YAYI2
1.0.0

[README] [?HF Repo] [?網頁端]
中文| English
[2024.03.28] 所有模式和資料上魔術搭社群。
[2023.12.22] 我們發布了技術報告YAYI 2: Multilingual Open-Source Large Language Models。
YAYI 2 是中科聞歌研發的新一代開源大語言模型,包含Base 和Chat 版本,參數規模為30B。 YAYI2-30B 是基於Transformer 的大語言模型,採用了超過2 兆Tokens 的高品質、多語言語料進行預訓練。針對通用和特定領域的應用場景,我們採用了百萬級指令進行微調,同時藉助人類反饋強化學習方法,以更好地使模型與人類價值觀對齊。
本次開源的模型為YAYI2-30B Base 模型。我們希望透過雅意大模型的開源來促進中文預訓練大模型開源社群的發展,並積極為此做出貢獻。透過開源,我們與每位合作夥伴共同建構雅意大模型生態。
更多技術細節,歡迎閱讀我們的技術報告YAYI 2: Multilingual Open-Source Large Language Models。
| 資料集名稱 | 大小 | ? HF模型標識 | 下載地址 | 魔搭模型標識 | 下載地址 |
|---|---|---|---|---|---|
| YAYI2 Pretrain Data | 500G | wenge-research/yayi2_pretrain_data | 資料集下載 | wenge-research/yayi2_pretrain_data | 資料集下載 |
| 模型名稱 | 上下文長度 | ? HF模型標識 | 下載地址 | 魔搭模型標識 | 下載地址 |
|---|---|---|---|---|---|
| YAYI2-30B | 4096 | wenge-research/yayi2-30b | 模型下載 | wenge-research/yayi2-30b | 模型下載 |
| YAYI2-30B-Chat | 4096 | wenge-research/yayi2-30b-chat | Comming soon... |
我們在多個基準資料集上進行了評測,包括C-Eval、MMLU、 CMMLU、AGIEval、GAOKAO-Bench、GSM8K、MATH、BBH、HumanEval 以及MBPP。我們考察了模型在語言理解、學科知識、數學推理、邏輯推理、以及程式碼生成的表現。 YAYI 2 模型在與其規模相近的開源模型中展現了顯著的效能提升。
