bida
v0.9.4
pip install -U bida from bida import ChatLLM
llm = ChatLLM (
model_type = 'openai' , # 调用openai的chat模型
model_name = 'gpt-4' ) # 设定模型为:gpt-4,默认是gpt3.5
result = llm . chat ( "从1加到100等于多少?只计算奇数相加呢?" )
print ( result ) from bida import ChatLLM
llm = ChatLLM (
model_type = "baidu" , # 调用百度文心一言
stream_callback = ChatLLM . stream_callback_func ) # 使用默认的流式输出函数
llm . chat ( "你好呀,请问你是谁?" ) | 模型公司 | 模型類型 | 模型名稱 | 是否支持 | 說明 |
|---|---|---|---|---|
| OpenAI | Chat | gpt-3.5,gpt-4 | √ | 支援gpt3.5和gpt4全部模型 |
| Text Completion | text-davinci-003 | √ | Text 生成類別模型 | |
| Embeddings | text-embedding-ada-002 | √ | 向量化模型 | |
| 百度-文心一言 | Chat | ernie-bot, ernie-bot-turbo | √ | 百度商用Chat模型 |
| Embeddings | embedding_v1 | √ | 百度商用向量化模型 | |
| 託管模型 | 各類開源模型 | √ | 百度託管的各類開源模型,請使用百度第三方模型接取協定自行配置,詳見下文的模型接取章節 | |
| 阿里雲-通義千問 | Chat | qwen-v1, qwen-plus-v1, qwen-7b-chat-v1 | √ | 阿里雲商用與開源Chat模型 |
| Embeddings | text-embedding-v1 | √ | 阿里雲商用向量化模型 | |
| 託管模型 | 各類開源模型 | √ | 阿里雲託管的其他各類開源模型,請使用阿里雲第三方模型接取協定自行配置,詳見下文的模型接取章節 | |
| MiniMax | Chat | abab5, abab5.5 | √ | MiniMax商用Chat模型 |
| Chat Pro | abab5.5 | √ | MiniMax商用Chat模型, 採用自訂Chatcompletion pro模式,支援多人多bot對話場景,範例對話,返回格式限制,函數調用,插件等功能 | |
| Embeddings | embo-01 | √ | MiniMax商用向量模型 | |
| 智譜AI-ChatGLM | Chat | ChatGLM-Pro、Std、Lite, characterglm | √ | 智譜AI多版商用大模型 |
| Embeddings | Text-Embedding | √ | 智譜AI商用文字向量模型 | |
| 訊飛-星火 | Chat | SparkDesk V1.5, V2.0 | √ | 訊飛星火認知大模型 |
| Embeddings | embedding | √ | 訊飛星火文本向量模型 | |
| 商湯-日日新 | Chat | nova-ptc-xl-v1, nova-ptc-xs-v1 | √ | SenseNova 商湯日日新大模型 |
| 百川智能 | Chat | baichuan-53b-v1.0.0 | √ | 百川53B大模型 |
| 騰訊-混元 | Chat | Tencent Hunyuan | √ | 騰訊混元大模型 |
| 自行部署的開源模型 | Chat, Completion, Embeddings | 各類開源模型 | √ | 使用FastChat等部署的開源模型,提供的Web API介面遵循OpenAI-Compatible RESTful APIs,可以直接支持,詳見下文的模型存取章節 |
注意:
AIGC裡面的模型LLM和提示詞Prompt兩項技術都非常新,發展日新月異,理論、教程、工具、工程化等各個方面都非常欠缺,使用的技術棧與當前主流開發人員的經驗幾乎沒有重疊:
| 分類 | 當前主流開發 | Prompt工程 | 開發模型、微調模型 |
|---|---|---|---|
| 開發語言 | Java、.Net、Javscript、ABAP等 | 自然語言,Python | Python |
| 開發工具 | 非常多和成熟 | 無 | 成熟 |
| 開發門檻 | 較低且成熟 | 低但非常不成熟 | 非常高 |
| 開發技術 | 清晰且穩態 | 入門簡單但非常難於穩態輸出 | 複雜多變 |
| 常用技術 | 物件導向、資料庫、大數據 | prompt tunning、incontext learning、embedding | Transformer、RLHF、Finetunning、LoRA |
