wikisearch
1.0.0
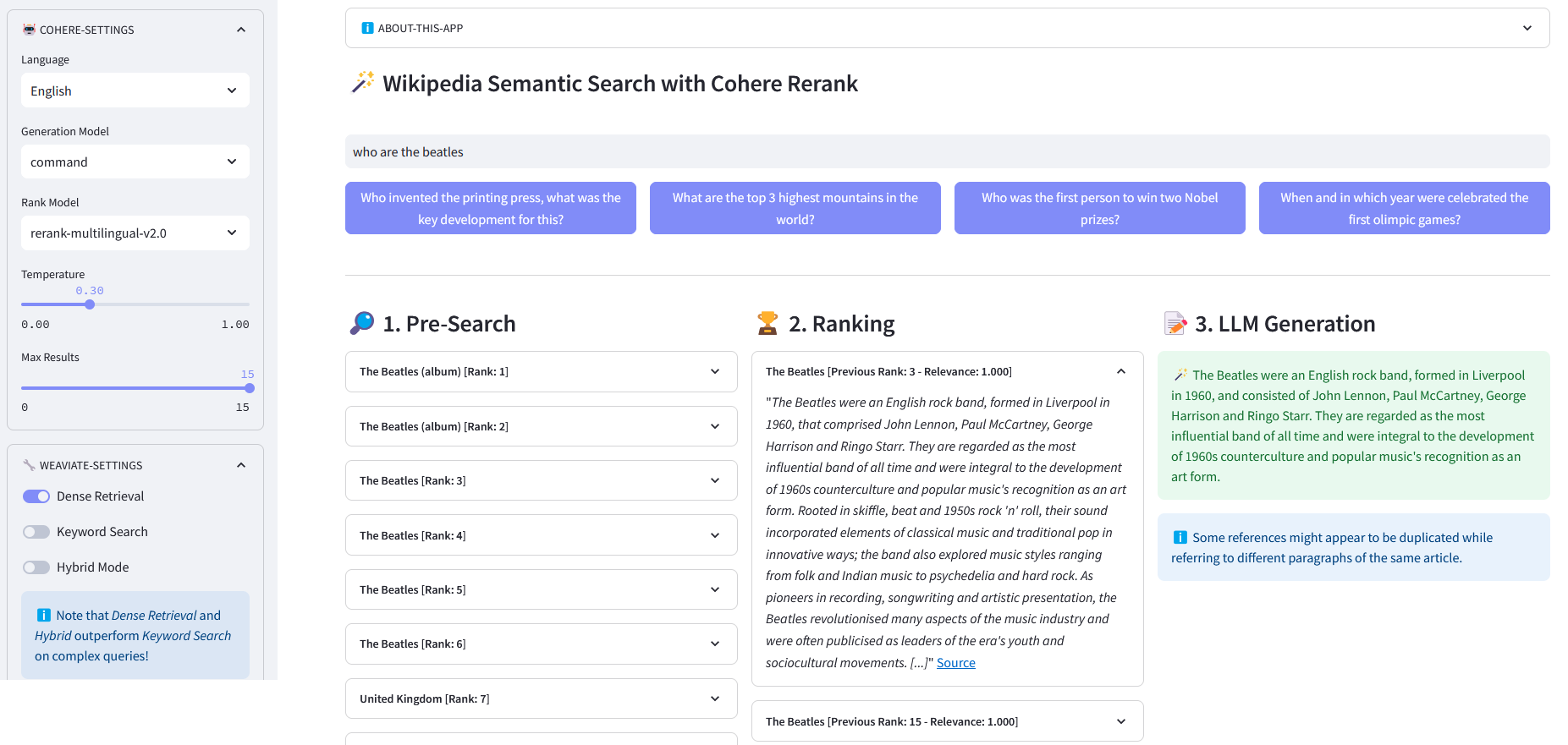
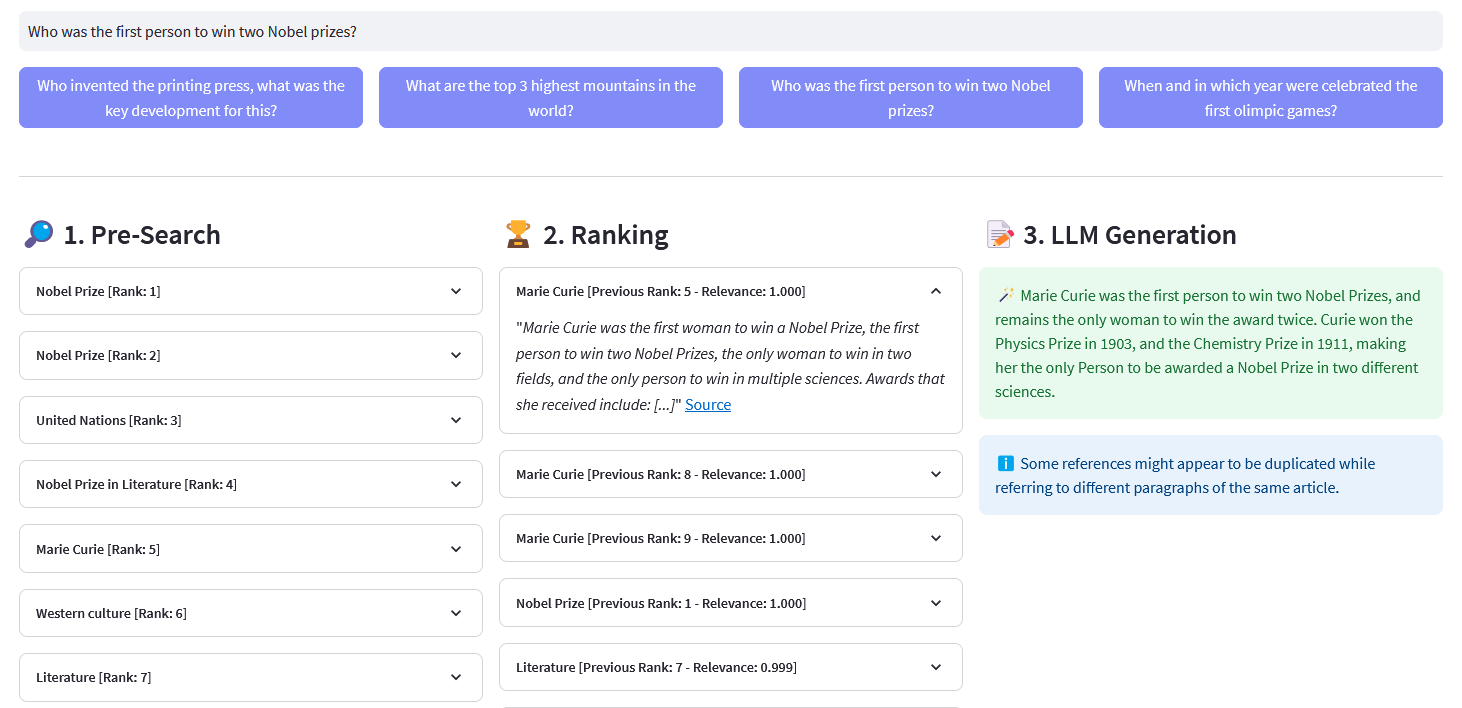
Streamlit 應用程序,用於對超過 1000 萬個由 Weaviate 嵌入向量化的維基百科文件進行多語言語義搜尋。該實作基於 Cohere 的部落格「使用 LLM 進行搜尋」及其相應的筆記本。它可以比較關鍵字搜尋、密集檢索和混合搜尋的效能來查詢維基百科資料集。它進一步演示如何使用 Cohere Rerank 來提高結果的準確性,並使用 Cohere Generation 根據所述排名結果提供回應。
語義搜尋是指在產生結果時考慮搜尋短語的意圖和上下文含義的搜尋演算法,而不是僅僅關注關鍵字匹配。它透過理解查詢背後的語義或含義來提供更準確和相關的結果。
嵌入是表示單字、句子、文件、圖像或音訊等資料的浮點數向量(列表)。所述數字表示捕獲資料的上下文、層次結構和相似性。它們可用於下游任務,例如分類、聚類、異常值檢測和語義搜尋。
向量資料庫(例如 Weaviate)是專門為優化嵌入的儲存和查詢功能而建構的。在實踐中,向量資料庫使用不同演算法的組合,這些演算法都參與近似最近鄰 (ANN) 搜尋。這些演算法透過雜湊、量化或基於圖的搜尋來優化搜尋。
預先搜尋:透過關鍵字配對、密集檢索或混合搜尋對維基百科嵌入進行預先搜尋:
關鍵字匹配:它會尋找屬性中包含搜尋字詞的物件。根據BM25F函數對結果進行評分:
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_bm25(self, query, lang='en', top_n=10) -> list:""" 執行關鍵字使用 Weaviate 中儲存的嵌入來搜尋(稀疏檢索): - query (str):搜尋查詢- lang(str,可選):文章的語言- top_n(int)。結果數。 "valueString": lang}response = (self.weaviate.query.get("文章", self.WIKIPEDIA_PROPERTIES)
.with_bm25(查詢=查詢)
.with_where(where_filter)