| 學科知識 | 數學 | 邏輯推理 | 程式碼 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 模型 | C-Eval(val) | MMLU | AGIEval | CMMLU | GAOKAO-Bench | GSM8K | MATH | BBH | HumanEval | MBPP |
| 5-shot | 5-shot | 3/0-shot | 5-shot | 0-shot | 8/4-shot | 4-shot | 3-shot | 0-shot | 3-shot | |
| MPT-30B | - | 46.9 | 33.8 | - | - | 15.2 | 3.1 | 38.0 | 25.0 | 32.8 |
| Falcon-40B | - | 55.4 | 37.0 | - | - | 19.6 | 5.5 | 37.1 | 0.6 | 29.8 |
| LLaMA2-34B | - | 62.6 | 43.4 | - | - | 42.2 | 6.2 | 44.1 | 22.6 | 33.0 |
| Baichuan2-13B | 59.0 | 59.5 | 37.4 | 61.3 | 45.6 | 52.6 | 10.1 | 49.0 | 17.1 | 30.8 |
| Qwen-14B | 71.7 | 67.9 | 51.9 | 70.2 | 62.5 | 61.6 | 25.2 | 53.7 | 32.3 | 39.8 |
| InternLM-20B | 58.8 | 62.1 | 44.6 | 59.0 | 45.5 | 52.6 | 7.9 | 52.5 | 25.6 | 35.6 |
| Aquila2-34B | 98.5 | 76.0 | 43.8 | 78.5 | 37.8 | 50.0 | 17.8 | 42.5 | 0.0 | 41.0 |
| Yi-34B | 81.8 | 76.3 | 56.5 | 82.6 | 68.3 | 67.6 | 15.9 | 66.4 | 26.2 | 38.2 |
| YAYI2-30B | 80.9 | 80.5 | 62.0 | 84.0 | 64.4 | 71.2 | 14.8 | 54.5 | 53.1 | 45.8 |
我們使用OpenCompass Github 倉庫提供的原始碼進行了評測。對於對比模型,我們列出了他們在OpenCompass 名單上的評測結果,截止日期為2023年12月15日。對於其他尚未在OpenCompass 平台參與評測的模型,包括MPT、Falcon 和LLaMa 2,我們採用了LLaMA 2 報告的結果。
