QuillGPT
1.0.0

QuillGPT 是 GPT 解碼器區塊的實現,基於 Vaswani 等人的《Attention is All You Need》論文中的架構。等人。在 PyTorch 中實作。此外,該儲存庫還包含兩個預訓練模型——Shakespearean GPT 和 Harpoon GPT——及其訓練過的權重。為了方便實驗和部署,提供了 Streamlit Playground 來互動式探索這些模型,並使用 Docker 容器化實作 FastAPI 微服務以實現可擴展部署。您還將找到用於訓練新 GPT 模型並對其進行推理的 Python 腳本,以及展示經過訓練的模型的筆記本。為了促進文字編碼和解碼,實作了一個簡單的分詞器。探索 QuillGPT 以利用這些工具並增強您的自然語言處理專案!
此儲存庫中包含兩個預先訓練的模型和權重。
| 特徵 | 莎士比亞GPT | 魚叉GPT |
|---|---|---|
| 參數 | 10.7M | 226米 |
| 重量 | 重量 | 重量 |
| 型號配置 | 配置 | 配置 |
| 訓練資料 | 莎士比亞戲劇中的文字 (input.txt) | 書中的隨機文字 (corpus.txt) |
| 嵌入型 | 字元嵌入 | 字元嵌入 |
| 培訓筆記本 | 筆記本 | 筆記本 |
| 硬體 | 英偉達T4 | 英偉達 A100 |
| 訓練和驗證損失 | 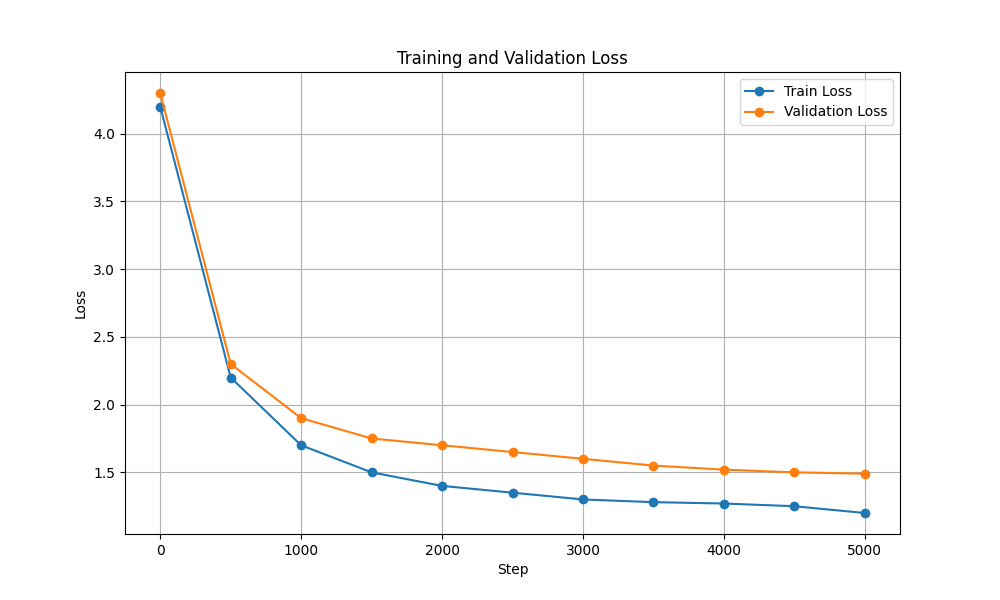 | 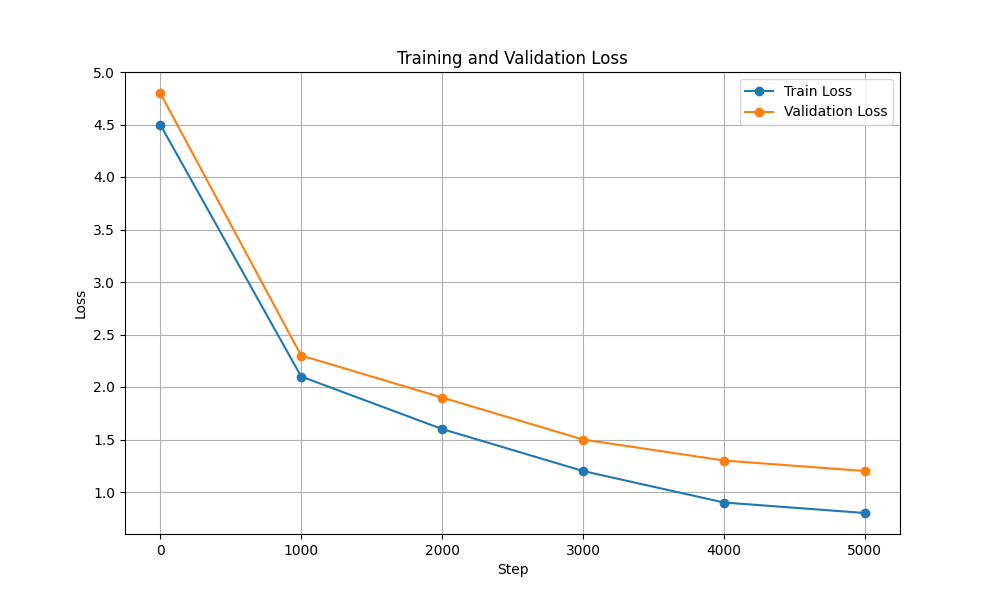 |
若要執行訓練和推理腳本,請執行以下步驟:
git clone https://github.com/NotShrirang/GPT-From-Scratch.git
cd GPT-From-Scratchpip install -r requirements.txt在繼續之前,請確保從此處下載 Harpoon GPT 的權重!
