graph gpt
v0.4.0
該儲存庫是 PyTorch 中「GraphGPT:使用生成式預訓練 Transformers 進行圖學習」的官方實作。
GraphGPT:使用生成式預訓練 Transformer 進行圖學習
趙其芳、任衛東、李天宇、徐瀟瀟、劉紅
2024 年 10 月 13 日
CHANGELOG.md了解詳細資訊。2024年8月18日
CHANGELOG.md了解詳細資訊。2024年7月9日
2024年3月19日
permute_nodes ,以增加歐拉路徑的變化,並產生更好、更穩健的結果。StackedGSTTokenizer使得語義(即節點/邊屬性)標記可以與結構標記堆疊在一起,並且序列的長度將減少很多。2024年1月23日
2024年1月3日

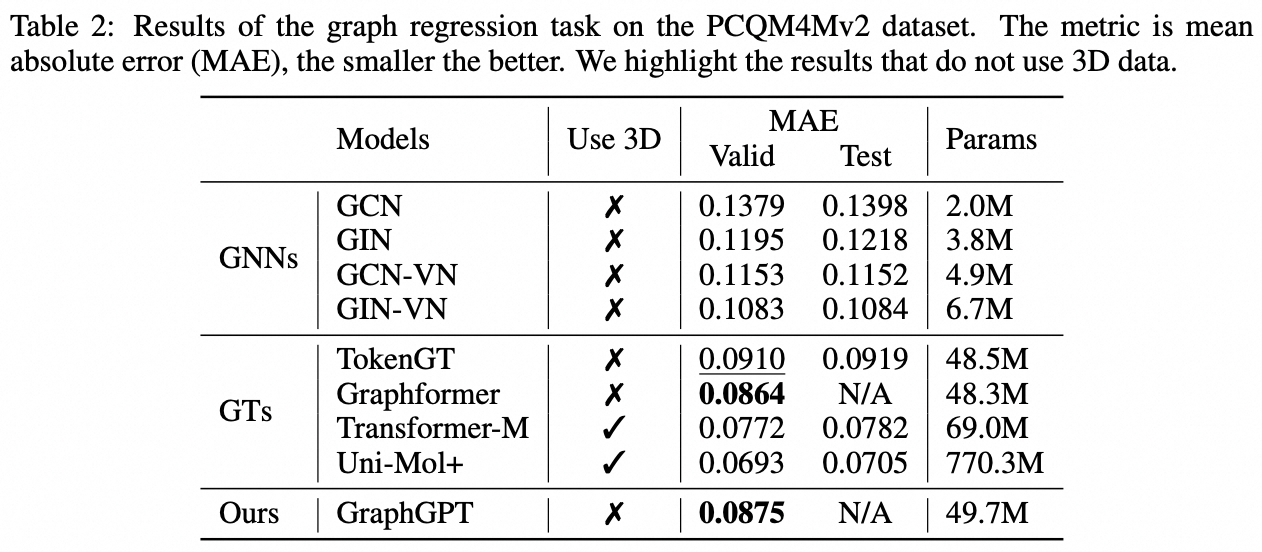
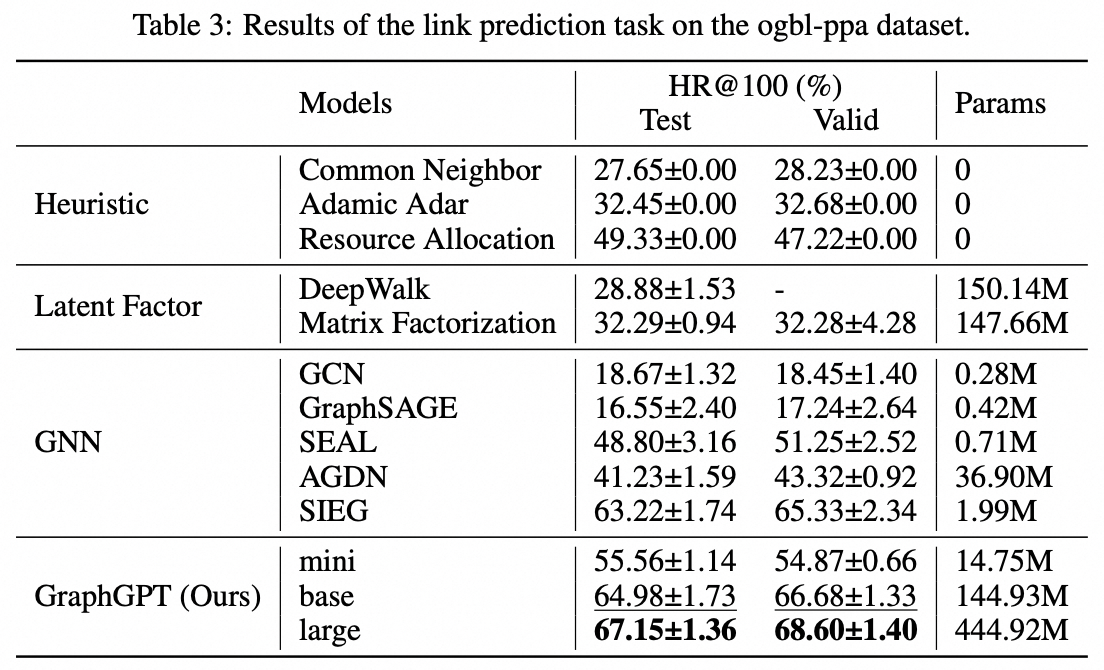
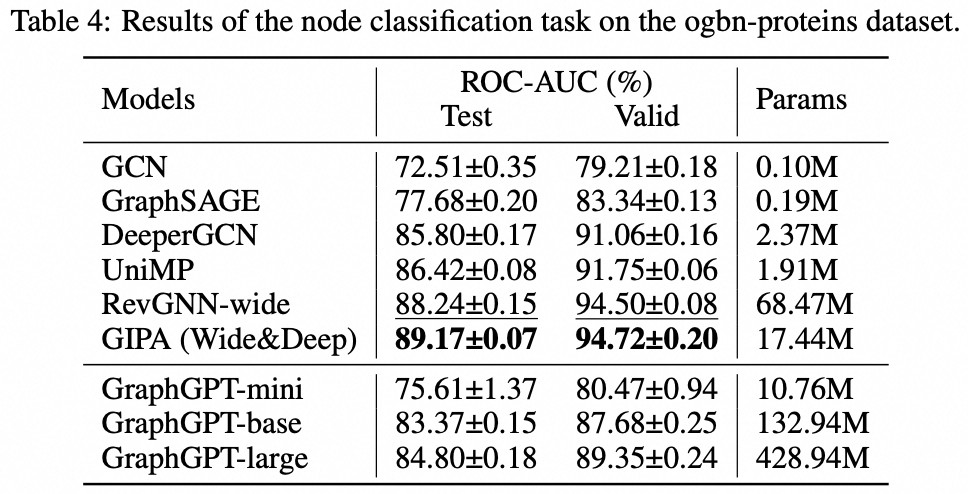
我們提出了 GraphGPT,這是一種透過自監督產生預訓練圖歐拉變換器(GET)進行圖學習的新模型。我們首先介紹 GET,它由一個普通的 Transformer 編碼器/解碼器主幹和一個轉換組成,該轉換將每個圖或取樣子圖轉換為使用歐拉路徑可逆地表示節點、邊和屬性的標記序列。然後,我們使用下一個令牌預測 (NTP) 任務或計畫的屏蔽令牌預測 (SMTP) 任務來預先訓練 GET。最後,我們根據監督任務對模型進行微調。這種直觀而有效的模型在大規模分子資料集 PCQM4Mv2、蛋白質-蛋白質關聯資料集 ogbl-ppa 上實現了優於或接近最先進的圖形、邊緣和節點級任務的結果、來自開放圖基準(OGB ) 的引文網絡資料集ogbl-itation2 和ogbn-蛋白質資料集。此外,生成式預訓練使我們能夠訓練 GraphGPT 高達 2B+ 的參數,並且性能不斷提高,這超出了 GNN 和先前的圖轉換器的能力。
