EasyDetect
1.0.0

易於使用的 MLLM 多模態幻覺偵測框架
致謝 • 基準測試 • 示範 • 概述 • ModelZoo • 安裝 • 快速入門 • 引用
致謝
概述
統一多模態幻覺
資料集:MHalluBench 統計
框架:UniHD 插圖
模型動物園
安裝
⏩快速入門
引文
2024-05-17 論文Unified Hallucination Inspection for Multimodal Large Language Models被ACL 2024主會議接收。
2024-04-21 我們用我們自己訓練的模型取代了演示中的所有基礎模型,顯著減少了推理時間。
2024-04-21 我們發布了開源幻覺檢測模型HalDet-LLAVA,可以在huggingface、modelscope和wisemodel下載。
2024-02-10 我們發布了 EasyDetect 演示。
2024-02-05 我們發布了論文:“Unified Hallucination Inspection for Multimodal Large Language Models”,帶有新的基準 MHaluBench!我們期待有關此主題的任何評論或討論:)
2023-10-20 EasyDetect專案已啟動並正在開發中。
該計畫的部分實施得到了相關幻覺工具包的協助和啟發,包括 FactTool、Woodpecker 等。該存儲庫還受益於 mPLUG-Owl、MiniGPT-4、LLaVA、GroundingDINO 和 MAERec 的公共專案。我們遵循相同的開源許可,並感謝他們對社群的貢獻。
EasyDetect 是一個系統包,在您的研究實驗中被提議作為多模態大型語言模型(MLLM)(如 GPT-4V、Gemini、LlaVA)的易於使用的幻覺檢測框架。
統一偵測的先決條件是對 MLLM 內幻覺的主要類別進行一致分類。我們的論文從統一的角度粗略地審視了以下幻覺分類法:


圖 1:統一的多模態幻覺檢測旨在識別和檢測物體、屬性和場景文本等各個層面的模態衝突幻覺,以及圖像到文本和文本到圖像中的事實衝突幻覺一代。
模態衝突的幻覺。 MLLM 有時會產生與其他模式的輸入衝突的輸出,從而導致諸如不正確的物件、屬性或場景文字等問題。上圖 (a) 中的範例包括 MLLM 不準確地描述運動員的製服,展示了由於 MLLM 實現細粒度文字影像對齊的能力有限而導致的屬性級衝突。
與事實相違背的幻覺。 MLLM 的輸出可能與既定的事實知識相矛盾。圖像到文字模型可以透過合併不相關的事實來產生偏離實際內容的敘述,而文字到圖像模型可能產生無法反映文字提示中包含的事實知識的視覺效果。這些差異凸顯了 MLLM 為保持事實一致性而付出的努力,代表了該領域的重大挑戰。
多模態幻覺的統一檢測需要檢查每個影像-文字對a={v, x} ,其中v表示提供給 MLLM 的視覺輸入或由其合成的視覺輸出。相應地, x表示 MLLM 基於v產生的文字回應或用於合成v文字使用者查詢。在此任務中,每個x可能包含多個聲明,表示為a確定它是“幻覺”還是“非幻覺”,並根據所提供的幻覺定義為他們的判斷提供依據。 LLM 的文字幻覺偵測表示此設定中的一個子情況,其中v為空。
為了推進這一研究軌跡,我們引入了元評估基準 MHaluBench,它涵蓋了從圖像到文字和文字到圖像生成的內容,旨在嚴格評估多模態幻覺偵測器的進展。下圖提供了有關 MHaluBench 的更多統計詳細資料。
