xTuring
0.1.8


xTuring提供對開源 LLM 的快速、高效且簡單的微調,例如 Mistral、LLaMA、GPT-J 等。透過提供易於使用的介面來根據您自己的資料和應用程式微調 LLM,xTuring 讓建置、修改和控制 LLM 變得簡單。整個過程可以在您的電腦內部或您的私有雲中完成,確保資料隱私和安全。
借助xTuring您可以,
pip install xturing from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the dataset
instruction_dataset = InstructionDataset ( "./examples/models/llama/alpaca_data" )
# Initialize the model
model = BaseModel . create ( "llama_lora" )
# Finetune the model
model . finetune ( dataset = instruction_dataset )
# Perform inference
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( "Generated output by the model: {}" . format ( output ))您可以在此處找到資料資料夾。
我們很高興地宣布xTuring庫的最新增強功能:
LLaMA 2整合- 您可以在不同的配置中使用和微調LLaMA 2模型:現成的、現成的 INT8 精度、 LoRA 微調、 LoRA INT8 精度微調和LoRA 微調使用GenericModel包裝器以 INT4 精度進行調整和/或您可以使用xturing.models中的Llama2類別來測試和微調模型。 from xturing . models import Llama2
model = Llama2 ()
## or
from xturing . models import BaseModel
model = BaseModel . create ( 'llama2' )Evaluation - 現在您可以評估任何資料集上的任何Causal Language Model 。目前支援的指標是perplexity 。 # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model
