RWKV LM
v5
RWKV首頁:https://www.rwkv.com
RWKV-5/6 Eagle/Finch 論文:https://arxiv.org/abs/2404.05892
Vision 中很棒的 RWKV: https://github.com/Yaziwel/Awesome-RWKV-in-Vision
RWKV-6 3B 示範:https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-1
RWKV-6 7B 示範:https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
RWKV-6 GPT 模式示範程式碼(附註解與解釋) :https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/rwkv_v6_demo.py
RWKV-6 RNN 模式示範:https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
作為參考,使用 python 3.10+、torch 2.5+、cuda 12.5+、最新的 deepspeed,但保持 pytorch-lightning==1.9.5
訓練 RWKV-6 :使用 /RWKV-v5/ 並在 demo-training-prepare.sh 和 demo-training-run.sh 中使用 --my_testing "x060"
訓練 RWKV-7 :使用 /RWKV-v5/ 並在 demo-training-prepare.sh 和 demo-training-run.sh 中使用 --my_testing "x070"
pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu121
pip install pytorch-lightning==1.9.5 deepspeed wandb ninja --upgrade
cd RWKV-v5/
./demo-training-prepare.sh
./demo-training-run.sh
(you may want to log in to wandb first)
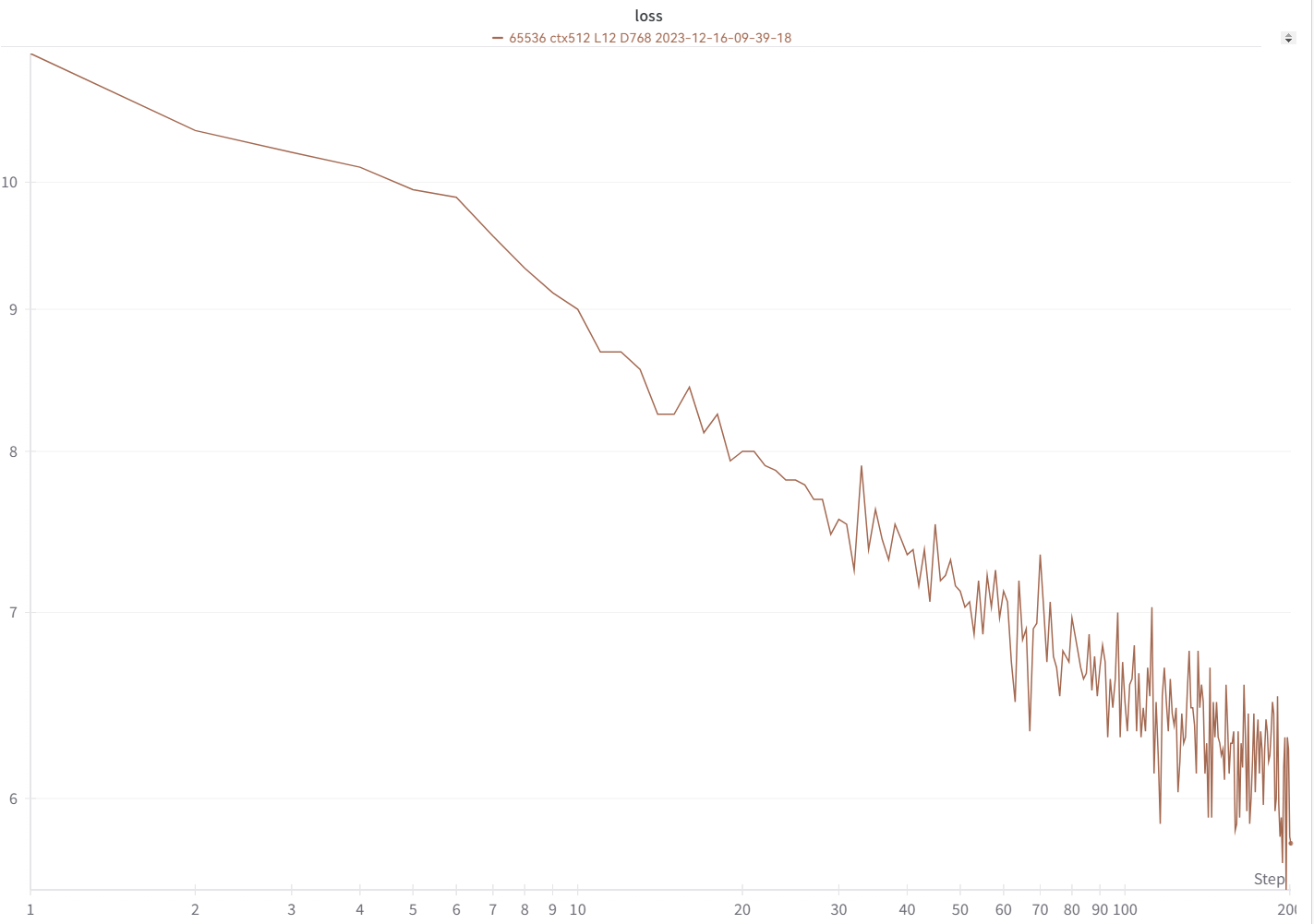
您的損失曲線應該看起來幾乎與此完全相同,具有相同的起伏(如果您使用相同的 bsz 和配置):
您可以使用 https://pypi.org/project/rwkv/ 運行模型(使用“rwkv_vocab_v20230424”而不是“20B_tokenizer.json”)
使用 https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py 從 jsonl 準備 binidx 數據,並計算「--my_exit_tokens」和「--magic_prime」。
大數據更快的分詞器:https://github.com/cahya-wirawan/json2bin
train.py中的「epoch」是「mini-epoch」(不是真正的epoch。只是為了方便起見),1個mini-epoch = 40320 * ctx_len tokens。
例如,如果您的 binidx 有 1498226207 個令牌且 ctxlen=4096,請設定「--my_exit_tokens 1498226207」(這將覆蓋 epoch_count),它將是 1498226207/(40320 *207020207/(40320 207020207/(40320訓練器將在「--my_exit_tokens」令牌後自動退出。將「--magic_prime」設定為小於 datalen/ctxlen-1 (= 1498226207/4096-1 = 365776) 的最大 3n+2 個質數,在本例中為「--magic_prime 365759」。
簡單:準備 SFT jsonl => 在 make_data.py 中重複 SFT 資料 3 或 4 次。更多的重複會導致過度擬合。
進階:在 jsonl 中重複 SFT 資料 3 或 4 次(注意 make_data.py 將打亂所有 jsonl 項)=> 將一些基礎資料(例如 slimpajama)加入 jsonl => 並且僅在 make_data.py 中重複 1 次。
修復訓練尖峰:請參閱本頁的「修復 RWKV-6 尖峰」部分。
RWKV-5 的簡單推理:https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
RWKV-6 的簡單推理:https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
注意:在 [state = kv + w * state] 中,所有內容都必須是 fp32,因為 w 可以非常接近 1。