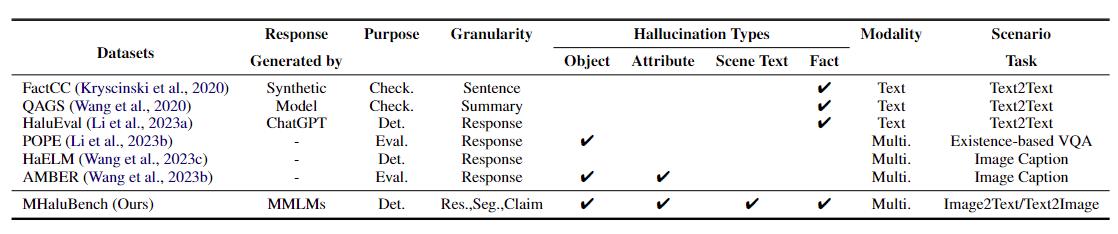
表 1:現有事實查核或幻覺評估的基準比較。 “查看。”表示驗證事實一致性,「Eval」。表示評估不同法學碩士產生的幻覺,其響應基於被測的不同法學碩士,而“Det”。體現了對探測器辨識幻覺能力的評估。
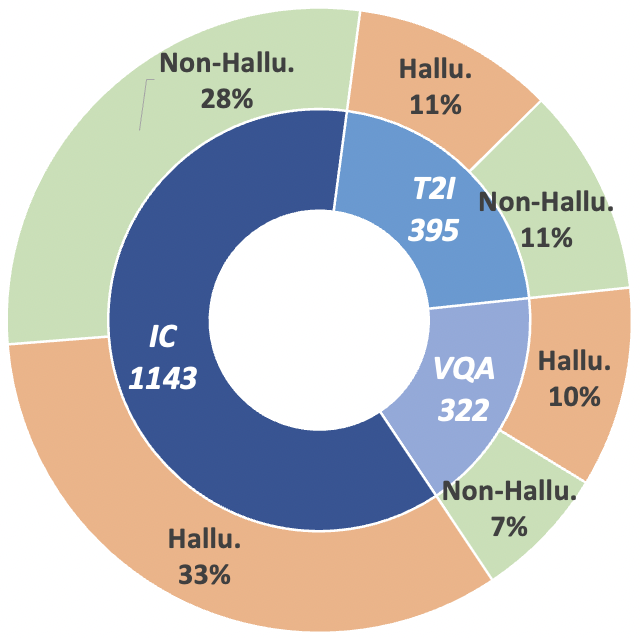
圖2: MHaluBench的理賠等級資料統計。 “IC”表示圖像字幕,“T2I”表示文字到圖像合成。
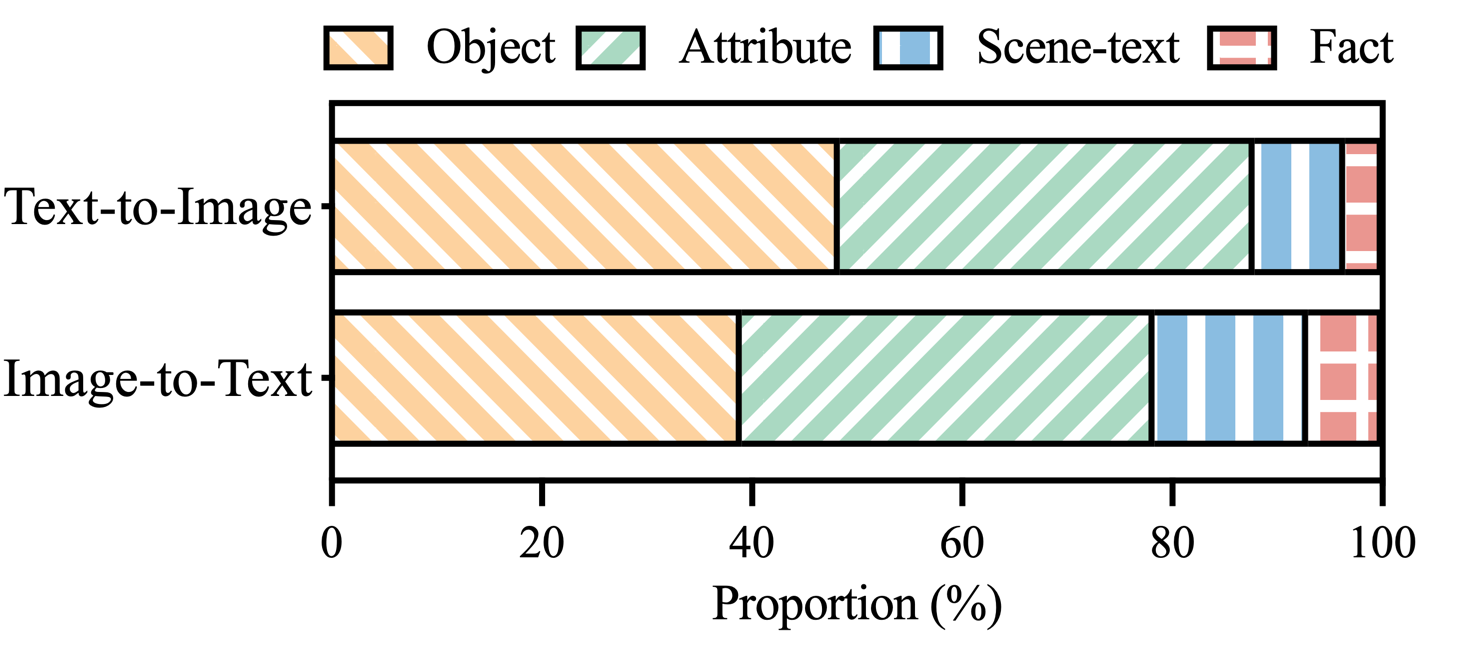
圖 3: MHaluBench 幻覺標籤聲明中幻覺類別的分佈。
為了解決幻覺檢測中的關鍵挑戰,我們在圖 4 中引入了一個統一的框架,該框架系統地解決了圖像到文字和文字到圖像任務的多模態幻覺識別。我們的框架利用各種工具的特定領域優勢來有效收集多模式證據來確認幻覺。
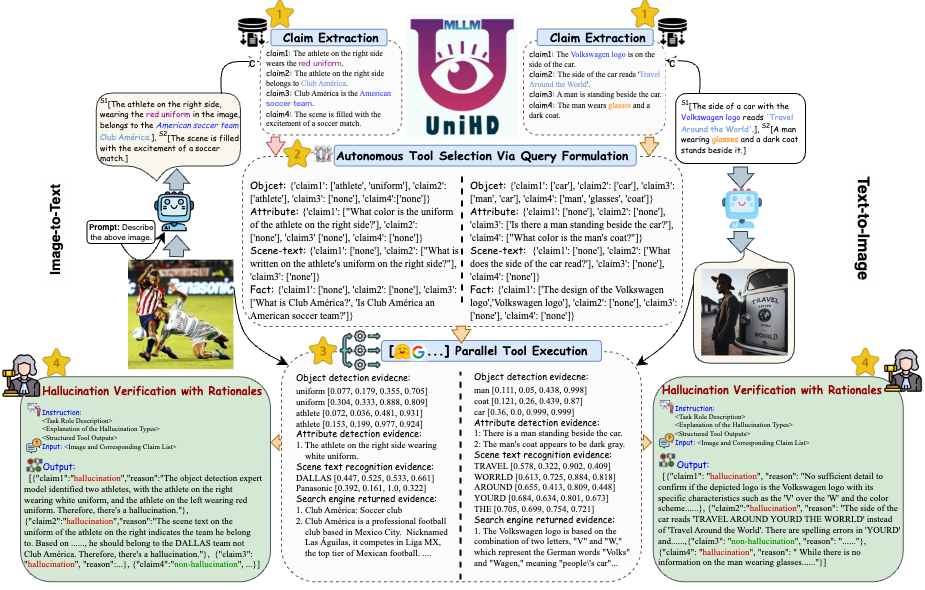
圖4: UniHD用於統一多模態幻覺偵測的具體圖示。
您可以在三個平台上下載 HalDet-LLaVA 的兩個版本:7b 和 13b:HuggingFace、ModelScope 和 WiseModel。
| 抱臉 | 模型範圍 | 智慧模型 |
|---|---|---|
| 哈爾德拉瓦-7b | 哈爾德拉瓦-7b | 哈爾德拉瓦-7b |
| 哈爾德特拉瓦-13b | 哈爾德特拉瓦-13b | 哈爾德特拉瓦-13b |
驗證資料集上的聲明層級結果
Self-Check(GPT-4V) 表示使用 GPT-4V 0 或 2 例
UniHD(GPT-4V/GPT-4o) 表示使用帶有 2-shot 和工具資訊的 GPT-4V/GPT-4o
HalDet (LLAVA) 意味著使用在我們的訓練資料集上訓練的 LLAVA-v1.5
| 任務類型 | 模型 | 加速器 | 平均預測值 | 平均召回率 | 麥克F1 |
| 圖像到文字 | 自我檢測0shot (GPV-4V) | 75.09 | 74.94 | 75.19 | 74.97 |
| 自我檢測2shot (GPV-4V) | 79.25 | 79.02 | 79.16 | 79.08 | |
| 哈爾德特 (LLAVA-7b) | 75.02 | 75.05 | 74.18 | 74.38 | |
| 哈爾德特 (LLAVA-13b) | 78.16 | 78.18 | 77.48 | 77.69 | |
| UniHD(GPT-4V) | 81.91 | 81.81 | 81.52 | 81.63 | |
| UniHD(GPT-4o) | 86.08 | 85.89 | 86.07 | 85.96 | |
| 文字到圖像 | 自我檢測0shot (GPV-4V) | 76.20 | 79.31 | 75.99 | 75.45 |
| 自我檢測2shot (GPV-4V) | 80.76 | 81.16 | 80.69 | 80.67 | |
| 哈爾德特 (LLAVA-7b) | 67.35 | 69.31 | 67.50 | 66.62 | |
| 哈爾德特 (LLAVA-13b) | 74.74 | 76.68 | 74.88 | 74.34 | |
