂或學術環境中都很流行。
總共,我們有 18 個不同謎題的 1800 個實例。這些實例類似於謎題的不同測試案例,即它們具有不同的輸入組合、初始狀態和目標狀態等。這類似於我們如何驗證旨在透過廣泛的測試案例解決特定任務的電腦程式的準確性。
我們目前將完整資料集視為僅評估基準。這裡顯示了所有謎題的詳細範例。
可以在此處找到生成資料集的說明。實例的數量和謎題的難度可以任意縮放到任何所需的大小或層級。
謎題的本體分類如下:
實驗設定和腳本可以在 AlgoPuzzleVQA 目錄中找到。
如果您發現我們的工作有用,請考慮引用以下文章:
@article { ghosal2024algopuzzlevqa ,
title = { Are Language Models Puzzle Prodigies? Algorithmic Puzzles Unveil Serious Challenges in Multimodal Reasoning } ,
author = { Ghosal, Deepanway and Han, Vernon Toh Yan and Chia, Yew Ken and and Poria, Soujanya } ,
journal = { arXiv preprint arXiv:2403.03864 } ,
year = { 2024 }
}