它託管在 Streamlit 雲端服務上。您可以透過此處的連結訪問它。
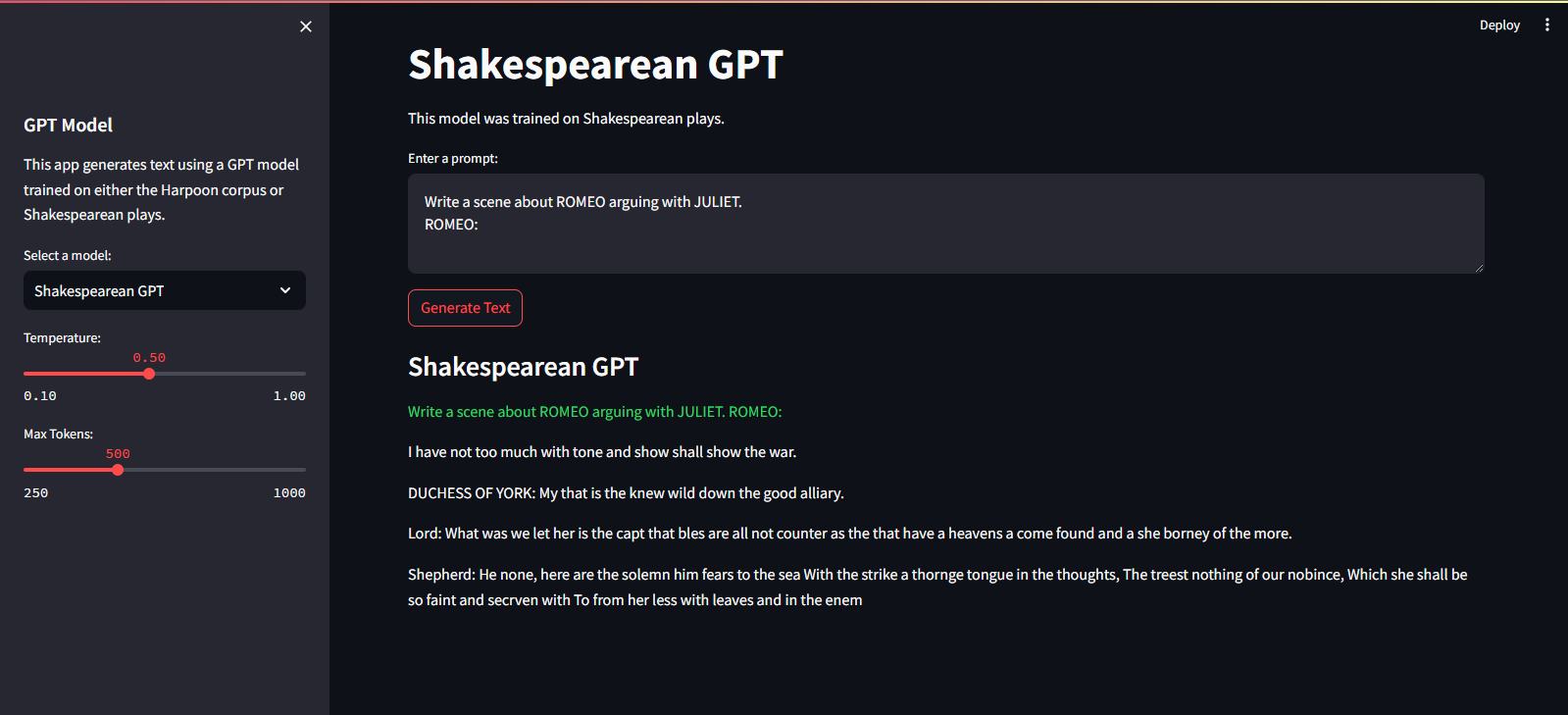
streamlit run app.pypython main.py./run.sh start-dev./run.sh stop-dev要訓練 GPT 模型,請按照以下步驟操作:
準備數據。將整個文字資料放入單一 .txt 檔案中並儲存。
編寫變壓器的配置並儲存檔案。
例如: json { "data_path": "data/corpus.txt", "vocab_size": 135, "batch_size": 32, "block_size": 256, "max_iters": 3000, "eval_interval": 300, "learning_rate": 3e-5, "eval_iters": 50, "n_embd": 1024, "n_head": 12, "n_layer": 18, "dropout": 0.3, }
使用腳本scripts/train_gpt.py訓練模型
python scripts/train_gpt.py
--config_path config/config.json
--data_path data/corpus.txt