.with_limit(top_n)
。
)回傳回應["數據"]["取得"]["文章"]密集檢索:尋找與原始(非向量化)文字最相似的物件:
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_neartext(self, query, lang='en', top_n=10) -> list:""" 執行語意使用儲存在Weaviate 中的嵌入對Wikipedia 文章進行搜尋(密集檢索)。的熱門結果數量。
}where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("文章", self.WIKIPEDIA_PROPERTIES)
.with_near_text(nearText)
.with_where(where_filter)
.with_limit(top_n)
。
)回傳回應['數據']['獲取']['文章']混合搜尋:根據關鍵字 (bm25) 搜尋和向量搜尋結果的加權組合產生結果。
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_hybrid(self, query, lang='en', top_n=10) -> list:""" 執行混合使用Weaviate 中儲存的嵌入搜尋維基百科文章。數。 Equal","valueString": lang}response = (self.weaviate.query.get("文章", self.WIKIPEDIA_PROPERTIES)
.with_hybrid(查詢=查詢)
.with_where(where_filter)
.with_limit(top_n)
。
)回傳回應["數據"]["取得"]["文章"]ReRank :Cohere Rerank 透過為給定使用者查詢的每個預搜尋結果分配相關性分數來重新組織預搜尋。與基於嵌入的語義搜尋相比,它會產生更好的搜尋結果 - 特別是對於複雜和特定領域的查詢。