model = BaseModel . create ( 'gpt2' )
# Run the Evaluation of the model on the dataset
result = model . evaluate ( dataset )
# Print the result
print ( f"Perplexity of the evalution: { result } " )INT4 Precision - 您現在可以使用GenericLoraKbitModel來使用和微調具有INT4 Precision的任何 LLM。 # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Run the fine-tuning
model . finetune ( dataset ) # Make the necessary imports
from xturing . models import BaseModel
# Initializes the model: quantize the model with weight-only algorithms
# and replace the linear with Itrex's qbits_linear kernel
model = BaseModel . create ( "llama2_int8" )
# Once the model has been quantized, do inferences directly
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( output ) # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Generate outputs on desired prompts
outputs = model . generate ( dataset = dataset , batch_size = 10 )建議探索 Llama LoRA INT4 工作範例以了解其應用。
若要獲得更深入的了解,請考慮檢查儲存庫中提供的 GenericModel 工作範例。

$ xturing chat -m " <path-to-model-folder> "
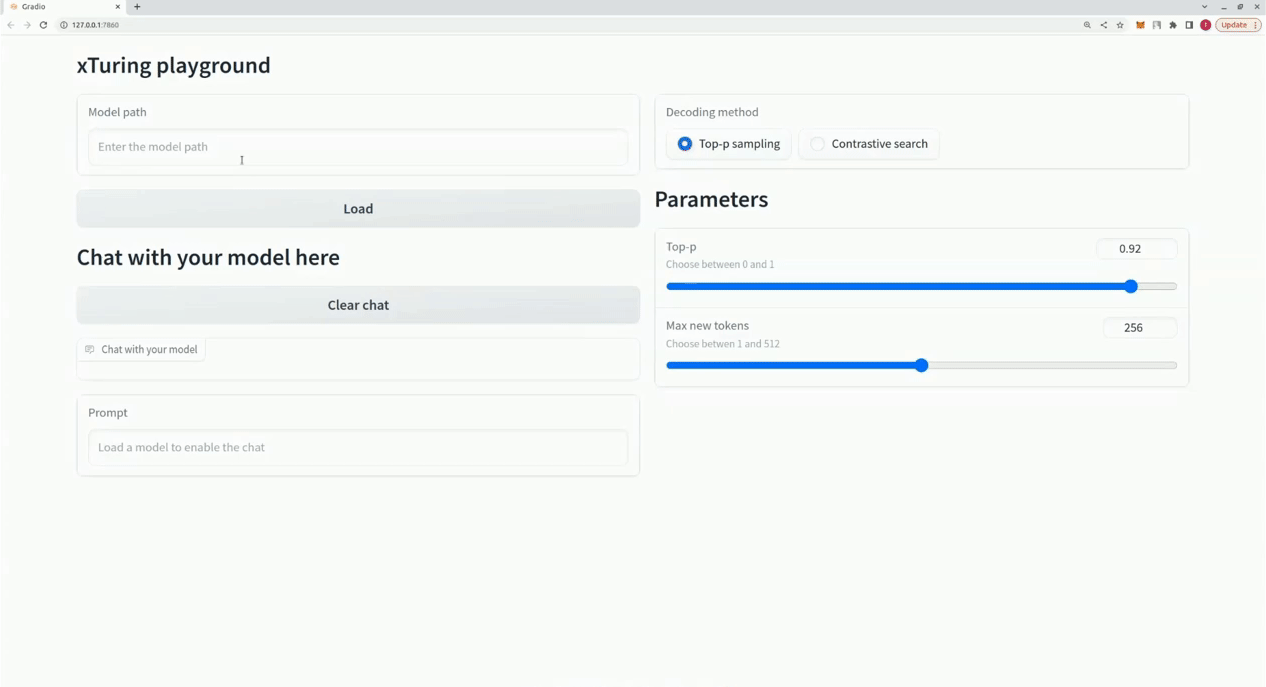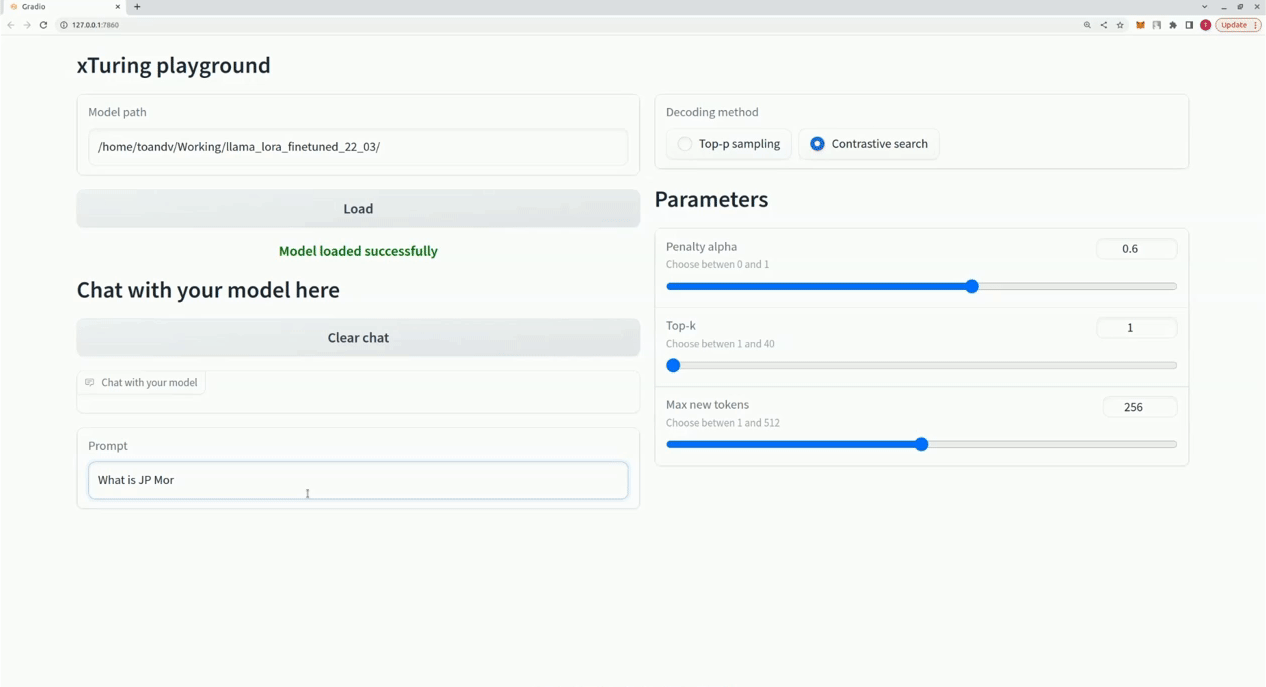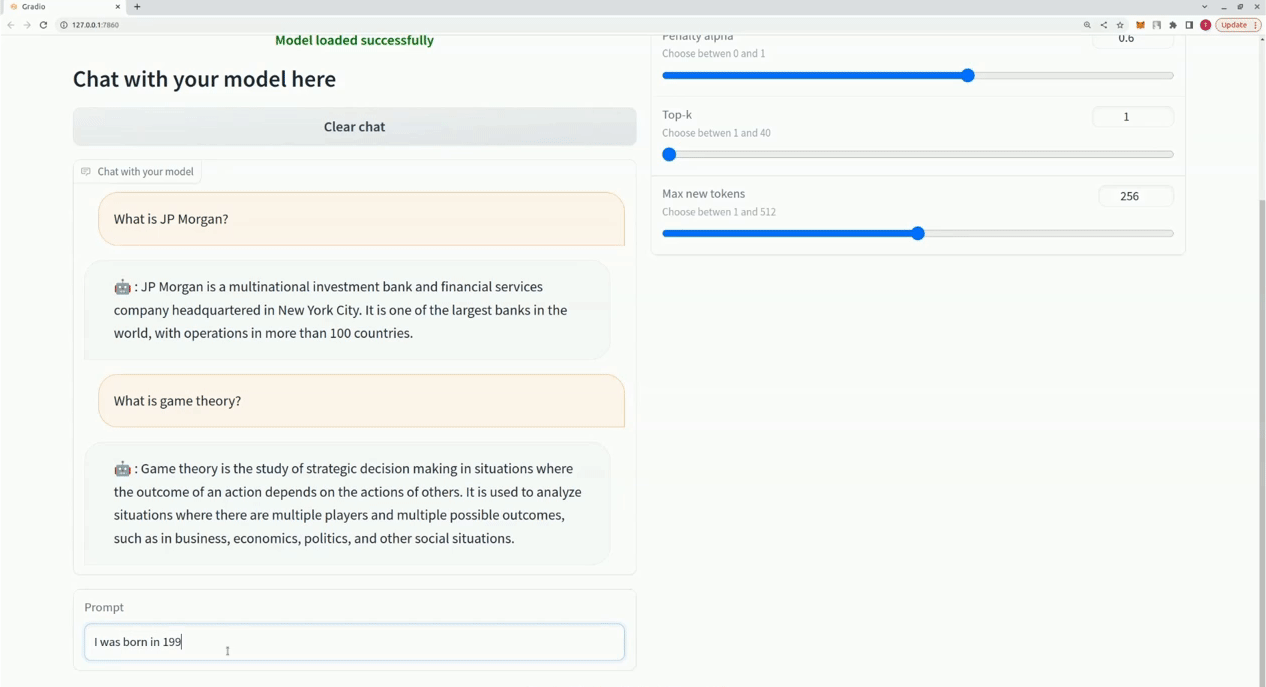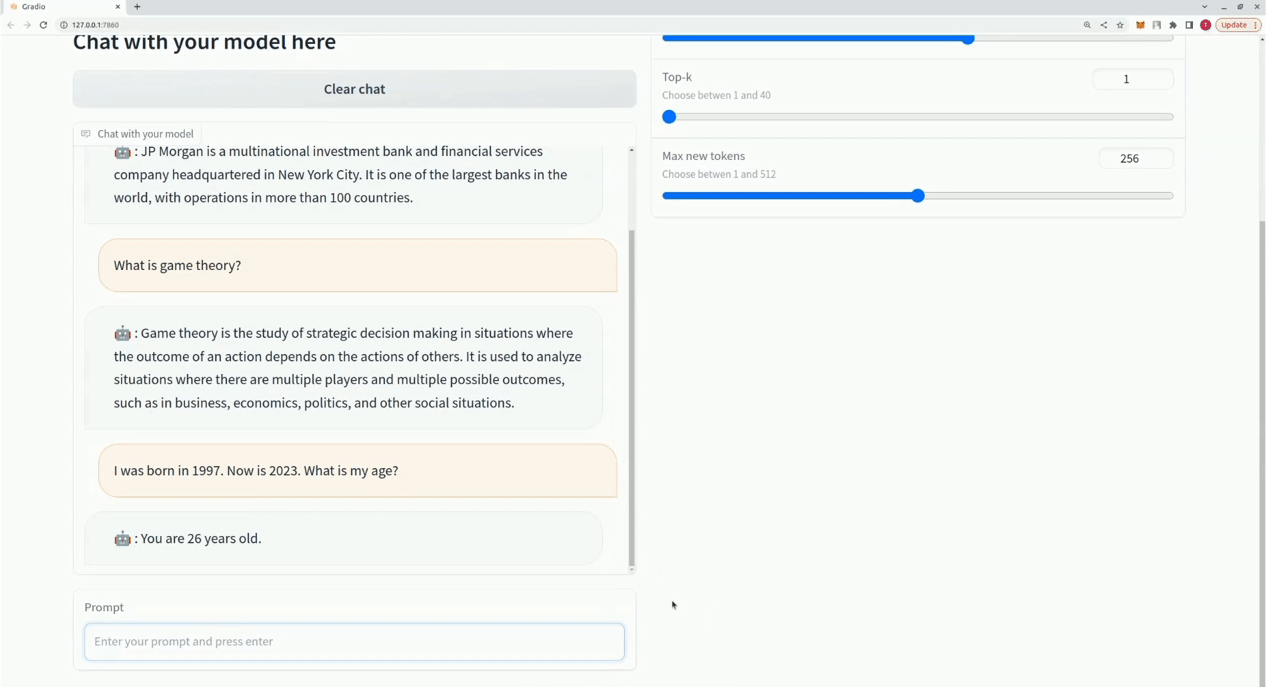
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
from xturing . ui import Playground
dataset = InstructionDataset ( "./alpaca_data" )
model = BaseModel . create ( "<model_name>" )
model . finetune ( dataset = dataset )
model . save ( "llama_lora_finetuned" )
Playground (). launch () ## launches localhost UI 以下是不同微調技術在 LLaMA 7B 模型上的效能比較。我們使用 Alpaca 資料集進行微調。該資料集包含 52K 指令。
硬體:
4 個 A100 40GB GPU、335GB CPU 內存
微調參數:
{
'maximum sequence length' : 512 ,
'batch size' : 1 ,
}| 拉馬-7B | DeepSpeed + CPU 卸載 | LoRA + DeepSpeed | LoRA + DeepSpeed + CPU 卸載 |
|---|---|---|---|
| 圖形處理器 | 33.5GB | 23.7GB | 21.9GB |
| 中央處理器 | 190GB | 10.2GB | 14.9GB |
| 時間/紀元 | 21小時 | 20分鐘 | 20分鐘 |
透過在其他 GPU 上提交您的效能結果來為此做出貢獻,方法是在您的硬體規格、記憶體消耗和每個週期的時間方面提出問題。
我們已經微調了一些模型,您可以將其用作基礎或開始使用。以下是加載它們的方法:
from xturing . models import BaseModel