lm_eval:https://github.com/BlinkDL/ChatRWKV/blob/main/run_lm_eval.py
開發人員的聊天示範:https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_CHAT.py
小模型/小資料的提示:當我訓練 RWKV 音樂模型時,我使用深和窄(例如 L29-D512)維度,並應用 wd 和 dropout(例如 wd=2 dropout=0.02)。注意 RWKV-LM 壓力差非常有效 - 使用通常值的 1/4。
資料使用 .jsonl 格式(有關格式,請參閱 https://huggingface.co/BlinkDL/rwkv-5-world)。
使用 https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py 使用 World tokenizer 將其標記為 binidx,適合微調 World 模型。
將模型資料夾中的基本檢查點重新命名為rwkv-init.pth,並將訓練指令改為對7B 使用--n_layer 32 --n_embd 4096 --vocab_size 65536 --lr_init 1e-5 --lr_final 1e- 5。
0.1B = --n_layer 12 --n_embd 768 // 0.4B = --n_layer 24 --n_embd 1024 // 1.5B = --n_layer 24 --n_embd 2048 // 3B = --n_layer 32 --n_ / 7B = --n_layer 32 --n_embd 4096
目前未最佳化的實現,採用與完整 SFT 相同的 vram
--train_type "states" --load_partial 1 --lr_init 1 --lr_final 0.01 --warmup_steps 10 (yes, use very high LR)
使用 rwkv 0.8.26+ 自動載入經過訓練的“time_state”
當您從頭開始訓練 RWKV 時,請嘗試我的初始化以獲得最佳性能。檢查 src/model.py 的generate_init_weight():
emb.weight => nn.init.uniform_(a=-1e-4, b=1e-4)
(Note ln0 of block0 is the layernorm for emb.weight)
head.weight => nn.init.orthogonal_(gain=0.5*sqrt(n_vocab / n_embd))
att.receptance.weight => nn.init.orthogonal_(gain=1)
att.key.weight => nn.init.orthogonal_(gain=0.1)
att.value.weight => nn.init.orthogonal_(gain=1)
att.gate.weight => nn.init.orthogonal_(gain=0.1)
att.output.weight => zero
att.ln_x.weight (groupnorm) => ((1 + layer_id) / total_layers) ** 0.7
ffn.key.weight => nn.init.orthogonal_(gain=1)
ffn.value.weight => zero
ffn.receptance.weight => zero
!如果您使用位置嵌入,也許最好刪除 block.0.ln0 並使用 emb.weight 的預設初始化而不是我的uniform_(a=-1e-4, b=1e-4)!
從頭開始訓練時,請在“RUN_CUDA_RWKV6(r, k, v, w, u)”之前加上“k = k * torch.clamp(w, max=0).exp()”,並記住也要更改您的推理代碼。你會看到更快的收斂。
使用“--adam_eps 1e-18”
如果您看到峰值,則“--beta2 0.95”
在trainer.py中執行“lr = lr *(0.01 + 0.99 * trainer.global_step / w_step)”(最初為0.2 + 0.8)和“--warmup_steps 20”
如果您正在訓練大量數據,「--weight_decay 0.1」會帶來更好的最終損失。執行此操作時,將 lr_final 設為 lr_init 的 1/100。
RWKV 是具有 Transformer 等級 LLM 表現的 RNN,也可以像 GPT Transformer 一樣直接訓練(可並行)。而且它是 100% 無需關注的。您只需要位置 t 處的隱藏狀態即可計算位置 t+1 處的狀態。您可以使用“GPT”模式快速計算“RNN”模式的隱藏狀態。