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def rerank(self, 查詢, 文件, top_n=10, model='rerank-english-v2.0') -> dict:""" 使用Cohere 的重新排名API 對回應清單進行重新排名。參數: - query (str):搜尋查詢。- Documents (list):要重新排名的文件清單。- top_n(int,可選) :數字返回的排名靠前的結果。 top_n=top_n,模型=模型)
來源:Cohere
答案產生:Cohere Generation 根據排名結果撰寫答案。
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_llm(self, context, query, temp=0.2, model="command", lang="english") -> list:prompt = f""" 使用下面提供的資訊回答最後的問題。/包括從上下文中提取的一些好奇或相關的事實。/以查詢的語言產生答案。如果您無法確定語言/ 如果問題的答案未包含在所提供的資訊中,則產生「答案不在上下文中」 --- 上下文資訊:{context} --- 問題:{query } """return self.cohere.generate(prompt=prompt,num_ Generations =1,max_tokens=1000,溫度=溫度,model=model,
)克隆儲存庫:
[email protected]:dcarpintero/wikisearch.git
創建並啟動虛擬環境:
Windows: py -m venv .venv .venvscriptsactivate macOS/Linux python3 -m venv .venv source .venv/bin/activate
安裝依賴項:
pip install -r requirements.txt
啟動網路應用程式
streamlit run ./app.py
示範 Web 應用程式部署到 Streamlit Cloud,可在 https://wikisearch.streamlit.app/ 取得
連貫重排序
流光雲
嵌入檔案:數以百萬計的多種語言的維基百科文章嵌入
使用法學碩士進行密集檢索和重新排名搜索
向量資料庫
維維特向量搜尋
維維特 BM25 搜索
Weaviate 混合搜尋


