SDV
v1.17.2 - 2024-11-18
此儲存庫是 DataCebo 的綜合資料倉儲專案的一部分。



Synthetic Data Vault (SDV) 是一個 Python 函式庫,旨在成為您建立表格合成資料的一站式商店。 SDV 使用各種機器學習演算法從真實數據中學習模式並在合成數據中模擬它們。
?使用機器學習創建合成數據。 SDV 提供多種模型,從經典統計方法(GaussianCopula)到深度學習方法(CTGAN)。為單一表、多個連接表或順序表產生資料。
評估和可視化數據。根據各種措施將合成數據與真實數據進行比較。診斷問題並產生品質報告以獲得更多見解。
預處理、匿名化和定義約束。控制資料處理以提高合成資料的質量,選擇不同類型的匿名化並以邏輯約束的形式定義業務規則。
| 重要連結 | |
|---|---|
 教學 教學 | 獲得一些 SDV 的實務經驗。啟動教程筆記本並自行運行程式碼。 |
| 文件 | 透過使用者指南和 API 參考了解如何使用 SDV 庫。 |
| ?部落格 | 取得更多有關使用 SDV、部署模型和我們的合成資料社群的見解。 |
 社群 社群 | 加入我們的 Slack 工作區以獲取公告和討論。 |
| 網站 | 請造訪 SDV 網站,以了解有關該項目的更多資訊。 |
SDV 根據商業源許可證公開提供。使用 pip 或 conda 安裝 SDV。我們建議使用虛擬環境以避免與設備上的其他軟體發生衝突。
pip install sdvconda install -c pytorch -c conda-forge sdv載入演示資料集以開始使用。該資料集是一個描述入住虛構酒店的客人的表。
from sdv . datasets . demo import download_demo
real_data , metadata = download_demo (
modality = 'single_table' ,
dataset_name = 'fake_hotel_guests' )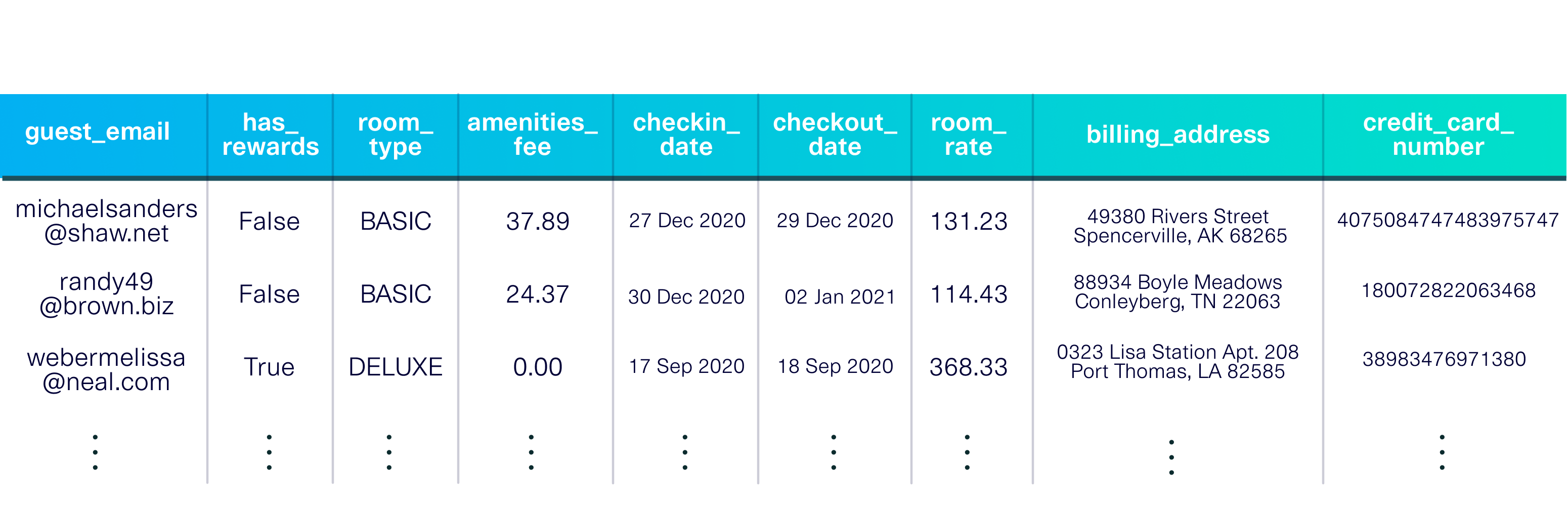
此示範還包括元資料、資料集的描述,包括每列中的資料類型和主鍵 ( guest_email )。
接下來,我們可以建立一個SDV 合成器,這是一個可用來建立合成資料的物件。它從真實數據中學習模式並複製它們以產生合成數據。讓我們使用 GaussianCopulaSynthesizer。
from sdv . single_table import GaussianCopulaSynthesizer
synthesizer = GaussianCopulaSynthesizer ( metadata )
synthesizer . fit ( data = real_data )現在合成器已準備好建立合成資料!
synthetic_data = synthesizer . sample ( num_rows = 500 )合成數據將具有以下屬性:
SDV 函式庫可讓您透過將合成資料與真實資料進行比較來評估合成資料。首先產生品質報告。
from sdv . evaluation . single_table import evaluate_quality
quality_report = evaluate_quality (
real_data ,
synthetic_data ,
metadata ) Generating report ...