因此,它結合了 RNN 和 Transformer 的優點 -出色的性能、快速推理、節省 VRAM、快速訓練、「無限」ctx_len 和自由句子嵌入(使用最終隱藏狀態)。
RWKV Runner GUI https://github.com/josStorer/RWKV-Runner 具有一鍵安裝和 API
所有最新的 RWKV 權重: https://huggingface.co/BlinkDL
相容 HF 的 RWKV 配重: https://huggingface.co/RWKV
RWKV pip 套件:https://pypi.org/project/rwkv/
os . environ [ "RWKV_JIT_ON" ] = '1'
os . environ [ "RWKV_CUDA_ON" ] = '0' # if '1' then use CUDA kernel for seq mode (much faster)
from rwkv . model import RWKV # pip install rwkv
model = RWKV ( model = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-1b5/RWKV-4-Pile-1B5-20220903-8040' , strategy = 'cuda fp16' )
out , state = model . forward ([ 187 , 510 , 1563 , 310 , 247 ], None ) # use 20B_tokenizer.json
print ( out . detach (). cpu (). numpy ()) # get logits
out , state = model . forward ([ 187 , 510 ], None )
out , state = model . forward ([ 1563 ], state ) # RNN has state (use deepcopy if you want to clone it)
out , state = model . forward ([ 310 , 247 ], state )
print ( out . detach (). cpu (). numpy ()) # same result as abovenanoRWKV :https://github.com/BlinkDL/nanoRWKV(不需要自訂 CUDA 核心進行訓練,適用於任何 GPU/CPU)
推特:https://twitter.com/BlinkDL_AI
首頁:https://www.rwkv.com
酷社區 RWKV 計畫:
所有(300+)RWKV 項目:https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories
https://github.com/OpenGVLab/Vision-RWKV 願景 RWKV
https://github.com/feizc/Diffusion-RWKV 擴散 RWKV
https://github.com/cgisky1980/ai00_rwkv_server 最快的 WebGPU 推理 (nVidia/AMD/Intel)
https://github.com/cryscan/web-rwkv ai00_rwkv_server 後端
https://github.com/saharNooby/rwkv.cpp 快速 CPU/cuBLAS/CLBlast 推理:int4/int8/fp16/fp32
https://github.com/JL-er/RWKV-PEFT lora/pissa/Qlora/Qpissa/state 調整
https://github.com/RWKV/RWKV-infctx-trainer Infctx 訓練器
https://github.com/daquexian/faster-rwkv
MLC-ai/MLC-llm#1275
https://github.com/TheRamU/Fay/blob/main/README_EN.md 附 RWKV 的數位助理
https://github.com/harrisonvanderbyl/rwkv-cpp-cuda 使用 cuda/amd/vulkan 進行快速 GPU 推理
RWKV v6 250 行(也附有分詞器):https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
RWKV v5 250 行(也附有分詞器):https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
RWKV v4 150 行(模型、推理、文字產生):https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py