將歐拉圖轉換為序列後,有多種不同的方法將節點和邊屬性附加到序列。我們將這些方法命名為short 、 long和prolonged 。
給定圖,我們首先對其進行歐拉化,然後將其轉換為等價序列。然後,我們循環地重新索引節點。
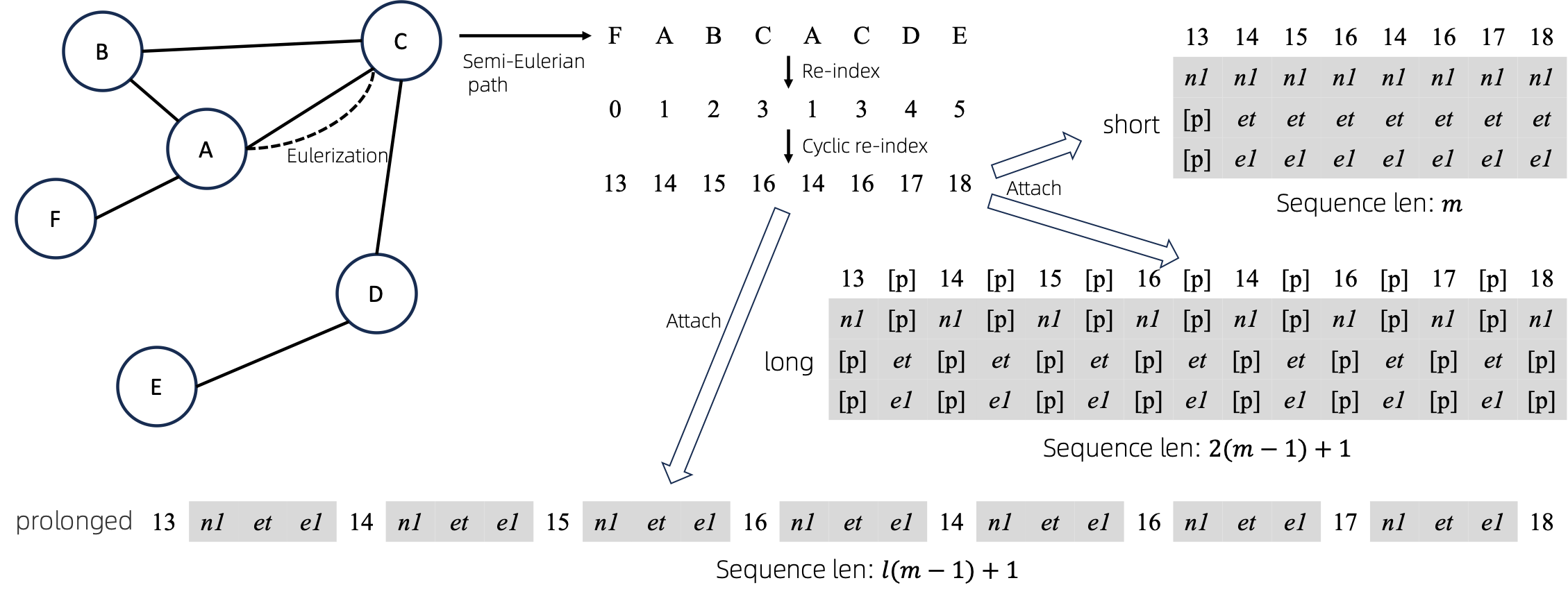
假設圖有1個節點屬性和1個邊屬性,則short 、 long 、 prolong法如上圖所示。
上圖中, n1 、 n2和e1表示節點和邊屬性的標記, [p]表示填充標記。
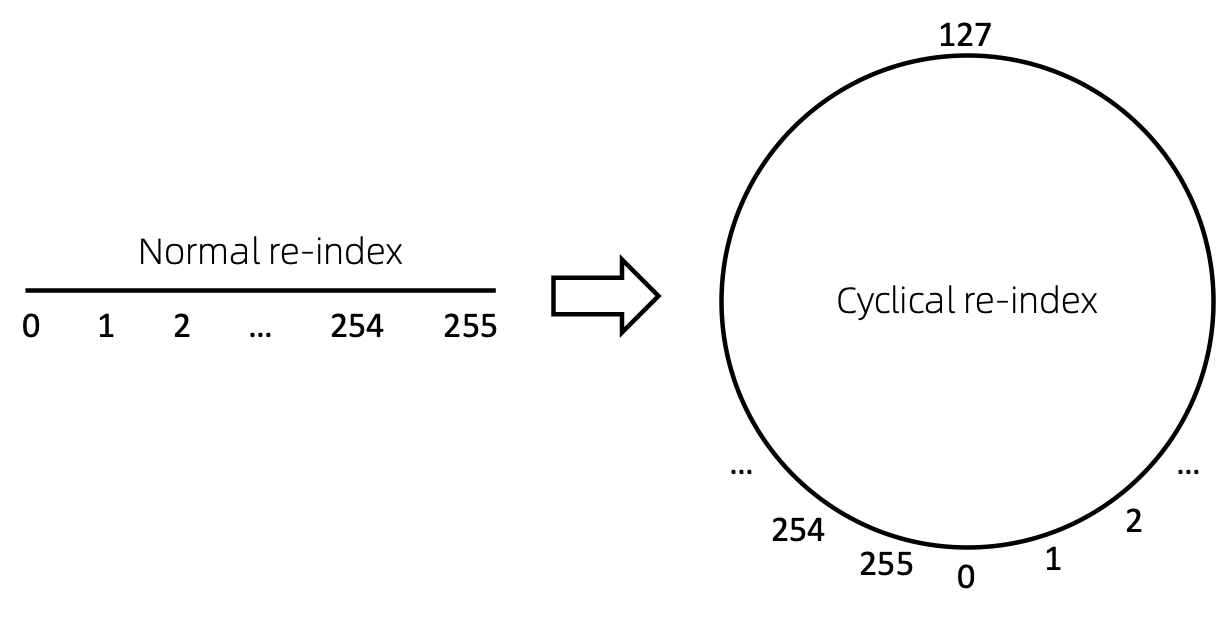
重新索引節點序列的一種直接方法是從 0 開始並遞增地新增 1。這樣,小索引的 token 將得到充分的訓練,而大索引則不會。為了255這個問題,我們提出了cyclical re-index ,它以給定範圍內的隨機數開始,例如[0, 255] ,然後遞增 1。
過時了。即將更新。
git clone https://github.com/alibaba/graph-gpt.gitconda create -n graph_gpt python=3.8 pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
conda activate graph_gpt
cd graph-gpt
pip install -r ./requirements.txt
pip install torch-scatter torch-sparse -f https://data.pyg.org/whl/torch-1.13.1+cpu.html