| 開源支援 | 豐富且成熟 | 非常混亂處於較低水平 | 豐富但不成熟 |
| 開發成本 | 低 | 較高 | 非常高 |
| 開發者 | 豐富 | 極度稀缺 | 非常稀缺 |
| 發展協同模式 | 根據產品經理交付的文件進行開發 | 一人或極簡的小組,從需求到交付營運全部工作 | 根據理論研究方向開發 |
目前,所有的科技公司、網路公司、大數據公司幾乎都在all in這個方向,但更多的傳統企業仍處於迷惘的狀態。傳統企業並非不需要,而是: 1) 沒有技術人才儲備,不知道做什麼;2) 沒有硬體儲備,沒有能力做;3) 業務數位化程度底,用AIGC改造升級週期長、見效慢。
目前國內外各種商用、開源模型太多,發展又特別快,不過模型的API、資料物件並不一樣,導致我們面對一個新模型(甚至一個新版本),都要去閱讀開發文檔,並修改自己的應用程式碼去適配,相信每個應用程式開發人員都測試過很多個模型,應該都深受其苦。
實際上,模型能力雖有不同,但提供能力的模式大致是一致的,因此有一個可以適配大量模型API,提供統一呼叫模式的框架,就變成了許多開發人員的迫切需求。
首先,bida並非要取代langchain,而是針對的目標定位不同、開發理念也有很大差異:
| 分類 | langchain | bida |
|---|---|---|
| 目標人群 | AIGC方向的全量開發人群 | 對把AIGC與應用開發結合有迫切需求的開發人員 |
| 模型支持 | 支援本地部署或遠端部署的各種模型 | 僅支援提供Web API的模型調用,目前商用模型大部分都提供,開源模型使用FastChat等框架部署後也可以提供Web API |
| 框架結構 | 因為提供的能力多,結構非常複雜,截止2023年8月,核心代碼已有1700多個文件,15萬行代碼,學習門檻較高 | 核心程式碼十餘個,2000行左右程式碼,學習修改程式碼較簡單 |
| 功能支援 | 提供AIGC方向各類模型、技術、應用領域的全覆蓋 | 目前提供ChatCompletions、Completions、Embeddings、Function Call等功能支持,語音、影像等多模態功能近期陸續發布 |
| Prompt | 提供Prompt模板,但自有功能使用的Prompt內嵌在程式碼內,調試和修改都很困難 | 提供Prompt模板,目前無內建功能使用Prompt,未來若使用,也會採用配置型後載入模式,方便使用者自行調整 |
| Conversation & Memory | 支持,並提供多種Memory管理方式 | 支持,支援Conversation持久化(儲存至duckdb),Memory提供限定歸檔會話能力,其他能力有擴充框架可自行擴充 |
| Function & Plugin | 支持,並提供豐富的擴展能力,但使用效果依賴大模型的自身能力 | 相容於使用OpenAI的Function Call規範的大模型 |
| Agent & Chain | 支持,並提供豐富的擴展能力,但使用效果依賴大模型的自身能力 | 不支持,計劃另開專案實現,也可基於當前框架自行擴展開發 |
| 其他功能 | 支援很多其他功能,例如文檔拆塊(拆塊後做embedding,用於實現chatpdf等類似的功能) | 暫無其他功能,如果增加也會採用另開相容項目的方式來實現,目前可以使用其他產品提供的能力組合後實現 |
| 運作效率 | 很多開發者反映比直接呼叫API慢,原因未知 | 僅封裝了呼叫流程和統一了呼叫接口,性能與直接呼叫API沒有區別 |
langchain做為業界領導的開源項目,為大模型以及AGI的推廣做出了巨大貢獻,我們也在專案中應用了它,同時在開發bida時,也藉鑒了很多它的模式和思想。但langchain太想做一個大而全的工具,不可避免的也產生了很多缺點,下面幾篇文章,意見都差不多:Max Woolf - 中文, Hacker News - 中文。
圈內流行一句話非常好的做了總結: langchain,一個人人都會學習,但最後都會丟棄的教科書。
從pip或pip3安裝最新的bida
pip install -U bida從github clone專案代碼到本地目錄:
git clone https://github.com/pfzhou/bida.git
pip install -r requirements.txt修改目前程式碼根目錄下面的檔案: ".env.template"的副檔名,成為".env"環境變數檔。請根據文件中的說明,把已經申請模型的key配置進去。
請注意:該檔案已經加入忽略清單,不會傳到git伺服器。
examples1.初始化環境.ipynb
以下示範程式碼會混合使用各種bida支援的模型,請根據自己購買的模型修改替換程式碼中的**[model_type]**值為對應的模型公司名字,就可以快速切換各種模型進行體驗:
# 更多信息参看bidamodels*.json中的model_type配置
# openai
llm = ChatLLM ( model_type = "openai" )
# baidu
llm = ChatLLM ( model_type = "baidu" )