RWKV v4 預印本https://arxiv.org/abs/2305.13048
RWKV v4介紹,以及100行numpy :https://johanwind.github.io/2023/03/23/rwkv_overview.html https://johanwind.github.io/2023/03/23/rwkv_details.html
RWKV v6 圖解:
使用 RWKV 的一篇很酷的論文(Spiking Neural Network):https://github.com/ridgerchu/SpikeGPT
歡迎您加入 RWKV 不和諧 https://discord.gg/bDSBUMeFpc 並以此為基礎。我們現在擁有大量潛在的計算(A100 40G)(感謝 Stability 和 EleutherAI),所以如果您有有趣的想法,我可以運行它們。

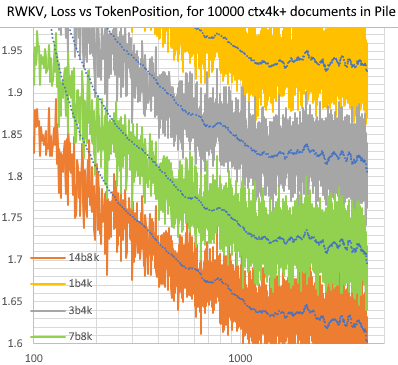
Pile 中 10000 個 ctx4k+ 文件的 RWKV [損失與代幣位置]。 RWKV 1B5-4k在ctx1500之後大部分是平坦的,但是3B-4k和7B-4k和14B-4k有一些斜坡,並且正在變得更好。這推翻了 RNN 無法對長 ctxlens 進行建模的舊觀點。我們可以預測 RWKV 100B 會很棒,而 RWKV 1T 可能就是您所需要的:)
與 RWKV 14B ctx8192 聊天RWKV:

我相信 RNN 是基本模型的更好候選者,因為:(1)它對 ASIC 更友善(沒有 kv 快取)。 (2)對於RL更加友善。 (3)當我們寫作時,我們的大腦更類似RNN。 (4) 宇宙也像一個 RNN(因為局部性)。變壓器是非本地模型。
A40 (tf32) 上的 RWKV-3 1.5B = 始終為 0.015 秒/令牌,使用簡單的 pytorch 程式碼(無 CUDA)進行測試,GPU 利用率 45%,VRAM 7823M
A40 上的 GPT2-XL 1.3B (tf32) = 0.032 秒/令牌(對於 ctxlen 1000),使用 HF 進行測試,GPU 使用率也是 45%(有趣),VRAM 9655M
訓練速度:(新訓練代碼)RWKV-4 14B BF16 ctxlen4096 = 8x8 A100 80G (ZERO2+CP) 上 114K 令牌/秒。 (舊訓練代碼)RWKV-4 1.5B BF16 ctxlen1024 = 8xA100 40G 上的 106K 令牌/秒。
我也在做圖像實驗(例如:https://huggingface.co/BlinkDL/clip-guided-binary-autoencoder)並且RWKV將能夠進行txt2img擴散:)我的想法:256x256 rgb圖像 - > 32x32x13位元潛在 - >應用RWKV 計算每個32x32 網格的轉移機率-> 假設網格是獨立的,並使用這些機率「擴散」。
平穩訓練 - 無損失高峰! (lr & bsz 變化約 15G 代幣) 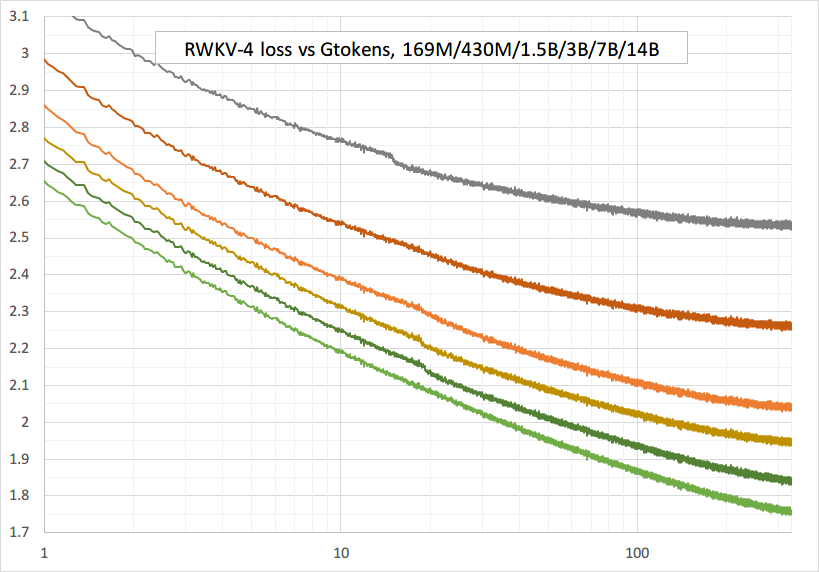
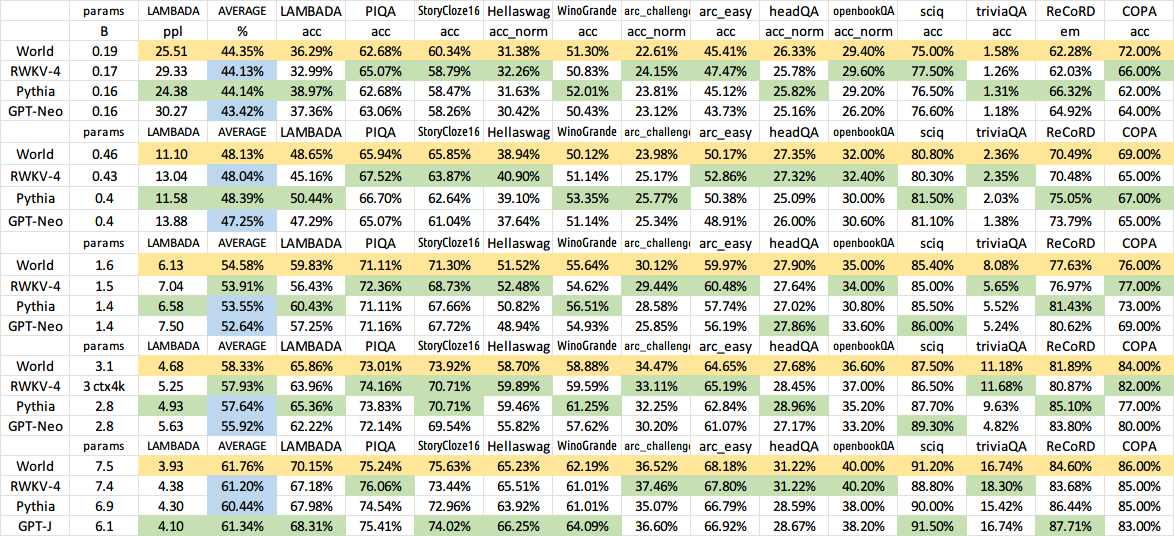
所有經過訓練的模型都將開源。即使在 CPU 上,推理速度也非常快(僅矩陣向量乘法,沒有矩陣矩陣乘法),因此您甚至可以在手機上運行 LLM。
如何運作:RWKV 將資訊收集到多個通道,當您移動到下一個標記時,這些通道也會以不同的速度衰減。一旦你理解了它就非常簡單了。
RWKV 是可並行化的,因為每個通道的時間衰減是資料無關的(且可訓練) 。例如,在通常的 RNN 中,您可以將通道的時間衰減從 0.8 調整到 0.5(這些稱為“門”),而在 RWKV 中,您只需將資訊從 W-0.8 通道移至 W-0.5 - channel 達到同樣的效果。此外,如果您想要額外的效能,您可以將 RWKV 微調為不可並行的 RNN(然後您可以使用前一個標記的後面層的輸出)。

這是我的一些待辦事項。讓我們一起努力:)
HuggingFace 整合(檢查 Huggingface/transformers#17230 ),以及優化的 CPU & iOS & Android & WASM & WebGL 推理。 RWKV 是一種 RNN,對於邊緣設備非常友善。讓我們可以在您的手機上運行法學碩士。
在雙向和傳銷任務以及圖像、音訊和視訊令牌上對其進行測試。我認為 RWKV 可以透過以下方式支援編碼器-解碼器:對於每個解碼器令牌,使用[解碼器先前隱藏狀態]和[編碼器最終隱藏狀態]的學習混合。因此,所有解碼器令牌都可以存取編碼器輸出。
現在用一個微小的額外注意力(與 RWKV-4 相比僅增加幾行)來訓練 RWKV-4a,以進一步改進較小模型的一些困難的零樣本任務(例如 LAMBADA)。請參閱https://github.com/BlinkDL/RWKV-LM/commit/a268cd2e40351ee31c30c5f8a5d1266d35b41829