sudo apt-get install bc資料集是使用 python 套件 ogb 下載的。
當您執行./examples中的腳本時,將自動下載資料集。
然而,資料集PCQM4M-v2很大,下載和預處理可能會出現問題。我們建議cd ./src/utils/和python dataset_utils.py分別下載和預處理資料集。
./examples/graph_lvl/pcqm4m_v2_pretrain.sh中的參數,例如dataset_name 、 model_name 、 batch_size 、 workerCount等,然後運行./examples/graph_lvl/pcqm4m_v2_pretrain.sh ../examples/toy_examples/reddit_pretrain.sh 。./examples/graph_lvl/pcqm4m_v2_supervised.sh中./examples/graph_lvl/pcqm4m_v2_supervised.sh參數,例如dataset_name 、 model_name 、 batch_size 、 workerCount 、 pretrain_cpt等,然後執行下游任務進行微調。./examples/toy_examples/reddit_supervised.sh 。 .pre-commit-config.yaml :為 python 建立包含以下內容的文件 repos :
- repo : https://github.com/pre-commit/pre-commit-hooks
rev : v4.4.0
hooks :
- id : check-yaml
- id : end-of-file-fixer
- id : trailing-whitespace
- repo : https://github.com/psf/black
rev : 23.7.0
hooks :
- id : blackpre-commit install :將 pre-commit 安裝到你的 git hooks 中。pre-commit install應該始終是您要做的第一件事。pre-commit run --all-files :在儲存庫上執行所有預提交掛鉤pre-commit autoupdate :自動將您的掛鉤更新到最新版本git commit -n :可以使用以下命令停用特定提交的預提交檢查如果您發現這項工作有用,請引用以下論文:
@article{zhao2024graphgpt,
title={GraphGPT: Graph Learning with Generative Pre-trained Transformers},
author={Zhao, Qifang and Ren, Weidong and Li, Tianyu and Xu, Xiaoxiao and Liu, Hong},
journal={arXiv preprint arXiv:2401.00529},
year={2024}
}趙其芳 ([email protected])
衷心感謝您對我們工作的建議!
根據 MIT 許可證發布(參見LICENSE ):
Ali-GraphGPT-project is an AI project on training large scale transformer decoder with graph datasets,
developed by Alibaba and licensed under the MIT License.