我們提供簡單的範例來說明如何快速使用YAYI2-30B進行推理。此範例可在單張A100/A800 上運作。
git clone https://github.com/wenge-research/YAYI2.git
cd YAYI2conda create --name yayi_inference_env python=3.8
conda activate yayi_inference_env請注意,本專案需要Python 3.8 或更高版本。
pip install transformers==4.33.1
pip install torch==2.0.1
pip install sentencepiece==0.1.99
pip install accelerate==0.25.0
>> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi2-30b" , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi2-30b" , device_map = "auto" , trust_remote_code = True )
>> > inputs = tokenizer ( 'The winter in Beijing is' , return_tensors = 'pt' )
>> > inputs = inputs . to ( 'cuda' )
>> > pred = model . generate (
** inputs ,
max_new_tokens = 256 ,
eos_token_id = tokenizer . eos_token_id ,
do_sample = True ,
repetition_penalty = 1.2 ,
temperature = 0.4 ,
top_k = 100 ,
top_p = 0.8
)
>> > print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))當您首次造訪時,需要下載並載入模型,可能會花費一些時間。
本計畫支援基於分散式訓練框架deepspeed 進行指令微調,配置好環境並執行對應腳本即可啟動全參數微調或LoRA 微調。
conda create --name yayi_train_env python=3.10