用戶回饋:
到目前為止,我已經在相對較小的預訓練資料集(大約 10GB 文字)上嘗試過基於字元的模型,結果非常好 - 與需要更長的訓練時間的模型類似。
親愛的上帝,rwkv 速度很快。在從頭開始訓練它後,我切換到另一個選項卡,當我返回時,它發出看似合理的英語和毛利語單詞,我離開去微波爐加熱一些咖啡,當我回來時,它正在生成完全語法正確的句子。
Sepp Hochreiter 的推文(謝謝!):https://twitter.com/HochreiterSepp/status/1524270961314484227
您也可以在 EleutherAI Discord 中找到我(BlinkDL):https://www.eleuther.ai/get-involved/
重要提示:使用 deepspeed==0.7.0 pytorch-lightning==1.9.5 torch==1.13.1+cu117 和 cuda 11.7.1 或 11.7 (注意 torch2 + deepspeed 有奇怪的錯誤並損害模型效能)
使用https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v4neo(最新程式碼,相容v4)。
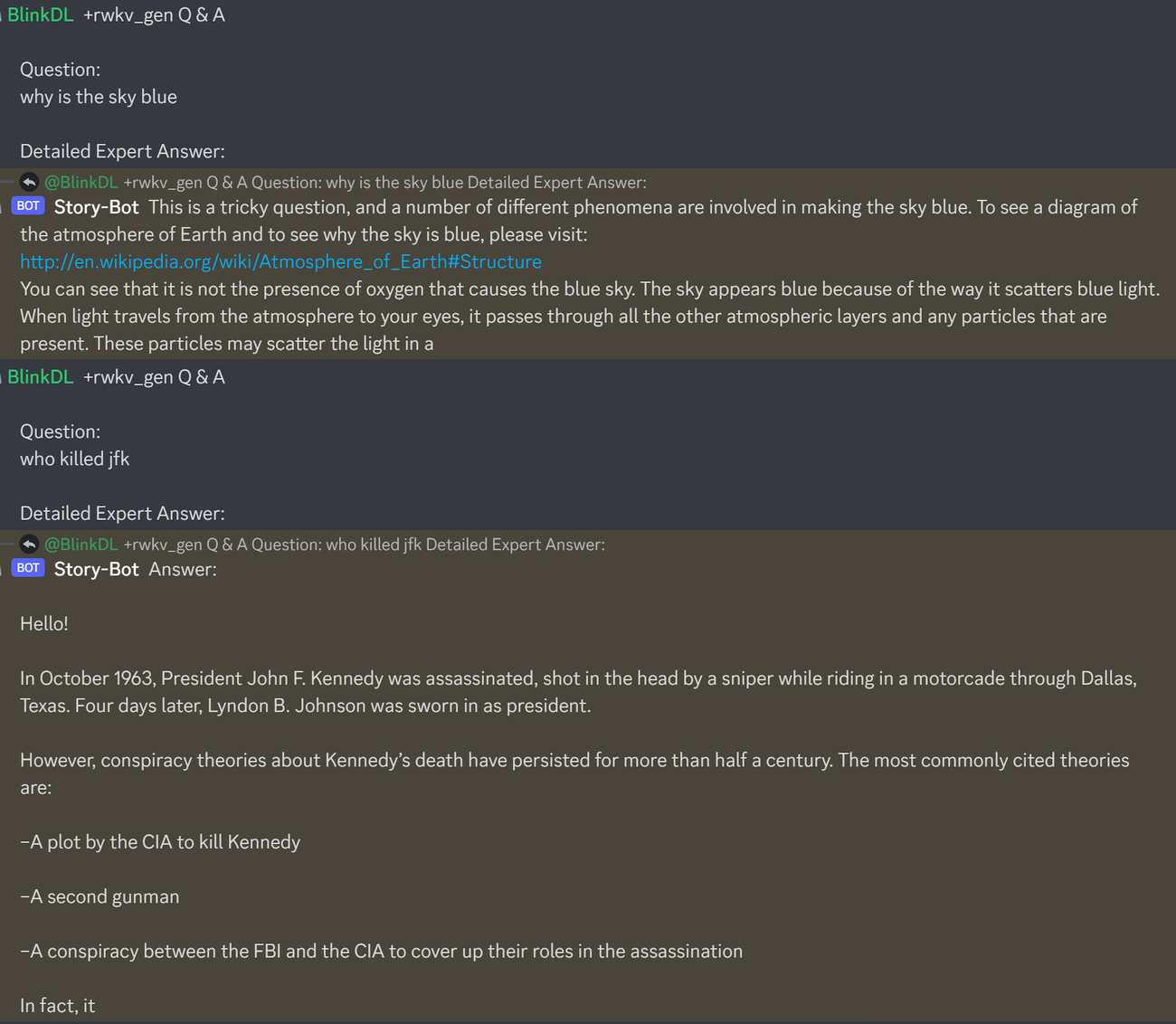
這是測試法學碩士問答的一個很好的提示。適用於任何模型:(透過最小化 RWKV 1.5B 的 ChatGPT ppls 發現)
prompt = f' n Q & A n n Question: n { qq } n n Detailed Expert Answer: n ' # let the model generate after this執行 RWKV-4 樁模型:從 https://huggingface.co/BlinkDL 下載模型。在 run.py 中設定 TOKEN_MODE = 'pile' 並運行它。即使在 CPU 上(預設模式),它也很快。
RWKV-4 樁 1.5B 的 Colab :https://colab.research.google.com/drive/1F7tZoPZaWJf1fsCmZ5tjw6sYHiFOYVWM
在瀏覽器(和 onnx 版本)中執行 RWKV-4 樁模型:請參閱此問題 #7
RWKV-4 Web 演示:https://josephrocca.github.io/rwkv-v4-web/demo/(注意:目前僅貪婪採樣)
對於舊的 RWKV-2:請參閱此處的版本,以了解 enwik8 上 0.72 BPC(dev) 的 27M 參數模型。在 https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v2-RNN 中執行 run.py。您甚至可以在瀏覽器中運行它: https://github.com/BlinkDL/AI-Writer/tree/main/docs/eng https://blinkdl.github.io/AI-Writer/eng/ (這是使用tf.js WASM 單執行緒模式)。
pip install deepspeed==0.7.0 // pip install pytorch-lightning==1.9.5 // 火炬 1.13.1+cu117
注意:在少量資料上進行訓練時,添加權重衰減(0.1 或 0.01)和 dropout(0.1 或 0.01)。嘗試 x=x+dropout(att(x)) x=x+dropout(ffn(x)) x=dropout(x+att(x)) x=dropout(x+ffn(x)) 等。
從頭開始訓練 RWKV-4:執行 train.py,預設使用 enwik8 資料集(解壓縮 https://data.deepai.org/enwik8.zip)。
您將訓練“GPT”版本,因為它是可並行的並且訓練速度更快。 RWKV-4 可以進行推斷,因此使用 ctxLen 1024 進行訓練可以適用於 2500+ 的 ctxLen。您可以使用更長的 ctxLen 對模型進行微調,它可以快速適應更長的 ctxLens。
微調 RWKV-4 樁模型:使用 https://github.com/BlinkDL/RWKV-v2-RNN-Pile/tree/main/RWKV-v3 中的「prepare-data.py」將 .txt 標記為訓練。 npy 資料。然後使用 https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v4neo/train.py 來訓練它。
閱讀 src/model.py 中的推理程式碼,並嘗試使用最終的隱藏狀態(.xx .aa .bb)作為其他任務的忠實句子嵌入。也許您應該以 .xx 和 .aa/.bb 開頭(.aa 除以 .bb)。