# baidu third models(llama-2...)
llm = ChatLLM ( model_type = "baidu-third" )
# aliyun
llm = ChatLLM ( model_type = "aliyun" )
# minimax
llm = ChatLLM ( model_type = "minimax" )
# minimax ccp
llm = ChatLLM ( model_type = "minimax-ccp" )
# zhipu ai
llm = ChatLLM ( model_type = "chatglm2" )
# xunfei xinghuo
llm = ChatLLM ( model_type = "xfyun" )
# senstime
llm = ChatLLM ( model_type = "senstime" )
# baichuan ai
llm = ChatLLM ( model_type = "baichuan" )
# tencent ai
llm = ChatLLM ( model_type = "tencent" )Chat模式:ChatCompletion,目前主流的LLM互動模式,bida支援會話管理,支援持久化保存和Memory管理。
from bida import ChatLLM
llm = ChatLLM ( model_type = 'baidu' )
result = llm . chat ( "你好呀,请问你是谁?" )
print ( result ) from bida import ChatLLM
# stream调用
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你好呀,请问你是谁?" ) from bida import ChatLLM
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
result = llm . chat ( "我的名字是?" )以上的詳細程式碼和更多功能範例,請參考下面的NoteBook:
examples2.1.Chat模式.ipynb
使用gradio建立chatbot
gradio是一款非常受歡迎的自然語言處理介面框架
bida + gradio 可以用幾行程式碼就搭建一個可用的應用程式
import gradio as gr
from bida import ChatLLM
llm = ChatLLM ( model_type = 'openai' )
