xcodec
1.0.0
音頻語言模型的統一語義和聲學編解碼器。
標題:編解碼器確實很重要:探索音訊語言模型編解碼器的語意缺點
作者:葉震、孫培文、雷嘉禾、林紅戰、譚旭、戴哲琪、孔秋強、陳建一、潘家豪、劉奇峰、郭一克*、薛偉*
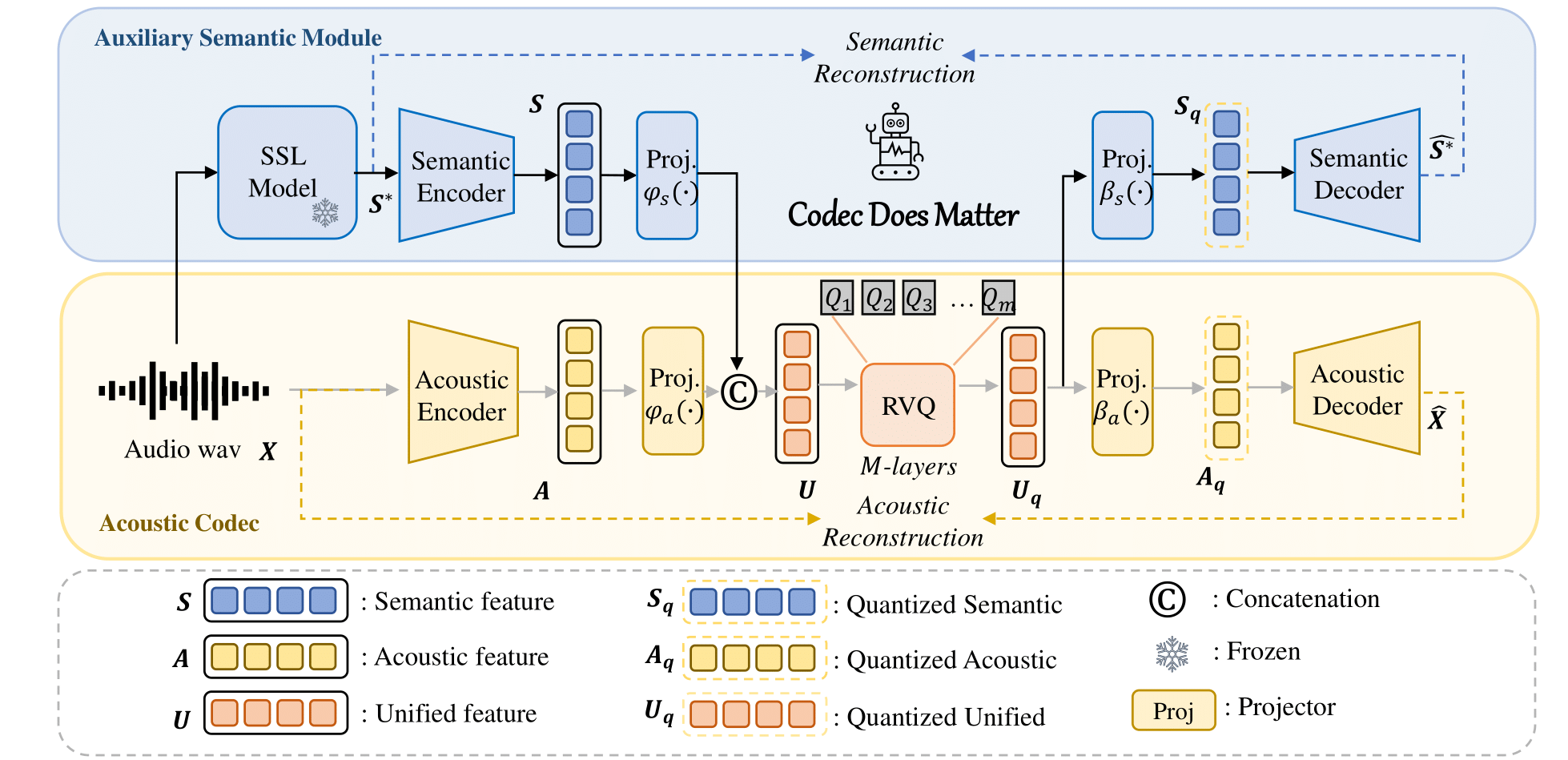
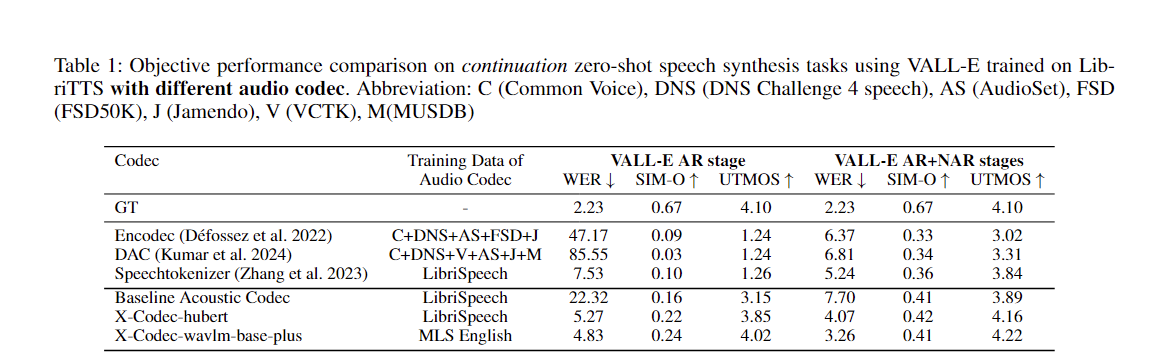
您可以輕鬆應用我們的方法來增強任何現有的聲學編解碼器:
例如
class Codec ():
def __init__ ( self ):
# Acoustic codec components
self . encoder = Encoder (...) # Acoustic encoder
self . decoder = Decoder (...) # Acoustic decoder
self . quantizer = RVQ (...) # Residual Vector Quantizer (RVQ)
# Adding the semantic module
self . semantic_model = AutoModel . from_pretrained (...) # e.g., Hubert, WavLM
# Adding Projector
self . fc_prior = nn . Linear (...)
self . fc_post1 = nn . Linear (...)
self . fc_post2 = nn . Linear (...)
def forward ( self , x , bw ):
# Encode the input acoustically and semantically
e_acoustic = self . encoder ( x )
e_semantic = self . semantic_model ( x )
# Combine acoustic and semantic features
combined_features = torch . cat ([ e_acoustic , e_semantic ])
# Apply prior transformation
transformed_features = self . fc_prior ( combined_features )
# Quantize the unified semantic and acoustic features
quantized , codes , bandwidth , commit_loss = self . quantizer ( transformed_features , bw )
# Post-process the quantized features
quantized_semantic = self . fc_post1 ( quantized )
quantized_acoustic = self . fc_post2 ( quantized )