| UniHD(GPT-4V) | 85.82 | 85.83 | 85.83 | 85.82 | |
| UniHD(GPT-4o) | 89.29 | 89.28 | 89.28 | 89.28 |
要查看有關 HalDet-LLaVA 和訓練資料集的更多詳細信息,請參閱自述文件。
本地開發安裝:
git clone https://github.com/zjunlp/EasyDetect.git cd EasyDetect pip install -r requirements.txt
工具安裝(GroundingDINO 和 MAERec):
# install GroundingDINO git clone https://github.com/IDEA-Research/GroundingDINO.git cp -r GroundingDINO pipeline/GroundingDINO cd pipeline/GroundingDINO/ pip install -e . cd .. # install MAERec git clone https://github.com/Mountchicken/Union14M.git cp -r Union14M/mmocr-dev-1.x pipeline/mmocr cd pipeline/mmocr/ pip install -U openmim mim install mmengine mim install mmcv mim install mmdet pip install timm pip install -r requirements/albu.txt pip install -r requirements.txt pip install -v -e . cd .. mkdir weights cd weights wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth wget https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015_20221101_124139-4ecb39ac.pth -O dbnetpp.pth wget https://github.com/Mountchicken/Union14M/releases/download/Checkpoint/maerec_b_union14m.pth -O maerec_b.pth cd ..
我們提供範例程式碼,供使用者快速上手 EasyDetect。
使用者可以輕鬆地在yaml檔案中配置EasyDetect的參數,或快速使用我們提供的設定檔中的預設參數。設定檔的路徑為 EasyDetect/pipeline/config/config.yaml
openai: api_key: 輸入您的 openai api 金鑰
base_url:輸入base_url,預設為None
溫度:0.2
最大令牌數:1024工具:
偵測:groundingdino_config:GroundingDINO_SwinT_OGC.pymodel_path:groundingdino_swint_ogc.pthdevice的路徑:cuda:0BOX_TRESHOLD:0.35TEXT_TRESHOLD:0.25AREA_THRESHOLD:0.001OLD:0.001
