PatrickStar
v0.4.6

請參閱 CHANGE_LOG.md。
預訓練模式(PTM)正成為自然語言處理研究和產業應用的熱點。然而,PTM 的訓練需要大量的硬體資源,因此只有 AI 社群中的一小部分人可以使用。現在, PatrickStar 將為所有人提供 PTM 培訓!
記憶體不足錯誤 (OOM) 是每個訓練 PTM 的工程師的噩夢。我們經常需要引入更多的 GPU 來儲存模型參數,以防止此類錯誤。 PatrickStar為此類問題帶來了更好的解決方案。透過異質訓練(DeepSpeed Zero Stage 3 也使用它),PatrickStar 可以充分利用 CPU 和 GPU 內存,這樣您就可以使用更少的 GPU 來訓練更大的模型。
派崔克的想法是這樣的。非模型資料(主要是啟動)在訓練過程中會發生變化,但目前的異質訓練解決方案是將模型資料靜態分割到CPU和GPU上。為了更好地使用 GPU,PatrickStar 提出借助基於區塊的記憶體管理模組進行動態記憶體調度。 PatrickStar的記憶體管理支援將模型目前運算部分以外的所有內容卸載到CPU以節省GPU。此外,當擴展到多個 GPU 時,基於區塊的記憶體管理對於集體通訊非常有效。請參閱論文和本文檔以了解 PatrickStar 背後的想法。
在實驗中,Patrickstar v0.4.3能夠在微信資料中心節點上使用8xTesla V100 GPU和240GB GPU記憶體訓練180億(18B)參數的模型,其網路拓撲如下。 PatrickStar 的大小是 DeepSpeed 的兩倍以上。對於相同尺寸的模型,PatrickStar 的性能也更好。 pstar 是 PatrickStar v0.4.3。 Deeps 使用官方範例 DeepSpeed 範例 Zero3 階段表示 DeepSpeed v0.4.3 的效能,預設開啟啟動最佳化。

我們也在 A100 SuperPod 的單一節點上評估了 PatrickStar v0.4.3。它可以在具有 1TB CPU 記憶體的 8xA100 上訓練 68B 模型,比 DeepSpeed v0.5.7 大 6 倍以上。除了模型規模之外,PatrickStar 比 DeepSpeed 更有效率。基準測試腳本在這裡。

微信人工智慧資料中心和 NVIDIA SuperPod 的詳細基準測試結果發佈在這個 Google Doc 上。
將 PatrickStar 擴展到 SuperPod 上的多台機器(節點)。我們成功在 32 GPU 上訓練 GPT3-175B。據我們所知,在如此小的GPU叢集上運行GPT3還是第一個作品。微軟使用了 10,000 個 V100 來支援 GPT3。現在您可以對其進行微調,甚至可以在 32 A100 GPU 上預先訓練您自己的模型,太棒了!