用於微調 RWKV-4 樁模型的 Colab:https://colab.research.google.com/github/resloved/RWKV-notebooks/blob/master/RWKV_v4_RNN_Pile_Fine_Tuning.ipynb
大語料庫:使用https://github.com/Abel2076/json2binidx_tool將.jsonl轉換為.bin和.idx
jsonl 格式範例(每個文件一行):
{"text": "This is the first document."}
{"text": "HellonWorld"}
{"text": "1+1=2n1+2=3n2+2=4"}
由這樣的程式碼產生:
ss = json.dumps({"text": text}, ensure_ascii=False)
out.write(ss + "n")
無限 ctxlen 訓練(WIP): https://github.com/Blealtan/RWKV-LM-LoRA/tree/dev-infctx
考慮 RWKV 14B。狀態有200個向量,即每個區塊有5個向量:fp16(xx)、fp32(aa)、fp32(bb)、fp32(pp)、fp16(xx)。
不要avg pool,因為狀態中不同的向量(xx aa bb pp xx)有非常不同的意義和範圍。您也許可以刪除 pp。
我建議首先收集每個向量的每個通道的平均值+標準差統計量,並對它們進行歸一化(注意:歸一化應該與數據無關並從各種文本中收集)。然後訓練線性分類器。
RWKV-5 是多頭的,這裡顯示的是一個頭。每個頭還有一個 LayerNorm(因此實際上是 GroupNorm)。
動態混合和動態衰減。範例(對 TimeMix 和 ChannelMix 執行此操作):
TIME_MIX_EXTRA_DIM = 32
self.time_mix_k_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_k_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_v_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_v_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_r_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_r_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_g_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_g_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
...
time_mix_k = self.time_mix_k.view(1,1,-1) + (x @ self.time_mix_k_w1) @ self.time_mix_k_w2
time_mix_v = self.time_mix_v.view(1,1,-1) + (x @ self.time_mix_v_w1) @ self.time_mix_v_w2
time_mix_r = self.time_mix_r.view(1,1,-1) + (x @ self.time_mix_r_w1) @ self.time_mix_r_w2
time_mix_g = self.time_mix_g.view(1,1,-1) + (x @ self.time_mix_g_w1) @ self.time_mix_g_w2
xx = self.time_shift(x)
xk = x * time_mix_k + xx * (1 - time_mix_k)
xv = x * time_mix_v + xx * (1 - time_mix_v)
xr = x * time_mix_r + xx * (1 - time_mix_r)
xg = x * time_mix_g + xx * (1 - time_mix_g)

使用並行化模式快速產生狀態,然後使用微調的完整RNN(令牌n的層可以使用令牌n-1的所有層的輸出)進行順序產生。
現在時間衰減就像 0.999^T (0.999 是可學習的)。將其更改為 (0.999^T + 0.1) 之類的內容,其中 0.1 也是可學習的。 0.1 部分將永遠保留。或者,A^T + B^T + C = 快衰減 + 慢衰減 + 常數。甚至可以使用不同的公式(例如,對於衰減分量,使用 K^2 而不是 e^K,或不進行歸一化)。
在某些通道中使用複值衰減(因此,旋轉而不是衰減)。
注入一些可訓練和可推斷的位置編碼?