def predict ( message , history ):
answer = llm . chat ( message )
return answer
gr . ChatInterface ( predict ). launch ()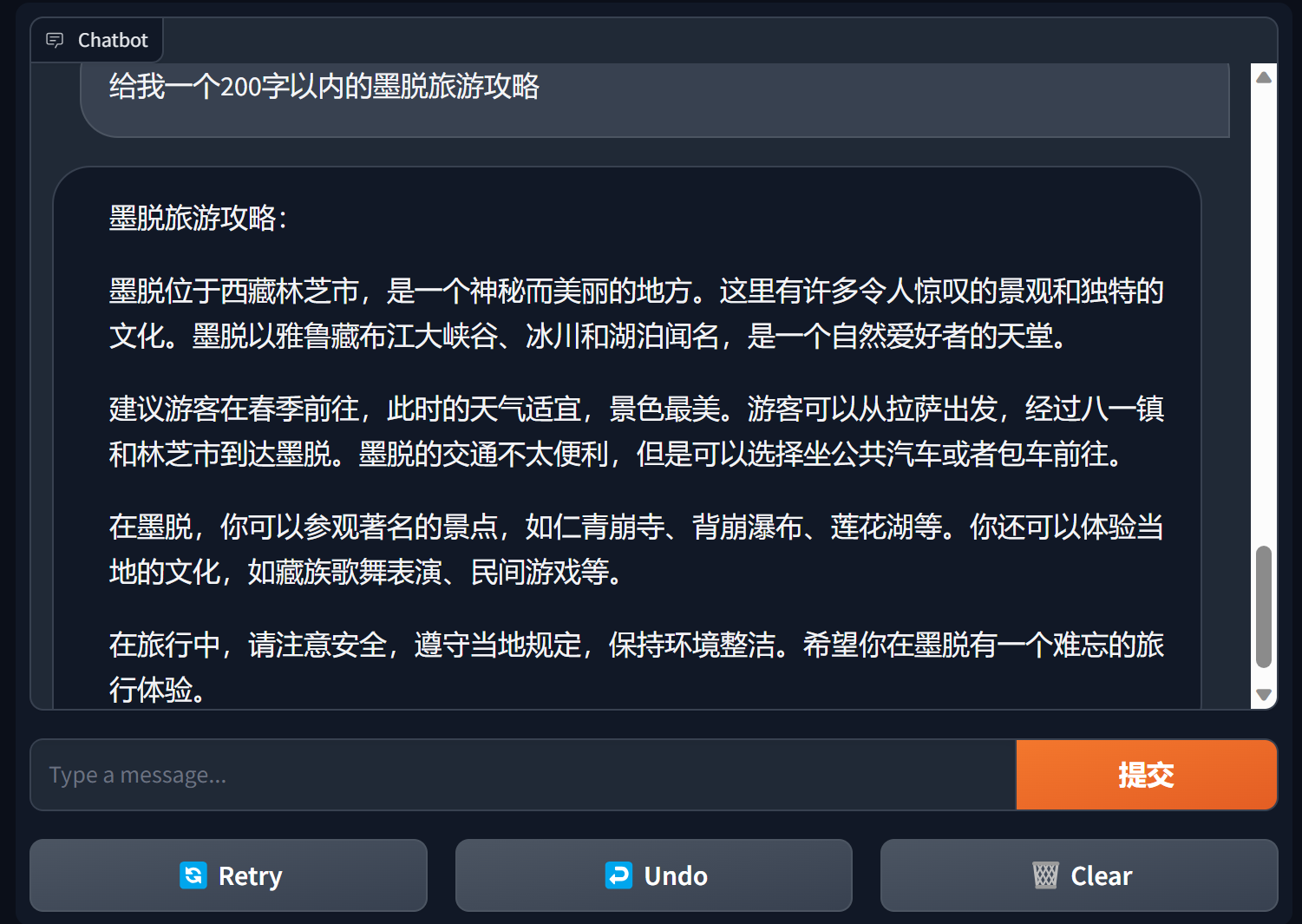
詳細內容請見:bida+gradio的chatbot demo
Completion模式:Completions或TextCompletions,上一代LLM互動模式,僅支援單輪會話,不儲存聊天記錄,每次呼叫都是全新的交流。
請注意:此模式在OpenAI 2023年7月6日的文章中,明確表示要逐步淘汰,新出的模型也基本上不提供相關功能,即使支持的模型估計也會採取跟隨OpenAI,預計未來都會逐漸淘汰。
from bida import TextLLM
llm = TextLLM ( model_type = "openai" )
result = llm . completion ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
print ( result )範例程式碼詳見:
examples2.2.Completion模式.ipynb
提示詞Prompt是大語言模型中最重要的功能,顛覆了傳統物件導向的開發模式,轉變為: Prompt工程。 本框架使用「提示詞模板Prompt Templete」來實現,支援替換標記、多模型設定不同的提示詞和模型執行互動時自動替換等功能。
目前已提供PromptTemplate_Text :支援使用字串文字產生Prompt模板,bida也支援靈活的自訂模板,未來計劃提供從json和資料庫中載入模板的能力。
詳細範例程式碼請參看下面的文件:
examples2.3.Prompt提示詞.ipynb
提示詞中重要說明
總的來說,建議提示詞遵循:設定角色,明確任務,給出上下文(相關資料或範例)的三段式結構,可以參考範例中的寫法。
吳恩達的系列課程https://learn.deeplearning.ai/login , 中文版, 解讀
openai cookbook https://github.com/openai/openai-cookbook
微軟Azure文件:提示工程簡介, 提示工程技術
Github上最火紅的Prompt Engineering Guide , 中文版
函數呼叫Function Calling是OpenAI2023年6月13日發布的功能,我們都知道ChatGPT訓練的資料是基於2021年之前的,你要問一些即時性相關的問題就沒辦法回答你了,而函數呼叫讓即時取得網路資料成為可能,例如查詢天氣預報、查股票、推薦近期的電影之類的。
