self instruct
1.0.0
該儲存庫包含 Self-Instruct 論文的程式碼和數據,這是一種將預訓練語言模型與指令對齊的方法。
Self-Instruct 是一個幫助語言模型提高遵循自然語言指令的能力的框架。它透過使用模型自己的一代來創建大量教學數據來實現這一點。透過自指令,可以提高語言模型的指令追蹤能力,而無需依賴大量的手動註解。
近年來,人們對建立能夠遵循自然語言指令來執行各種任務的模型越來越感興趣。這些模型被稱為「指令調整」語言模型,已經證明了泛化到新任務的能力。然而,它們的性能在很大程度上取決於用於訓練它們的人工編寫的指令資料的品質和數量,而這些資料的多樣性和創造力可能受到限制。為了克服這些限制,開發替代方法來監督指令調整模型並提高其指令追蹤能力非常重要。
自指令過程是一種迭代引導演算法,它從手動編寫的指令種子集開始,並使用它們提示語言模型產生新指令和相應的輸入輸出實例。然後對這些生成進行過濾,以刪除低品質或相似的生成,並將生成的資料添加回任務池。這個過程可以重複多次,從而產生大量的教學數據,可用於微調語言模型以更有效地遵循指令。
以下是自我指導的概述:
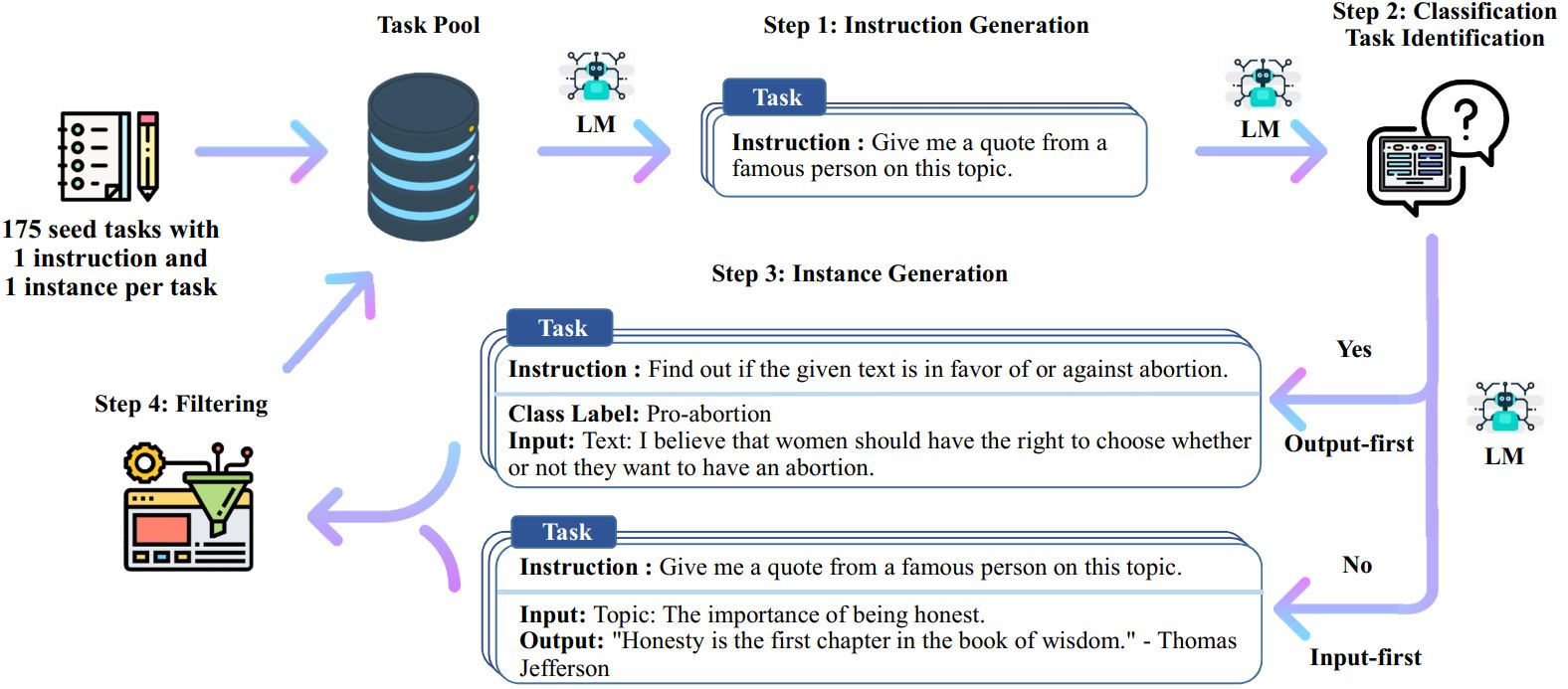
*這項工作仍在進行中。隨著進展,我們可能會更新程式碼和資料。請謹慎對待版本控制。
我們發布了一個包含 52k 條指令的資料集,與 82K 實例輸入和輸出配對。這些指令資料可以用來對語言模型進行指令調優,使語言模型更能遵循指令。整個模型產生的資料可以在data/gpt3-generations/batch_221203/all_instances_82K.jsonl中存取。以乾淨的 GPT3-finetuning 格式(提示 + 完成)重新格式化的資料(+ 175 個種子任務)放入data/finetuning/self_instruct_221203中。您可以使用./scripts/finetune_gpt3.sh中的腳本對此資料微調 GPT3。
注意:該數據由語言模型(GPT3)生成,不可避免地包含一些錯誤或偏差。我們分析了論文中 200 個隨機指令的資料質量,發現 46% 的資料點可能有問題。我們鼓勵用戶謹慎使用這些數據,並提出新的方法來過濾或改進缺陷。
我們還發布了一組新的 252 個專家編寫的任務及其由面向用戶的應用程式(而不是經過充分研究的 NLP 任務)驅動的指令。此數據用於自學論文的人類評估部分。有關更多詳細信息,請參閱人工評估自述文件。
為了使用您自己的種子任務或其他模型生成自指導數據,我們在此處開源了整個管道的腳本。我們目前的程式碼僅在可透過 OpenAI API 存取的 GPT3 模型上進行了測試。
以下是產生資料的腳本:
# 1. 從種子任務產生指令。 . 過濾、處理和重新格式化./scripts/prepare_for_finetuning.sh
如果您使用自學框架或數據,請隨時引用我們。
@misc{selfinstruct, title={Self-Instruct: 將語言模型與自生成指令對齊},作者={Wang、Yizhong 和Kordi、Yeganeh 和Mishra、Swaroop 和Liu、Alisa 和Smith、Noah A. 和Khashabi、Daniel和Hajishirzi, Hannaneh},期刊={arXiv 預印本 arXiv:2212.10560},年份={2022}} 