--output_dir trained_models (您可以根據您的要求更改config_path 、 data_path和output_dir 。)
output_dir中。訓練完成後,您可以使用訓練好的GPT模型進行文字生成。以下是使用經過訓練的模型進行推理的範例:
python scripts/inference_gpt.py
--config_path config/shakespearean_config.json
--weights_path weights/GPT_model_char.pt
--max_length 500
--prompt " Once upon a time " 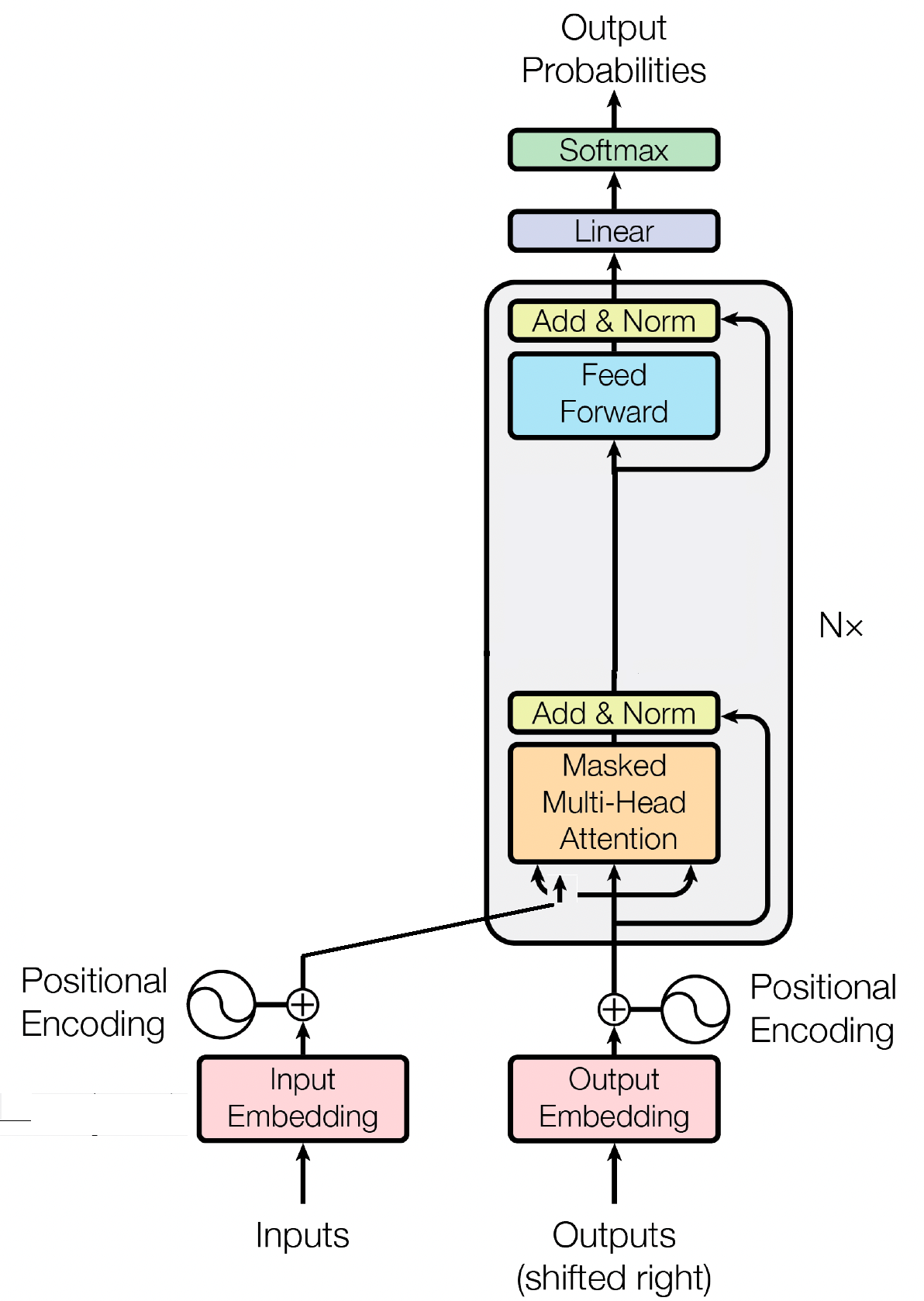
解碼器區塊是 GPT(產生預訓練變換器)模型的重要組成部分,它是 GPT 實際生成文字的地方。它利用自註意力機制來處理輸入序列並產生一致的輸出。每個解碼器區塊由多個層組成,包括自註意力層、前饋神經網路和層歸一化層。自註意力層允許模型權衡序列中不同單字的重要性,捕捉上下文和依賴關係,無論它們的位置如何。這使得 GPT 模型能夠產生上下文相關的文本。
輸入嵌入透過將輸入標記轉換為有意義的數字表示,在 GPT 等基於轉換器的模型中發揮著至關重要的作用。這些嵌入作為模型的初始輸入,捕獲有關序列中單字的語義資訊。這個過程涉及將輸入序列中的每個標記映射到高維向量空間,其中相似的標記被放置得更靠近。這使得模型能夠理解不同單字之間的關係並有效地從輸入資料中學習。然後,輸入嵌入被輸入到模型的後續層中以進行進一步處理。
