LipGER
Initial Release
這是我們在 InterSpeech 2024 上被選為口頭報告的論文 LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition 的官方實作。
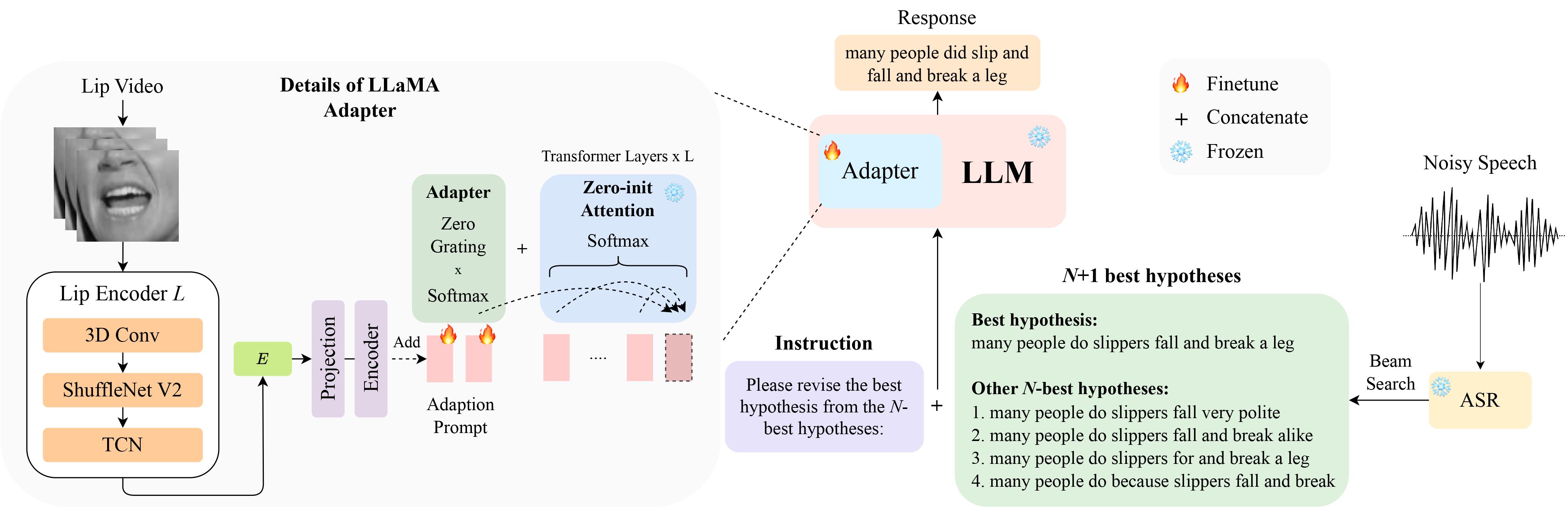
您可以從這裡下載 LipHyp 資料!
pip install -r requirements.txt
首先使用以下方法準備檢查點:
pip install huggingface_hub
python scripts/download.py --repo_id meta-llama/Llama-2-7b-chat-hf --token your_hf_token
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/meta-llama/Llama-2-7b-chat-hf若要查看所有可用的檢查點,請執行:
python scripts/download.py | grep Llama-2更多詳細信息,您還可以參考此鏈接,您還可以在其中為其他模型準備其他檢查點。具體來說,我們使用 TinyLlama 進行實驗。
檢查站位於此處。下載後,在這裡更改檢查點的路徑。
LipGER 期望所有訓練、驗證和測試檔案都採用sample_data.json 的格式。文件中的一個實例如下所示:
{
"Dataset": "dataset_name",
"Uid": "unique_id",
"Caption": "The ground truth transcription.",
"Noisy_Wav": "path_to_noisy_wav",
"Mouthroi": "path_to_mouth_roi_mp4",
"Video": "path_to_video_mp4",
"nhyps_base": [ list of N-best hypotheses ],
}
您需要將語音檔案傳遞給經過訓練的 ASR 模型,該模型能夠產生 N 個最佳假設。我們在此儲存庫中提供了兩種方法來幫助您實現這一目標。請隨意使用其他方法。
pip install whisper安裝 Whisper,然後從data資料夾執行 nhyps.py,那麼您應該沒問題!請注意,對於這兩種方法,列表中的第一個是最佳假設,其他是 N 個最佳假設(它們作為 JSON 的列表nhyps_base欄位傳遞,並用於在後續步驟中建構提示)。
此外,所提供的方法僅使用語音作為輸入。對於視聽 N 最佳假設生成,我們使用了 Auto-AVSR。如果您需要程式碼方面的協助,請提出問題!
假設您的所有語音檔案都有相應的視頻,請按照以下步驟從視頻中裁剪嘴部 ROI。
python crop_mouth_script.py
python covert_lip.py
這會將 mp4 ROI 轉換為 hdf5,程式碼將在同一 json 檔案中將 mp4 ROI 的路徑變更為 hdf5 ROI。您可以透過變更default.yaml中的「偵測器」來選擇「mediapipe」和「retinaface」偵測器
獲得 N 個最佳假設後,以所需格式建立 JSON 檔案。我們不提供這部分的具體程式碼,因為每個人的資料準備可能會有所不同,但程式碼應該很簡單。再次強調,如果您有任何疑問,請提出問題!
LipGER 訓練腳本不採用 JSON 進行訓練或評估。您需要將它們轉換為 pt 檔案。您可以運行convert_to_pt.py來實現這一點!根據您的意願在第 27 行更改model_name ,並在第 58 行中新增 JSON 的路徑。
要微調 LipGER,只需運行:
sh finetune.sh
您需要手動設定data值(使用資料集名稱)、 --train_path和--val_path (使用訓練和有效 .pt 檔案的絕對路徑)。
為了進行推理,首先更改 lipger.py 中的對應路徑( exp_path和checkpoint_dir ),然後執行(使用適當的測試資料路徑參數):
sh infer.sh
裁切嘴巴 ROI 的程式碼受到 Visual_Speech_Recognition_for_Multiple_Languages 的啟發。
我們的 LipGER 程式碼受到 RobustGER 的啟發。如果您發現我們的論文或程式碼有用,也請引用他們的論文。
@inproceedings{ghosh23b_interspeech,
author={Sreyan Ghosh and Sonal Kumar and Ashish Seth and Purva Chiniya and Utkarsh Tyagi and Ramani Duraiswami and Dinesh Manocha},
title={{LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition}},
year=2024,
booktitle={Proc. INTERSPEECH 2024},
}