# Decode the quantized acoustic features
output = self . decoder ( quantized_acoustic )
def semantic_loss ( self , semantic , quantized_semantic ):
return F . mse_loss ( semantic , quantized_semantic ) 欲了解更多詳情,請參閱我們的程式碼。
?連結到 Huggingface 模型中心。
| 型號名稱 | 抱臉 | 配置 | 語意模型 | 領域 | 訓練資料 |
|---|---|---|---|---|---|
| xcodec_hubert_librispeech | ? | ? | ?休伯特基 | 演講 | 書本演講 |
| xcodec_wavlm_mls(論文中未提及) | ? | ? | ? Wavlm-base-plus | 演講 | 木林森英語 |
| xcodec_wavlm_more_data(論文中未提及) | ? | ? | ? Wavlm-base-plus | 演講 | MLS 英文+內部數據 |
| xcodec_hubert_general_audio | ? | ? | ?Hubert-base-通用音頻 | 通用音訊 | 20萬小時內部數據 |
| xcodec_hubert_general_audio_more_data(論文中未提及) | ? | ? | ?Hubert-base-通用音頻 | 通用音訊 | 數據更均衡 |
要運行推理,請先從 Hugging Face 下載模型和配置。
python inference.py在config中準備training_file和validation_file。該文件應列出音訊檔案的路徑:
/path/to/your/xxx.wav
/path/to/your/yyy.wav
...然後:
torchrun --nnodes=1 --nproc-per-node=8 main_launch_vqdp.py我要特別感謝 Uniaudio 和 DAC 的作者,因為我們的程式碼庫主要藉鑒了 Uniaudio 和 DAC。
如果您發現此儲存庫有幫助,請考慮按以下格式引用:
@article { ye2024codecdoesmatterexploring ,
title = { Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model } ,
author = { Zhen Ye and Peiwen Sun and Jiahe Lei and Hongzhan Lin and Xu Tan and Zheqi Dai and Qiuqiang Kong and Jianyi Chen and Jiahao Pan and Qifeng Liu and Yike Guo and Wei Xue } ,
journal = { arXiv preprint arXiv:2408.17175 } ,
year = { 2024 } ,
}