conda activate yayi_train_envpip install -r requirements.txtpip install --upgrade acceleratepip install flash-attn==2.0.3 --no-build-isolation
pip install triton==2.0.0.dev20221202 --no-deps 資料格式:參考data/yayi_train_example.json ,是一個標準JSON 文件,每個資料由"system"和"conversations"組成,其中"system"為全域角色設定訊息,可為空字串, "conversations"是由human 和yayi 兩種角色交替進行的多輪對話內容。
運行說明:執行以下指令即可開始全參數微調雅意模型,支援多機多卡訓練,建議使用16*A100(80G) 或以上硬體配置。
deepspeed --hostfile config/hostfile
--module training.trainer_yayi2
--report_to " tensorboard "
--data_path " ./data/yayi_train_example.json "
--model_name_or_path " your_model_path "
--output_dir " ./output "
--model_max_length 2048
--num_train_epochs 1
--per_device_train_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 10
--learning_rate 5e-6
--warmup_steps 2000
--lr_scheduler_type cosine
--logging_steps 1
--gradient_checkpointing True
--deepspeed " ./config/deepspeed.json "
--bf16 True 或透過命令列啟動:
bash scripts/start.sh請注意,如需使用ChatML 模版進行指令微調,可將指令中的--module training.trainer_yayi2修改為--module training.trainer_chatml ;如需或自訂Chat 模版,可修改trainer_chatml.py 的Chat 模版中system 、user、assistant 三種角色的special token 定義。以下是ChatML 模版範例,如果訓練時使用該模版或自訂模版,推理時也需要保持一致。
