Copulas
v0.12.0 - 2024-11-12
此儲存庫是 DataCebo 的綜合資料倉儲專案的一部分。

Copulas是一個 Python 函式庫,用於對多元分佈進行建模並使用 copula 函數對其進行取樣。給定一個數值資料表,使用 Copulas 來學習分佈並根據相同的統計屬性產生新的合成資料。
主要特點:
對多元資料建模。從各種單變量分佈和聯結函數中進行選擇 - 包括阿基米德聯結函數、高斯聯結函數和藤蔓聯結函數。
建構模型後,直觀地比較真實數據和合成數據。視覺化形式包括 1D 直方圖、2D 散佈圖和 3D 散佈圖。
存取和操作學習的參數。透過完全存取模型的內部結構,可以根據您的選擇設定或調整參數。
使用 pip 或 conda 安裝 Copulas 函式庫。
pip install copulasconda install -c conda-forge copulas開始使用演示資料集。此資料集包含 3 個數字列。
from copulas . datasets import sample_trivariate_xyz
real_data = sample_trivariate_xyz ()
real_data . head ()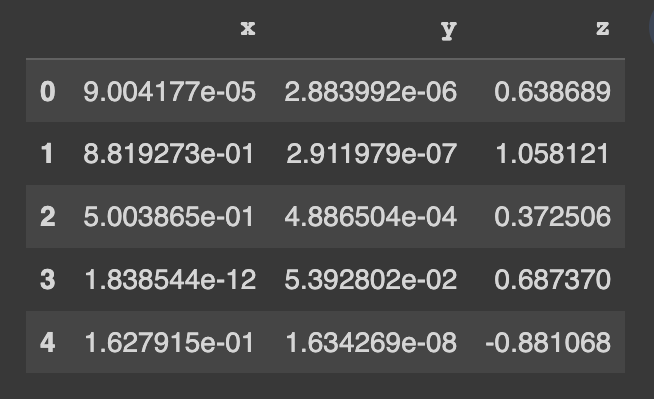
使用聯結對資料進行建模並使用它來建立合成資料。 Copulas 庫提供了許多選項,包括高斯 Copula、Vine Copula 和阿基米德 Copula。
from copulas . multivariate import GaussianMultivariate
copula = GaussianMultivariate ()
copula . fit ( real_data )
synthetic_data = copula . sample ( len ( real_data ))並排可視化真實數據和合成數據。讓我們以 3D 形式進行此操作,以便查看完整的資料集。
from copulas . visualization import compare_3d
compare_3d ( real_data , synthetic_data )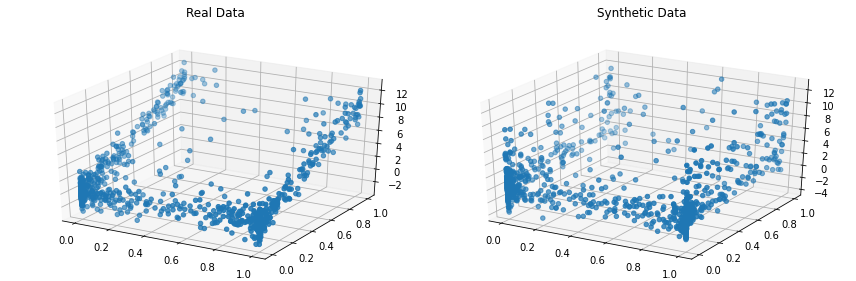
點擊下面,在 Colab Notebook 上自行執行程式碼並發現新功能。
從我們的文件網站了解有關 Copulas 庫的更多資訊。
有疑問或問題嗎?加入我們的 Slack 頻道,討論有關 Copulas 和合成數據的更多資訊。如果您發現錯誤或有功能請求,您也可以在我們的 GitHub 上提出問題。
有興趣為 Copulas 做出貢獻嗎?請閱讀我們的貢獻指南以開始使用。
Copulas 開源專案於 2018 年首次在麻省理工學院的數據到人工智慧實驗室啟動。
查看貢獻者

綜合資料庫計畫於 2016 年在麻省理工學院的數據到人工智慧實驗室首次創建。如今,DataCebo 是 SDV 的自豪開發商,SDV 是最大的合成資料生成和評估生態系統。它是多個支援合成資料的庫的所在地,包括:
開始使用 SDV 套件——一個完全整合的解決方案和合成資料的一站式商店。或者,使用獨立庫來滿足特定需求。