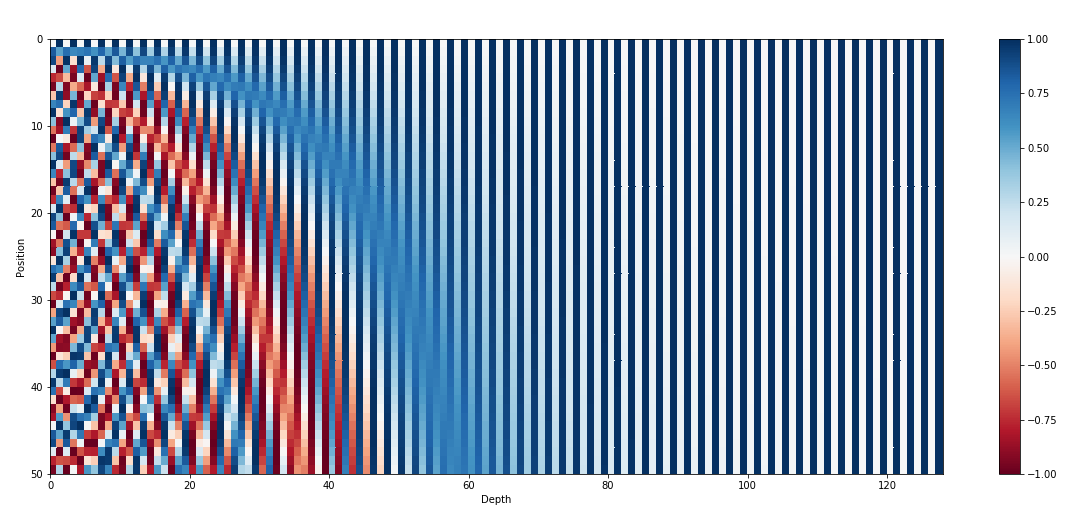
除了輸入嵌入之外,位置嵌入是 GPT 等 Transformer 架構的另一個重要組成部分。由於轉換器缺乏有關序列中標記順序的固有信息,因此引入位置嵌入來為模型提供位置資訊。這些嵌入對序列中每個標記的位置進行編碼,允許模型根據標記的位置來區分標記。透過合併位置嵌入,像 GPT 這樣的轉換器可以有效地捕捉資料的順序性質並產生連貫的輸出,從而保持生成文字中單字的正確順序。

自註意力是 GPT 等基於 Transformer 的模型中的一種基本機制,它透過為序列中的不同單字分配重要性分數來運作。這個過程涉及三個關鍵步驟:計算注意力分數,應用softmax來獲得注意力權重,最後將這些權重與輸入嵌入結合以產生上下文資訊表示。從本質上講,自註意力使模型能夠更多地關注相關單詞,同時弱化不太重要的單詞,從而促進有效學習輸入資料中的上下文依賴關係。這種機制對於捕捉遠端依賴關係和上下文細微差別至關重要,使 Transformer 模型能夠產生長文本序列。
麻省理工學院 © Shrirang Mahajan
請隨意提交拉取請求、建立問題或傳播訊息!
只需給這個存儲庫加註星標即可支持我!