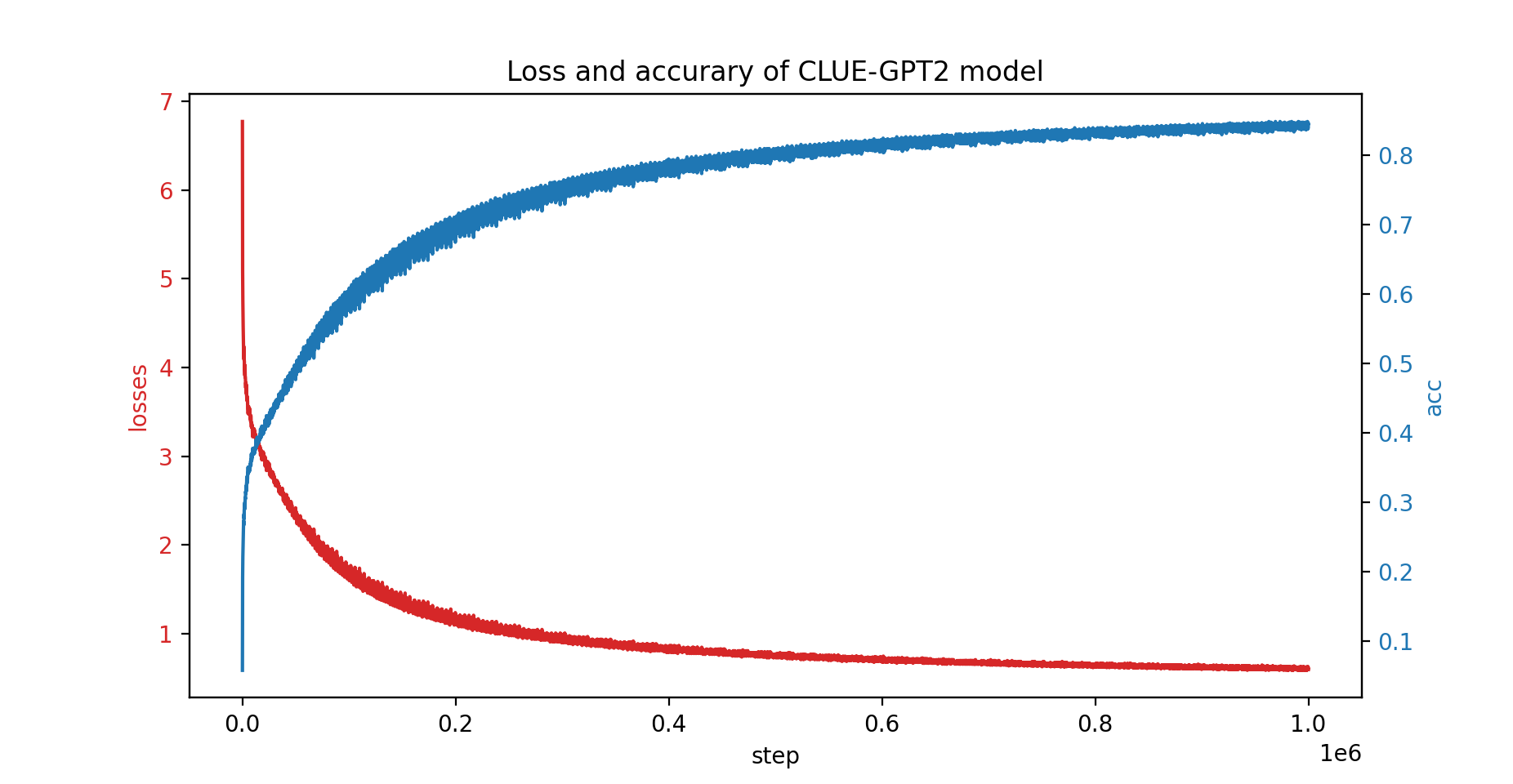
我們也用PatrickStar訓練了CLUE-GPT2模型,損失和準確率曲線如下:
pip install .請注意,PatrickStar 需要版本 7 或更高版本的 gcc。您也可以使用 NVIDIA NGC 影像,以下影像經過測試:
docker pull nvcr.io/nvidia/pytorch:21.06-py3PatrickStar 基於 PyTorch,可以輕鬆遷移 PyTorch 專案。以下是 PatrickStar 的範例:
from patrickstar . runtime import initialize_engine
config = {
"optimizer" : {
"type" : "Adam" ,
"params" : {
"lr" : 0.001 ,
"betas" : ( 0.9 , 0.999 ),
"eps" : 1e-6 ,
"weight_decay" : 0 ,
"use_hybrid_adam" : True ,
},
},
"fp16" : { # loss scaler params
"enabled" : True ,
"loss_scale" : 0 ,
"initial_scale_power" : 2 ** 3 ,
"loss_scale_window" : 1000 ,
"hysteresis" : 2 ,
"min_loss_scale" : 1 ,
},
"default_chunk_size" : 64 * 1024 * 1024 ,
"release_after_init" : True ,
"use_cpu_embedding" : False ,
"client" : {
"mem_tracer" : {
"use_async_mem_monitor" : args . with_async_mem_monitor ,
}
},
}
def model_func ():
# MyModel is a derived class for torch.nn.Module
return MyModel (...)
model , optimizer = initialize_engine ( model_func = model_func , local_rank = 0 , config = config )
...
for data in dataloader :
optimizer . zero_grad ()
loss = model ( data )
model . backward ( loss )
optimizer . step ()我們使用與 DeepSpeed 配置 JSON 相同的config格式,主要包括優化器、損失縮放器的參數和一些 PatrickStar 特定的配置。
有關上述範例的詳細說明,請查看此處的指南
如需更多範例,請查看此處。
這裡有一個快速啟動基準測試腳本。它是用隨機產生的數據執行的;因此您不需要準備真實資料。它還演示了 patrickstar 的所有優化技術。有關執行基準測試的更多最佳化技巧,請參閱最佳化選項。
BSD 3 條款許可證
@article{fang2021patrickstar,
title={PatrickStar: Parallel Training of Pre-trained Models via a Chunk-based Memory Management},
author={Fang, Jiarui and Yu, Yang and Zhu, Zilin and Li, Shenggui and You, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2108.05818},
year={2021}
}
@article{fang2022parallel,
title={Parallel Training of Pre-Trained Models via Chunk-Based Dynamic Memory Management},
author={Fang, Jiarui and Zhu, Zilin and Li, Shenggui and Su, Hui and Yu, Yang and Zhou, Jie and You, Yang},
journal={IEEE Transactions on Parallel and Distributed Systems},
volume={34},
number={1},
pages={304--315},
year={2022},
publisher={IEEE}
}
{jiaruifang, zilinzhu, josephyu}@tencent.com
由微信 AI 團隊、騰訊 NLP Oteam 提供支援。