model = BaseModel . load ( "x/distilgpt2_lora_finetuned_alpaca" )| 模型 | 數據集 | 小路 |
|---|---|---|
| DistilGPT-2 LoRA | 羊駝毛 | x/distilgpt2_lora_finetuned_alpaca |
| 駱駝洛拉 | 羊駝毛 | x/llama_lora_finetuned_alpaca |
以下是xTuring的BaseModel類別支援的所有模型及其對應的載入鍵的清單。
| 模型 | 鑰匙 |
|---|---|
| 盛開 | 盛開 |
| 大腦 | 大腦 |
| 蒸餾GPT-2 | 蒸餾GPT2 |
| 獵鷹7B | 鷸 |
| 卡拉狄加 | 卡拉狄加 |
| GPT-J | 格普特吉 |
| GPT-2 | 總蛋白2 |
| 駱駝 | 駱駝 |
| 拉瑪2 | 駱駝2 |
| OPT-1.3B | 選擇 |
上述是法學碩士的基本變體。以下是取得LoRA 、 INT8 、 INT8 + LoRA和INT4 + LoRA版本的範本。
| 版本 | 範本 |
|---|---|
| 洛拉 | <模型密鑰>_lora |
| INT8 | <模型鍵>_int8 |
| INT8+LoRA | <模型金鑰>_lora_int8 |
** 為了載入任何模型的INT4+LoRA版本,您需要使用xturing.models中的GenericLoraKbitModel類別。下面是如何使用它:
model = GenericLoraKbitModel ( '<model_path>' ) model_path可以替換為您的本機目錄或任何 HuggingFace 庫模型,例如facebook/opt-1.3b 。
LLaMA 、 GPT-J 、 GPT-2 、 OPT 、 Cerebras-GPT 、 Galactica和Bloom模型Generic model包裝器Falcon-7B型號如果您有任何疑問,可以在此儲存庫上建立問題。
您也可以加入我們的 Discord 伺服器並在#xturing頻道中開始討論。
該項目根據 Apache License 2.0 獲得許可 - 有關詳細信息,請參閱許可證文件。
作為快速發展領域的開源項目,我們歡迎各種貢獻,包括新功能和更好的文件。請閱讀我們的貢獻指南,以了解如何參與。


