CAMEL
1.0.0

我們很自豪地推出Asclepius ,一種更先進的臨床大語言模式。由於該模型是根據綜合臨床記錄進行訓練的,因此可以透過 Huggingface 公開存取。如果您正在考慮使用 CAMEL,我們強烈建議改用 Asclepius。欲了解更多信息,請訪問此鏈接。
我們推出CAMEL ,從 LLaMA 增強的臨床適應模型。作為 LLaMA 的基礎, CAMEL進一步接受了 MIMIC-III 和 MIMIC-IV 臨床記錄的預訓練,並根據臨床說明進行了微調(圖 2)。我們對 GPT-4 的初步評估表明, CAMEL 的品質達到了 OpenAI GPT-3.5 的 96% 以上(圖 1)。根據我們來源資料的資料使用政策,我們的指令資料集和模型都將在 PhysioNet 上發布,並具有憑證存取權。為了方便複製,我們還將發布所有代碼,允許各個醫療機構使用自己的臨床記錄複製我們的模型。有關更多詳細信息,請參閱我們的部落格文章。
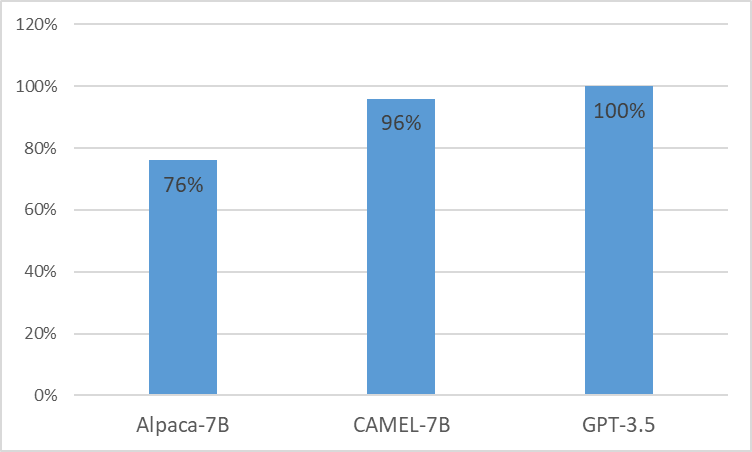
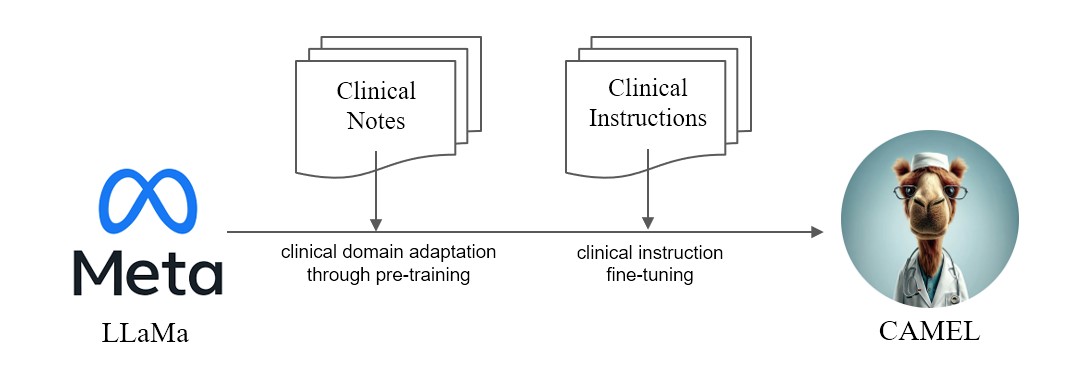
由於MIMIC和i2b2資料集的授權問題,我們無法發布指令資料集和檢查點。我們將在幾週內透過 phyonet 發布我們的模型和數據。
conda create -n camel python=3.9 -y
conda activate camel
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia -y
pip install pandarallel pandas jupyter numpy datasets sentencepiece openai fire
pip install git+https://github.com/huggingface/transformers.git@871598be552c38537bc047a409b4a6840ba1c1e4
<eos>標記連接起來。$ python pretraining_preprocess/mimiciii_preproc.py --mimiciii_note_path {MIMICIII_NOTE_PATH} --output_path {OUTPUT_PATH}$ python pretraining_preprocess/mimiciv_preproc.py --discharge_note_path {DISCHAGE_NOTE_PATH} --radiology_note_path {RADIOLOGY_NOTE_PATH} --output_path {OUTPUT_PATH}$ python pretraining_preprocess/tokenize_data.py --data_path {DATA_PATH} --save_path {SAVE_PATH} $ torchrun --nproc_per_node=8 --master_port={YOUR_PORT}
src/train.py
--model_name_or_path "decapoda-research/llama-7b-hf"
--data_path {DATA_FILE}
--bf16 True
--output_dir ./checkpoints
--num_train_epochs 1
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp "full_shard auto_wrap"
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
注意:要產生指令,您應該使用經過認證的 Azure Openai API。
指令生成
OPENAI_API_KEYOPENAI_API_BASEOPENAI_DEPLOYMENT_NAME$ python instructino/preprocess_note.py$ python instruction/de_id_gen.py --input {PREPROCESSED_NOTES} --output {OUTPUT_FILE_1} --mode inst$ python instruction/de_id_postprocess.py --input {OUTPUT_FILE_1} --output {OUTPUT_FILE_2}$ python instruction/de_id_gen.py --input {OUTPUT__FILE_2} --output {inst_output/OUTPUT_FILE_deid} --mode ans$ python instruction/instructtion_gen.py --input {PREPROCESSED_NOTES} --output {inst_output/OUTPUT_FILE} --source {mimiciii, mimiciv, i2b2}$ python instruction/merge_data.py --data_path {inst_output} --output {OUTPUT_FILE_FINAL}運行指令微調
nproc_per_node和gradient accumulate step以適合您的硬體(全域批次大小 = 128)。 $ torchrun --nproc_per_node=8 --master_port={YOUR_PORT}
src/instruction_ft.py
--model_name_or_path "decapoda-research/llama-7b-hf"
--data_path {OUTPUT_FILE_FINAL}
--bf16 True
--output_dir ./checkpoints
--num_train_epochs 3
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "epoch"
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp "full_shard auto_wrap"
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
--ddp_timeout 18000
在 MTSamples 上運行模型
CUDA_VISIBLE_DEVICES=0 python src/evaluate.py
--model_name {MODEL_PATH}
--data_path eval/mtsamples_instructions.json
--output_path {OUTPUT_PATH}
eval資料夾中將 GPT-3.5、Alpaca 和 CAMEL 產生的輸出作為mtsamples_results.json提供。運行 GPT-4 進行評估
python eval/gpt4_evaluate.py --input {INPUT_PATH} --output {OUTPUT_PATH}
@misc{CAMEL,
title = {CAMEL : Clinically Adapted Model Enhanced from LLaMA},
author = {Sunjun Kweon and Junu Kim and Seongsu Bae and Eunbyeol Cho and Sujeong Im and Jiyoun Kim and Gyubok Lee and JongHak Moon and JeongWoo Oh and Edward Choi},
month = {May},
year = {2023}
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/starmpcc/CAMEL}},
}