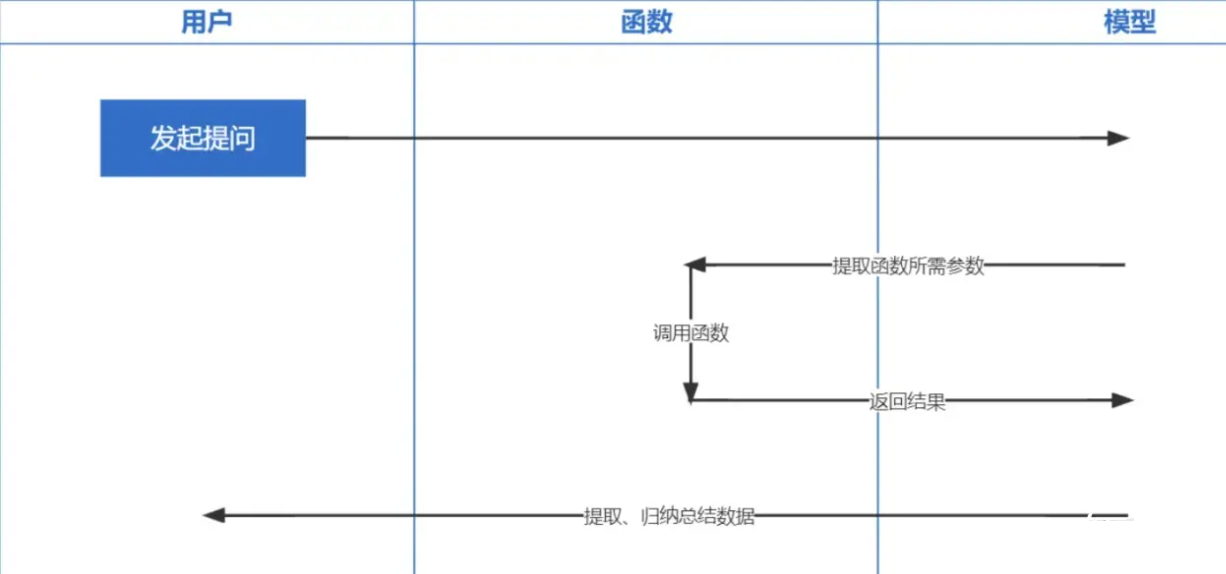
Embeddings技術是實現Prompt inContext Learning最重要的技術,比較先前關鍵字檢索,又提升了一步。
注意:不同模型embedding出來的資料是不通用的,因此檢索時問題的embedding也要用同一個模型才可以。
| 模型名稱 | 輸出維度 | 批次記錄數 | 單一文字token限制 |
|---|---|---|---|
| OpenAI | 1536 | 不限 | 8191 |
| 百度 | 384 | 16 | 384 |
| 阿里 | 1536 | 10 | 2048 |
| MiniMax | 1536 | 不限 | 4096 |
| 智譜AI | 1024 | 單條 | 512 |
| 訊飛星火 | 1024 | 單條 | 256 |
注意: bida的embedding介面支援批次處理,超過模型批次限制會自動分批循環處理後一起回傳。單一文字內容超過限制token數,根據模型的邏輯,有的會報錯,有的會截斷處理。
詳細範例參考:examples2.6.Embeddings嵌入模型.ipynb
├─bida # bida框架主目录
│ ├─core # bida框架核心代码
│ ├─functions # 自定义function文件
│ ├─ *.json # function定义
│ ├─ *.py # 对应的调用代码
│ ├─models # 接入模型文件
│ ├─ *.json # 模型配置定义:openai.json、baidu.json等
│ ├─ *_api.py # 模型接入代码:openai_api.py、baidu_api.py等
│ ├─ *_sdk.py # 模型sdk代码:baidu_sdk.py等
│ ├─prompts # 自定义prompt模板文件
│ ├─*.py # 框架其他代码文件
├─docs # 帮助文档
├─examples # 演示代码、notebook文件和相关数据文件
├─test # pytest测试代码
│ .env.template # .env的模板
│ LICENSE # MIT 授权文件
│ pytest.ini # pytest配置文件
│ README.md # 本说明文件
│ requirements.txt # 相关依赖包
我們希望可以適應更多的模型,也歡迎您提出寶貴意見,一起提供開發者更好的產品!


