

鎮上的新機器人:SO-100

我們剛剛添加了一個關於如何構建更實惠的機器人的新教程,每隻手臂的價格為 110 美元!
只需使用筆記型電腦向其展示一些動作即可教它新技能。
然後觀看你自製的機器人自主行動?
點擊連結查看 SO-100 的完整教學。
LeRobot:用於現實世界機器人的最先進的人工智慧
? LeRobot 旨在為 PyTorch 中的現實世界機器人提供模型、資料集和工具。目標是降低進入機器人技術的門檻,以便每個人都可以做出貢獻並從共享資料集和預訓練模型中受益。
? LeRobot包含最先進的方法,這些方法已被證明可以轉移到現實世界,重點是模仿學習和強化學習。
?樂機器人已經提供了一組預訓練模型、包含人類收集演示的資料集以及無需組裝機器人即可開始使用的模擬環境。在未來幾週內,該計劃將在最實惠、功能最強大的機器人上增加對現實世界機器人技術的越來越多的支援。
? LeRobot 在這個 Hugging Face 社群頁面上託管預訓練的模型和資料集:huggingface.co/lerobot
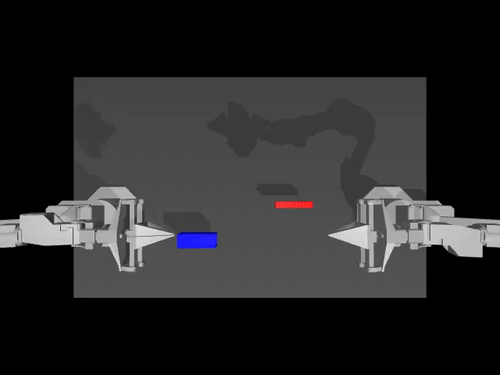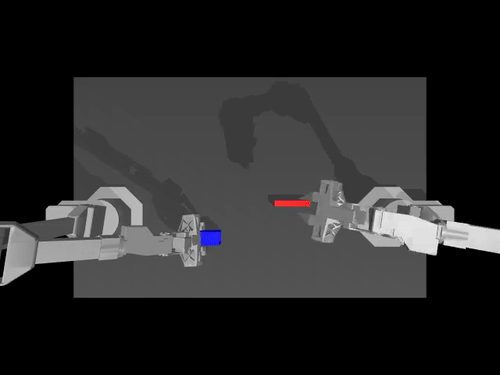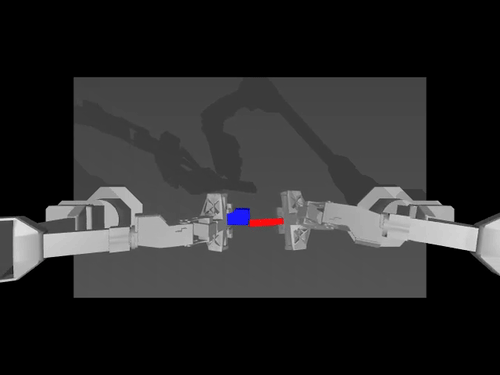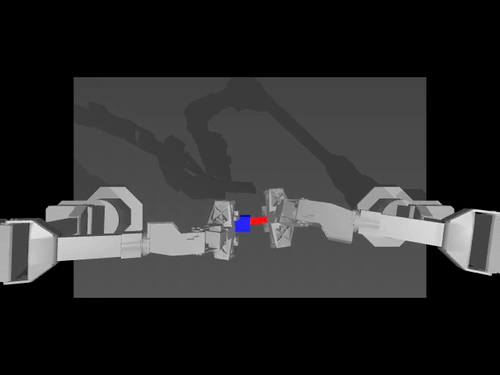 |  |  |
| ACT 關於 ALOHA env 的政策 | SimXArm 環境上的 TDMPC 策略 | PushT 環境上的擴散策略 |
下載我們的原始碼:
git clone https://github.com/huggingface/lerobot.git
cd lerobot使用 Python 3.10 建立虛擬環境並啟動它,例如使用miniconda :
conda create -y -n lerobot python=3.10
conda activate lerobot安裝 ?樂機器人:
pip install -e .注意:根據您的平台,如果在此步驟中遇到任何建置錯誤,您可能需要安裝
cmake和build-essential來建立我們的一些依賴項。在 Linux 上:sudo apt-get install cmake build-essential
對於模擬, ?樂機器人配有健身房環境,可作為額外安裝:
例如,要安裝? LeRobot 與 Aloha 和 Pusht,使用:
pip install -e " .[aloha, pusht] "要使用權重和偏差進行實驗跟踪,請使用以下身份登錄
wandb login(注意:您還需要在設定中啟用 WandB。請參閱下文。)
.