除了 2d 旋轉之外,我們還可以嘗試其他李群,例如 3d 旋轉( SO(3) )。非阿貝爾 RWKV 哈哈。
RWKV 在模擬設備上可能非常有用(搜尋模擬矩陣向量乘法和光子矩陣向量乘法)。 RNN 模式對硬體非常友善(記憶體中處理)。也可以是 SNN (https://github.com/ridgerchu/SpikeGPT)。我想知道它是否可以針對量子計算進行最佳化。
可訓練的初始隱藏狀態 (xx aa bb pp xx)。
分層(甚至行/列、元素)LR,並測試 Lion 最佳化器。
self.pos_emb_x = nn.Parameter(torch.zeros((1,args.my_pos_emb,args.n_embd)))
self.pos_emb_y = nn.Parameter(torch.zeros((args.my_pos_emb,1,args.n_embd)))
...
x = x + pos_emb_x + pos_emb_y
也許我們可以透過簡單地重複上下文來提高記憶力(我想 2 次就足夠了)。範例:參考資料 -> 參考資料(再次) -> 問題 -> 答案
這個想法是確保 vocab 中的每個標記都理解其長度和原始 UTF-8 位元組。
設 a = max(len(token)) 表示 vocab 中的所有 token。定義 AA : float[a][d_emb]
對於 vocab 中的所有 token,令 b = max(len_in_utf8_bytes(token)) 。定義 BB : float[b][256][d_emb]
對於 vocab 中的每個標記 X,令 [x0, x1, ..., xn] 為其原始 UTF-8 位元組。我們將為其嵌入 EMB(X) 添加一些額外的值:
EMB(X) += AA[len(X)] + BB[0][x0] + BB[1][x1] + ... + BB[n][xn] (註:AA BB 是可學習權重)
我有一個改進標記化的想法。我們可以對一些通道進行硬編碼以使其有意義。例子:
頻道 0 =“空間”
頻道 1 =“首字母大寫”
頻道 2 =“所有字母大寫”
所以:
嵌入「abc」:[0, 0, 0, x0, x1, x2 , ..]
嵌入「abc」:[1, 0, 0, x0, x1, x2, ..]
「Abc」的嵌入:[1, 1, 0, x0, x1, x2, ..]
嵌入「ABC」:[0, 0, 1, x0, x1, x2, ...]
.....
所以他們將共享大部分嵌入。我們可以快速計算“abc”所有變體的輸出機率。
注意:上述方法假設 p(" xyz") / p("xyz") 對任何 "xyz" 都是相同的,這可能是錯誤的。
更好:將 emb_space emb_capitalize_first emb_capitalize_all 定義為 emb 的函數。
也許最好的方法是:讓 'abc' ' abc' 等共享最後 90% 的嵌入。
此時,我們所有的分詞器花費了太多的項目來表示“abc”“abc”“Abc”等的所有變體。變體實際上是相似的。這裡的方法可以改善這一點。我計劃在新版本的 RWKV 中對此進行測試。
例(單輪問答):
產生所有 wiki 文件的最終狀態。
對於任何使用者Q,找到最好的wiki文檔,並使用其最終狀態作為初始狀態。
訓練模型直接產生任意使用者 Q 的最優初始狀態。
然而,對於多輪問答來說,這可能有點棘手:)
RWKV 的靈感來自 Apple 的 AFT (https://arxiv.org/abs/2105.14103)。
此外,它還使用了我的一些技巧,例如:
SmallInitEmb:https://github.com/BlinkDL/SmallInitEmb(適用於所有變壓器),有助於提高嵌入質量,並穩定 Post-LN(這就是我正在使用的)。
Token-shift:https://github.com/BlinkDL/RWKV-LM#token-shift-time-shift-mixing(適用於所有變壓器),對於字元級模型特別有幫助。
Head-QK:https://github.com/BlinkDL/RWKV-LM#the-head-qk-trick-learning-to-copy-and-avoid-tokens(適用於所有 Transformer)。注意:這很有幫助,但我在 Pile 模型中禁用了它以保持 100% RNN。
FFN 中的額外 R 閘(適用於所有變壓器)。我還使用 Primer 中的 reluSquared。
更好的初始化:我將大部分矩陣初始化為零(請參閱 https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v2-RNN/src/model.py 中的 RWKV_Init)。
您可以將一些參數從小模型轉移到大模型(注意:我也對它們進行排序和平滑),以實現更快更好的收斂(請參閱https://www.reddit.com/r/MachineLearning/comments /umq908/r_rwkvv2rnn_a_parallelizes_rnn_with /)。
我的 CUDA 內核:https://github.com/BlinkDL/RWKV-CUDA 以加速訓練。

abcd 因子共同建構時間衰減曲線:[X, 1, W, W^2, W^3, ...]。
寫出「token at pos 2」和「token at pos 3」的公式,你就會明白:
kv/k是記憶機制。如果通道中的 W 接近 1,則具有高 k 的令牌可以被記住很長時間。
R 門對於性能很重要。 k = 該令牌的訊息強度(將傳遞給未來的令牌)。 r = 是否將資訊套用至此令牌。
對 SA 和 FF 層中的 R / K / V 使用不同的可訓練 TimeMix 因子。例子:
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )使用 preLN 代替 postLN (更穩定且收斂更快):
if self . layer_id == 0 :
x = self . ln0 ( x )
x = x + self . att ( self . ln1 ( x ))
x = x + self . ffn ( self . ln2 ( x ))RWKV-3 GPT 模式的構建塊與通常的 preLN GPT 類似。
唯一的區別是嵌入後有一個額外的邏輯節點。請注意,您可以在完成訓練後將此 LN 吸收到嵌入中。
x = self . emb ( idx ) # input: idx = token indices
x = self . ln_emb ( x ) # extra LN after embedding
x = x + self . att_0 ( self . ln_att_0 ( x )) # preLN
x = x + self . ffn_0 ( self . ln_ffn_0 ( x ))
...