(1/2) Evaluating Column Shapes: |████████████████| 9/9 [00:00<00:00, 1133.09it/s]|
Column Shapes Score: 89.11%
(2/2) Evaluating Column Pair Trends: |██████████████████████████████████████████| 36/36 [00:00<00:00, 502.88it/s]|
Column Pair Trends Score: 88.3%
Overall Score (Average): 88.7%
該物件計算 0 到 100% 範圍內的總體品質得分(100 為最佳)以及詳細的細分。要獲得更多見解,您還可以視覺化合成資料與真實資料。
from sdv . evaluation . single_table import get_column_plot
fig = get_column_plot (
real_data = real_data ,
synthetic_data = synthetic_data ,
column_name = 'amenities_fee' ,
metadata = metadata
)
fig . show ()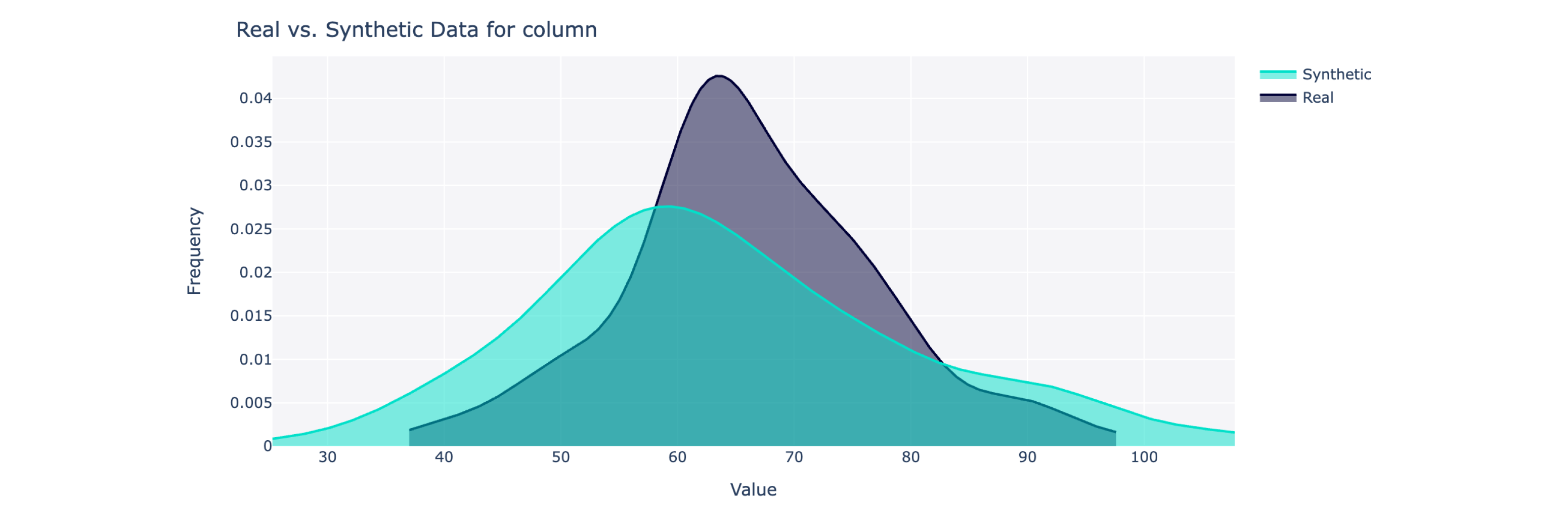
使用SDV庫,您可以合成單表、多表和順序資料。您還可以自訂完整的合成資料工作流程,包括預處理、匿名化和新增約束。
要了解更多信息,請訪問 SDV 演示頁面。
感謝我們多年來建立和維護 SDV 生態系統的貢獻者團隊!
查看貢獻者
如果您使用 SDV 進行研究,請引用以下論文:
尼哈·帕特基、羅伊·韋奇、卡揚·維拉馬查內尼。綜合資料庫。 IEEE DSAA 2016。
@inproceedings{
SDV,
title={The Synthetic data vault},
author={Patki, Neha and Wedge, Roy and Veeramachaneni, Kalyan},
booktitle={IEEE International Conference on Data Science and Advanced Analytics (DSAA)},
year={2016},
pages={399-410},
doi={10.1109/DSAA.2016.49},
month={Oct}
}
綜合資料庫計畫於 2016 年在麻省理工學院的數據到人工智慧實驗室首次創建。如今,DataCebo 是 SDV 的自豪開發商,SDV 是最大的合成資料生成和評估生態系統。它是多個支援合成資料的庫的所在地,包括:
開始使用 SDV 套件——一個完全整合的解決方案和合成資料的一站式商店。或者,使用獨立庫來滿足特定需求。