<|im_start|>system
You are a helpful and harmless assistant named YAYI.<|im_end|>
<|im_start|>user
Hello!<|im_end|>
<|im_start|>assistant
Hello! How can I assist you today?<|im_end|>
<|im_start|>user
1+1=<|im_end|>
<|im_start|>assistant
1+1 equals 2.<|im_end|>
bash scripts/start_lora.sh在預訓練階段,我們不僅使用了互聯網數據來訓練模型的語言能力,還添加了通用精選數據和領域數據,以增強模型的專業技能。數據分佈情況如下: 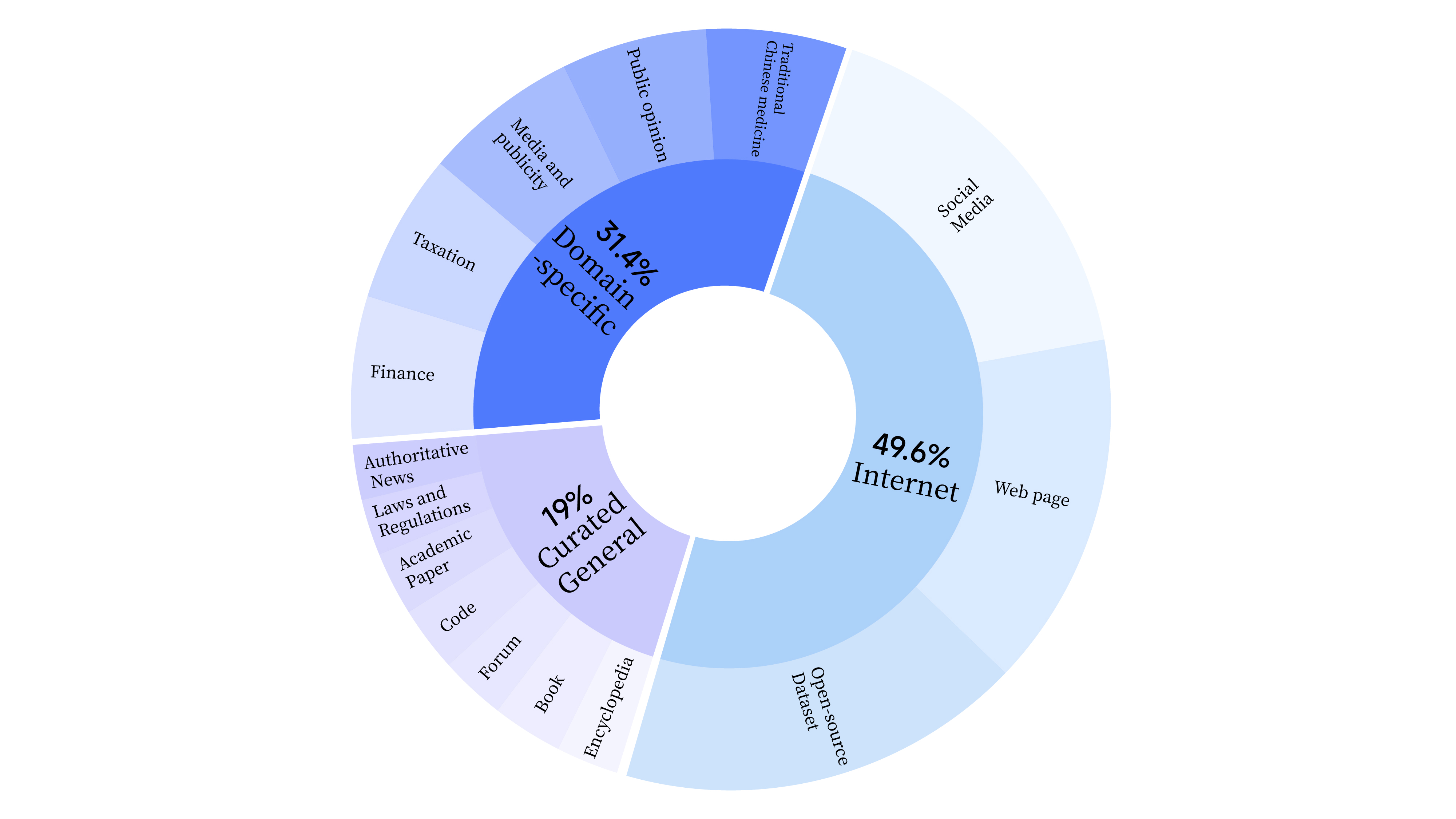
我們建構了一套全方位提升資料品質的資料處理管線,包括標準化、啟發式清洗、多層次去重、毒性過濾四個模組。我們共收集了240TB 原始數據,預處理後僅剩10.6TB 高品質數據。整體流程如下: 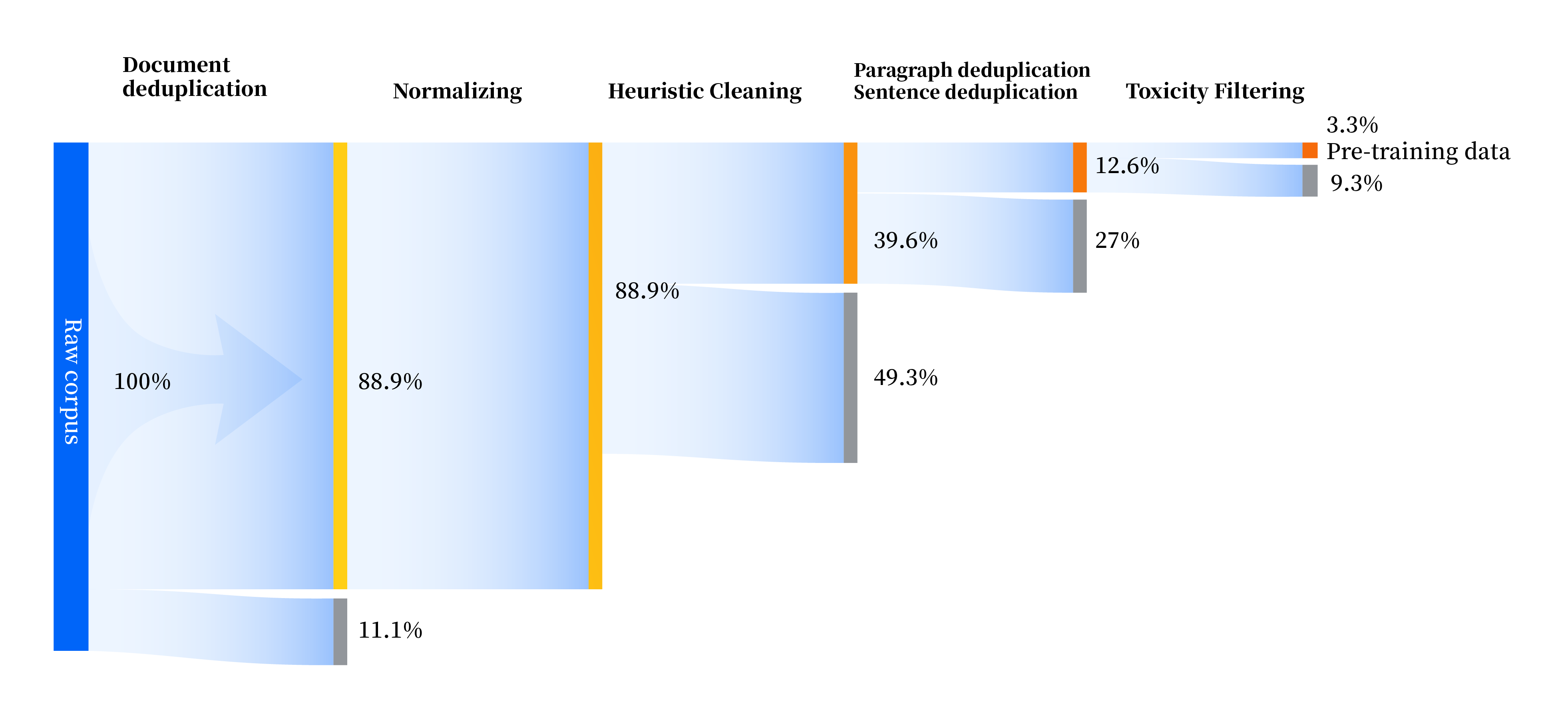

YAYI 2 模型的loss 曲線見下圖: 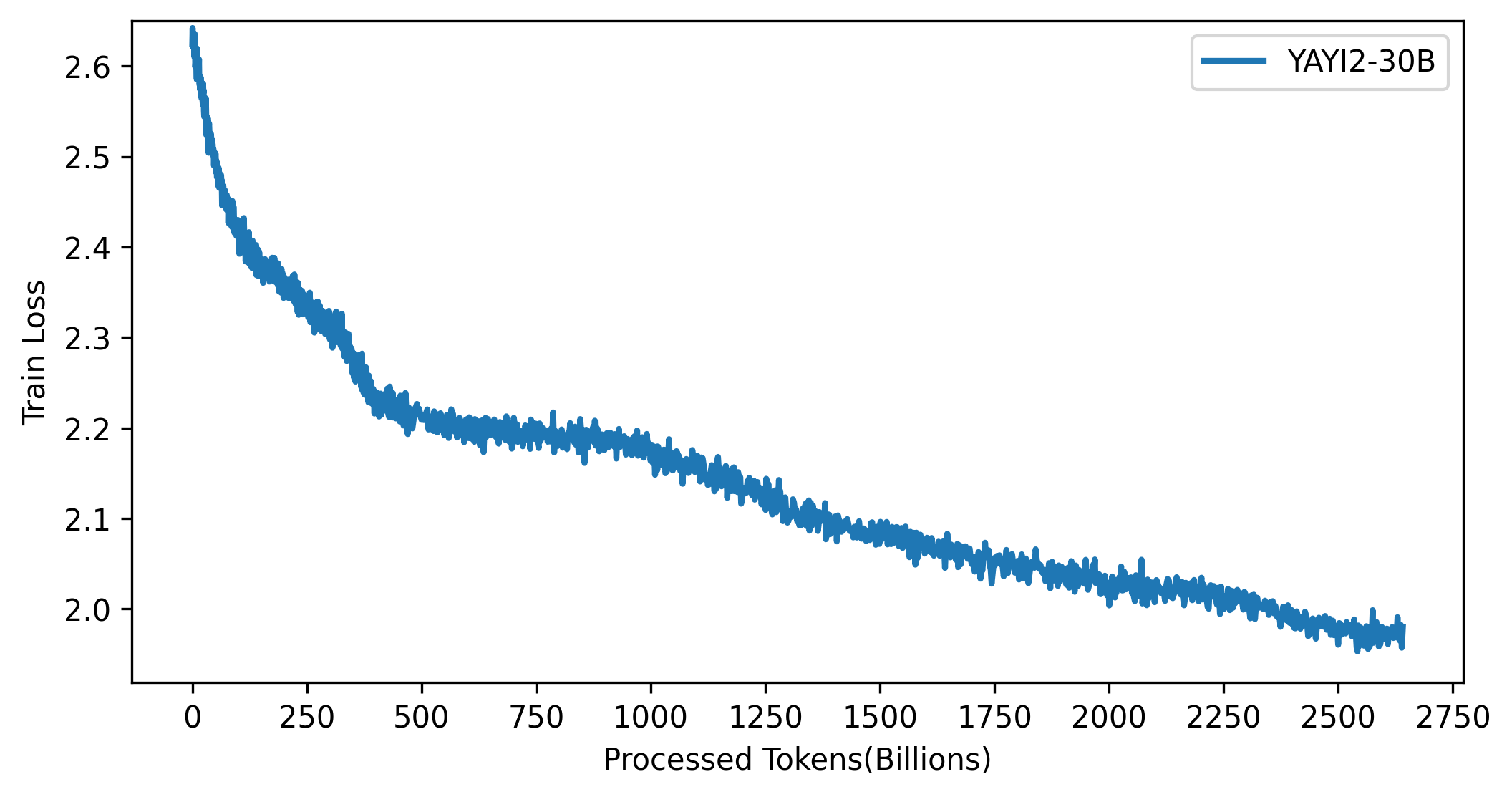
本專案中的程式碼依照Apache-2.0 協議開源,社群使用YAYI 2 模型和資料需要遵循《雅意YAYI 2 模型社群授權協議》。若您需要將雅意YAYI 2系列模型或其衍生品用作商業用途,請完整填寫《雅意YAYI 2 模型商用登記資訊》,並發送至[email protected],收到郵件後我們將在3個工作日進行審核,通過審核後您將收到商用許可證,請您在使用過程中嚴格遵守《雅意YAYI 2 模型商用許可協議》的相關內容,感謝您的配合!
如果您在工作中使用了我們的模型,請引用我們的論文:
@article{YAYI 2,
author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.},
title = {YAYI 2: Multilingual Open Source Large Language Models},
journal = {arXiv preprint arXiv:2312.14862},
url = {https://arxiv.org/abs/2312.14862},
year = {2023}
}


