JoyVASA
1.0.0
曹旭陽1*王國新12*石盛 1*趙軍1楊耀1
費金濤1高敏宇1
1京東健康國際有限公司2浙江大學
音訊驅動的肖像動畫在基於擴散的模型方面取得了重大進展,提高了視訊品質和口型同步準確性。然而,這些模型日益複雜,導致訓練和推理效率低下,以及影片長度和幀間連續性的限制。在本文中,我們提出了 JoyVASA,一種基於擴散的方法,用於在音訊驅動的臉部動畫中產生臉部動態和頭部運動。具體來說,在第一階段,我們引入了一個解耦的面部表示框架,它將動態面部表情與靜態 3D 面部表示分開。這種解耦允許系統透過將任何靜態 3D 面部表徵與動態運動序列相結合來產生更長的視訊。然後,在第二階段,訓練擴散變壓器直接根據音訊提示產生運動序列,而與角色身份無關。最後,在第一階段訓練的生成器使用 3D 面部表示和生成的運動序列作為輸入來渲染高品質的動畫。憑藉解耦的面部表示和獨立於身份的運動生成過程,JoyVASA 超越了人類肖像,無縫地製作了動物面部動畫。該模型在私人中文和公共英語資料的混合資料集上進行訓練,從而實現多語言支援。實驗結果驗證了我們方法的有效性。未來的工作將集中在提高即時效能和細化表情控制上,進一步擴展該框架在人像動畫方面的應用。
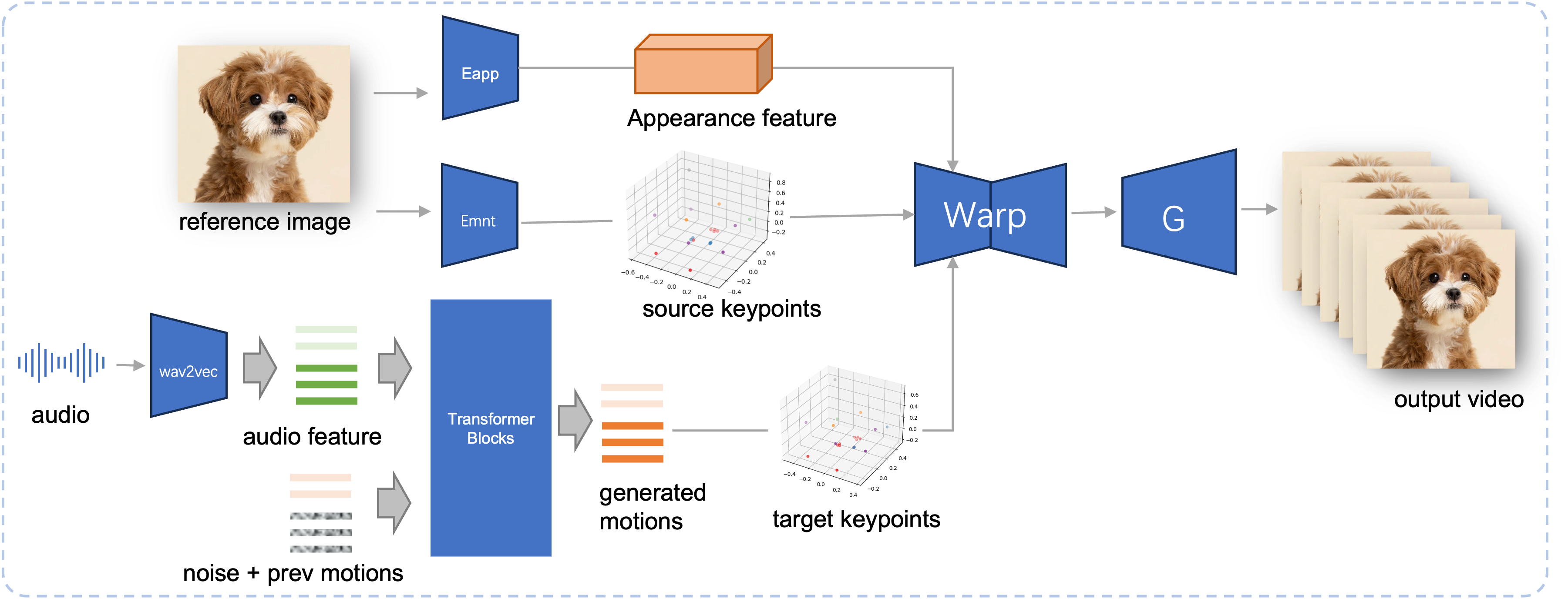
擬議的 JoyVASA 的推理管道。給定參考影像,我們首先使用 LivePortrait 中的外觀編碼器來提取 3D 臉部外觀特徵,並使用運動編碼器提取一系列學習的 3D 關鍵點。對於輸入語音,最初使用 wav2vec2 編碼器提取音訊特徵。然後使用在第二階段以滑動視窗方式訓練的擴散模型對音頻驅動的運動序列進行採樣。使用參考影像的 3D 關鍵點和取樣的目標運動序列,計算目標關鍵點。最後,3D 臉部外觀特徵會根據來源和目標關鍵點進行變形,並由生成器渲染以產生最終輸出影片。
系統需求:
烏班圖:
在 Ubuntu 20.04、Cuda 11.3 上測試
測試的 GPU:A100
視窗:
在 Windows 11、CUDA 12.1 上測試
測試的 GPU:RTX 4060 筆記型電腦 8GB VRAM GPU
創建環境:
# 1.建立基礎環境conda create -n Joyvasa python=3.10 -y conda 激活 Joyvasa # 2. 安裝requirementspip install -rrequirements.txt# 3. 安裝ffmpegsudo apt-get update sudo apt-get install ffmpeg -y# 4. 安裝 MultiScaleDeformableAttentioncd src/utils/dependencies/XPose/models/UniPose/ops python setup.py build installcd - # 等於 cd ../../../../../../../
確保您已安裝 git-lfs 並將以下所有檢查點下載到pretrained_weights :
git lfs 安裝 git 克隆 https://huggingface.co/jdh-algo/JoyVASA
我們支援兩種類型的音訊編碼器,包括 wav2vec2-base 和 hubert-chinese。
執行以下命令下載 hubert-chinese 預訓練權重:
git lfs 安裝 git克隆 https://huggingface.co/TencentGameMate/chinese-hubert-base
若要取得基於 wav2vec2 的預訓練權重,請執行下列命令:
git lfs 安裝 git 克隆 https://huggingface.co/facebook/wav2vec2-base-960h
筆記
稍後將支援帶有 wav2vec2 編碼器的運動生成模型。
# !pip install -U "huggingface_hub[cli]"huggingface-cli 下載 KwaiVGI/LivePortrait --local-dir pretrained_weights --exclude "*.git*" "README.md" "docs"
更多下載方法請參考Liveportrait。
pretrained_weights內容最終的pretrained_weights目錄應如下所示:
./pretrained_weights/
├── insightface
│ └── models
│ └── buffalo_l
│ ├── 2d106det.onnx
│ └── det_10g.onnx
├── JoyVASA
│ ├── motion_generator
│ │ └── iter_0020000.pt
│ └── motion_template
│ └── motion_template.pkl
├── liveportrait
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── landmark.onnx
│ └── retargeting_models
│ └── stitching_retargeting_module.pth
├── liveportrait_animals
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── retargeting_models
│ │ └── stitching_retargeting_module.pth
│ └── xpose.pth
├── TencentGameMate:chinese-hubert-base
│ ├── chinese-hubert-base-fairseq-ckpt.pt
│ ├── config.json
│ ├── gitattributes
│ ├── preprocessor_config.json
│ ├── pytorch_model.bin
│ └── README.md
└── wav2vec2-base-960h
├── config.json
├── feature_extractor_config.json
├── model.safetensors
├── preprocessor_config.json
├── pytorch_model.bin
├── README.md
├── special_tokens_map.json
├── tf_model.h5
├── tokenizer_config.json
└── vocab.json筆記
Windows下的TencentGameMate:chinese-hubert-base資料夾應重新命名為chinese-hubert-base 。
動物:
python inference.py -r 資產/範例/imgs/joyvasa_001.png -a 資產/範例/audios/joyvasa_001.wav --animation_mode 動物 --cfg_scale 2.0
人類:
python inference.py -r asset/examples/imgs/joyvasa_003.png -a asset/examples/audios/joyvasa_003.wav --animation_mode human --cfg_scale 2.0
您可以更改 cfg_scale 以獲得不同表情和姿勢的結果。
筆記
動畫模式和參考圖像不匹配可能會導致不正確的結果。
使用以下命令啟動 Web 演示:
蟒蛇應用程式.py
該演示將在 http://127.0.0.1:7862 建立。
如果您發現我們的工作有幫助,請考慮引用我們:
@misc{cao2024joyvasaportraitanimalimage,
title={JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation},
author={Xuyang Cao and Guoxin Wang and Sheng Shi and Jun Zhao and Yang Yao and Jintao Fei and Minyu Gao},
year={2024},
eprint={2411.09209},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.09209},
}我們要感謝 LivePortrait、Open Facevid2vid、InsightFace、X-Pose、DiffPoseTalk、Hallo、wav2vec 2.0、中文語音預訓練、Q-Align、Syncnet 和 VBench 儲存庫的貢獻者,感謝他們的開放研究和出色的工作。