ocr:dbnetpp_config:dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015 的路徑。 files 的路徑儲存臨時影像BOX_TRESHOLD :0.2TEXT_TRESHOLD:0.25
google_serper:serper_api_key: 輸入您的 serper api 金鑰nippet_cnt: 10prompts: Claim_generate: pipeline/prompts/claim_generate.yaml
query_generate:管道/提示/query_generate.yaml
驗證:管道/提示/verify.yaml範例程式碼
from pipeline.run_pipeline import *pipeline = Pipeline()text = "圖片中的咖啡館名為「Hauptbahnhof」"image_path = "./examples/058214af21a03013.jpg"type = "image-to-text"response, Claim_list .run(文字=文本,圖像路徑=圖像路徑,類型=類型)列印(響應)列印(聲明列表)
如果您在工作中使用 EasyDetect,請引用我們的儲存庫。
@article{chen23factchd,作者={Xiang Chen and Duanzheng Song and Honghao Gui and Chengxi Wang and Ningyu Zhang and Jiang Yong and Fei Huang and Chengfei Lv and Dan Zhang and Huajun Chen},標題={FactCHD:事實衝突幻覺檢測基準測試},期刊= {CoRR},卷= {abs/2310.12086},年份= {2023},url = {https://doi.org/10.48550/arXiv.2310.12086},doi = {10.48550/ARXIV.2310. eprinttype = {arXiv},eprint = {2310.12086},biburl = {https://dblp.org/rec/journals/corr/abs-2310-12086.bib},bibsource = {dblp 電腦科學參考書目,https:/ / dblp.org}}@inproceedings{chen-etal-2024-unified-hallucination,title =“多模態大語言模型的統一幻覺檢測”,作者=“Chen,Xiang和Wang,Chenxi和Xue,Yida和Zhang ,Ningyu和楊,曉燕和李,強和沈,岳和梁,雷和顧,金杰和陳華軍”,編輯=“庫倫偉和馬丁斯,安德烈和斯里庫馬爾,維韋克”,書名=“第62屆會議論文集”計算語言學協會年會(第一卷:長論文)",月份= 八月,年份= "2024",地址= "泰國曼谷",publisher = "計算語言學會",url = "https:// /aclanthology.org/2024.acl-long.178",pages = "3235--3252",
}我們將提供長期維護來修復錯誤、解決問題並滿足新的要求。因此,如果您有任何問題,請向我們提出問題。