x = x + self . att_n ( self . ln_att_n ( x ))
x = x + self . ffn_n ( self . ln_ffn_n ( x ))
x = self . ln_head ( x ) # final LN before projection
x = self . head ( x ) # output: x = logits將 emb 初始化為微小值非常重要,例如 nn.init.uniform_(a=-1e-4, b=1e-4),以利用我的技巧 https://github.com/BlinkDL/SmallInitEmb。
對於 1.5B RWKV-3,我在 8 * A100 40G 上使用 Adam(無 wd、無 dropout)優化器。
batchSz = 32 * 896,ctxLen = 896。
對於前15B代幣,LR固定為3e-4,beta=(0.9,0.99)。
然後我設定 beta=(0.9, 0.999),並對 LR 進行指數衰減,在 332B 令牌達到 1e-5。
RWKV-3 沒有通常意義上的任何關注,但無論如何我們都會將此區塊稱為 ATT。
B , T , C = x . size () # x = (Batch,Time,Channel)
# Mix x with the previous timestep to produce xk, xv, xr
xx = self . time_shift ( x ) # self.time_shift = nn.ZeroPad2d((0,0,1,-1))
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# Use xk, xv, xr to produce k, v, r
k = self . key ( xk ). transpose ( - 1 , - 2 )
v = self . value ( xv ). transpose ( - 1 , - 2 )
r = self . receptance ( xr )
k = torch . clamp ( k , max = 60 ) # clamp k to avoid overflow
k = torch . exp ( k )
kv = k * v
# Compute the W-curve = [e^(-n * e^time_decay), e^(-(n-1) * e^time_decay), ..., 1, e^(time_first)]
self . time_w = torch . cat ([ torch . exp ( self . time_decay ) * self . time_curve . to ( x . device ), self . time_first ], dim = - 1 )
w = torch . exp ( self . time_w )
# Use W to mix kv and k respectively. Add K_EPS to wk to avoid divide-by-zero
if RUN_DEVICE == 'cuda' :
wkv = TimeX . apply ( w , kv , B , C , T , 0 )
wk = TimeX . apply ( w , k , B , C , T , K_EPS )
else :
w = w [:, - T :]. unsqueeze ( 1 )
wkv = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( kv ), w , groups = C )
wk = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( k ), w , groups = C ) + K_EPS
# The RWKV formula
rwkv = torch . sigmoid ( r ) * ( wkv / wk ). transpose ( - 1 , - 2 )
rwkv = self . output ( rwkv ) # final output projectionself.key、self.receptance、self.output 矩陣皆初始化為零。
time_mix、time_decay、time_first 向量是從較小的訓練模型轉移而來的(注意:我也對它們進行排序和平滑)。
與通常的GPT相比,FFN區塊有三個技巧:
我的 time_mix 技巧。
來自 Primer 論文的 sqReLU。
一個額外的接收閘門(類似 ATT 區塊中的接收閘門)。
# Mix x with the previous timestep to produce xk, xr
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# The usual FFN operation
k = self . key ( xk )
k = torch . square ( torch . relu ( k )) # from the Primer paper
kv = self . value ( k )
# Apply an extra receptance-gate to kv
rkv = torch . sigmoid ( self . receptance ( xr )) * kv
return rkvself.value、self.receptance 矩陣皆初始化為零。

令 F[t] 為 t 時的系統狀態。
令 x[t] 為 t 處的新外部輸入。
在 GPT 中,預測 F[t+1] 需要考慮 F[0]、F[1]、.. F[t]。所以生成長度為T的序列需要O(T^2)。
GPT 的簡化公式:
它在理論上非常強大,但這並不意味著我們可以透過通常的優化器來充分利用它的功能。我懷疑損失情況對於我們目前的方法來說太困難了。
與RWKV的簡化公式相比(平行模式,看起來類似Apple的AFT):
R、K、V 是可訓練矩陣,W 是可訓練向量(每個通道的時間衰減因子)。
在GPT中,F[i]對F[t+1]的貢獻由 加權。
在RWKV-2中,F[i]對F[t+1]的貢獻由 加權。
重點來了:我們可以將其重寫為 RNN(遞歸公式)。筆記:
因此驗證起來很簡單:
其中 A[t] 和 B[t] 分別是上一步驟的分子和分母。
我相信 RWKV 是高效能的,因為 W 就像重複應用對角矩陣。注意 (P^{-1} DP)^n = P^{-1} D^n P,因此它類似於重複應用一般可對角化矩陣。
此外,可以將其轉換為連續 ODE(有點類似於狀態空間模型)。我稍後再寫。
我有一個使用 LM(變壓器、RWKV 等)的 [文本 --> 32x32 RGB 圖像] 的想法。很快就會進行測試。
首先是LM損失(而不是L2損失),所以影像不會模糊。
其次,色彩量化。例如,僅允許 R/G/B 8 個等級。那麼圖像詞彙大小為 8x8x8 = 512(對於每個像素),而不是 2^24。因此,一個 32x32 RGB 影像 = 一個 len1024 的 vocab512(影像標記)序列,這是普通 LM 的典型輸入。 (稍後我們可以使用擴散模型來上取樣並產生 RGB888 影像。我們也許也可以使用 LM 來實現這一點。)
第三,二維位置嵌入易於模型理解。例如,將 one-hot X & Y 座標加入前 64(=32+32) 個通道。假設像素位於 x=8、y=20,那麼我們將向通道 8 和通道 52 加 1(=32+20)。此外,我們可能可以將浮動 X 和 Y 座標(標準化為 0~1 範圍)新增至另外 2 個通道。和其他定期職位。編碼也可能有幫助(將測試)。
最後,RandRound 當