├── examples # contains demonstration examples, start here to learn about LeRobot
| └── advanced # contains even more examples for those who have mastered the basics
├── lerobot
| ├── configs # contains hydra yaml files with all options that you can override in the command line
| | ├── default.yaml # selected by default, it loads pusht environment and diffusion policy
| | ├── env # various sim environments and their datasets: aloha.yaml, pusht.yaml, xarm.yaml
| | └── policy # various policies: act.yaml, diffusion.yaml, tdmpc.yaml
| ├── common # contains classes and utilities
| | ├── datasets # various datasets of human demonstrations: aloha, pusht, xarm
| | ├── envs # various sim environments: aloha, pusht, xarm
| | ├── policies # various policies: act, diffusion, tdmpc
| | ├── robot_devices # various real devices: dynamixel motors, opencv cameras, koch robots
| | └── utils # various utilities
| └── scripts # contains functions to execute via command line
| ├── eval.py # load policy and evaluate it on an environment
| ├── train.py # train a policy via imitation learning and/or reinforcement learning
| ├── control_robot.py # teleoperate a real robot, record data, run a policy
| ├── push_dataset_to_hub.py # convert your dataset into LeRobot dataset format and upload it to the Hugging Face hub
| └── visualize_dataset.py # load a dataset and render its demonstrations
├── outputs # contains results of scripts execution: logs, videos, model checkpoints
└── tests # contains pytest utilities for continuous integration
請參閱範例 1,它說明如何使用我們的資料集類別自動從 Hugging Face 中心下載資料。
您也可以透過從命令列執行我們的腳本來本地視覺化集線器上資料集的劇集:
python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0或來自具有根DATA_DIR環境變數的本機資料夾中的資料集(在下列情況下,將在./my_local_data_dir/lerobot/pusht中搜尋資料集)
DATA_DIR= ' ./my_local_data_dir ' python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0它將打開rerun.io並顯示相機流、機器人狀態和動作,如下所示:
我們的腳本還可以視覺化儲存在遠端伺服器上的資料集。如需更多說明,請參閱python lerobot/scripts/visualize_dataset.py --help 。
LeRobotDataset格式LeRobotDataset格式的資料集使用起來非常簡單。它可以從 Hugging Face hub 上的儲存庫或本機資料夾中加載,例如dataset = LeRobotDataset("lerobot/aloha_static_coffee")並且可以像任何 Hugging Face 和 PyTorch 資料集一樣進行索引。例如, dataset[0]將從資料集中檢索單一時間幀,其中包含觀察結果和一個動作,作為準備輸入模型的 PyTorch 張量。
LeRobotDataset的特殊性在於,我們不是透過索引檢索單一幀,而是可以透過將delta_timestamps設定為相對於索引幀的相對時間列表,根據它們與索引幀的時間關係來檢索多個幀。例如,使用delta_timestamps = {"observation.image": [-1, -0.5, -0.2, 0]}對於給定索引,可以檢索 4 個幀:3 個「前一」幀 1 秒、0.5 秒,以及索引幀之前0.2 秒以及索引幀本身(對應0 個條目)。有關delta_timestamps的更多詳細信息,請參閱範例 1_load_lerobot_dataset.py 。
在幕後, LeRobotDataset格式使用多種方法來序列化數據,如果您打算更密切地使用此格式,這對於理解數據很有用。我們試圖製作一種靈活而簡單的資料集格式,涵蓋強化學習和機器人技術、模擬和現實世界中存在的大多數類型的特徵和特性,重點是相機和機器人狀態,但很容易擴展到其他類型的感官只要輸入可以用張量表示即可。
以下是使用dataset = LeRobotDataset("lerobot/aloha_static_coffee")實例化的典型LeRobotDataset的重要細節和內部結構組織。確切的特徵會隨著資料集的不同而改變,但主要方面不會改變:
dataset attributes:
├ hf_dataset: a Hugging Face dataset (backed by Arrow/parquet). Typical features example:
│ ├ observation.images.cam_high (VideoFrame):
│ │ VideoFrame = {'path': path to a mp4 video, 'timestamp' (float32): timestamp in the video}
│ ├ observation.state (list of float32): position of an arm joints (for instance)
│ ... (more observations)
│ ├ action (list of float32): goal position of an arm joints (for instance)
│ ├ episode_index (int64): index of the episode for this sample
│ ├ frame_index (int64): index of the frame for this sample in the episode ; starts at 0 for each episode
│ ├ timestamp (float32): timestamp in the episode
│ ├ next.done (bool): indicates the end of en episode ; True for the last frame in each episode
│ └ index (int64): general index in the whole dataset
├ episode_data_index: contains 2 tensors with the start and end indices of each episode
│ ├ from (1D int64 tensor): first frame index for each episode — shape (num episodes,) starts with 0
│ └ to: (1D int64 tensor): last frame index for each episode — shape (num episodes,)
├ stats: a dictionary of statistics (max, mean, min, std) for each feature in the dataset, for instance
│ ├ observation.images.cam_high: {'max': tensor with same number of dimensions (e.g. `(c, 1, 1)` for images, `(c,)` for states), etc.}
│ ...
├ info: a dictionary of metadata on the dataset
│ ├ codebase_version (str): this is to keep track of the codebase version the dataset was created with
│ ├ fps (float): frame per second the dataset is recorded/synchronized to
│ ├ video (bool): indicates if frames are encoded in mp4 video files to save space or stored as png files
│ └ encoding (dict): if video, this documents the main options that were used with ffmpeg to encode the videos
├ videos_dir (Path): where the mp4 videos or png images are stored/accessed
└ camera_keys (list of string): the keys to access camera features in the item returned by the dataset (e.g. `["observation.images.cam_high", ...]`)
LeRobotDataset的每個部分使用幾種廣泛使用的檔案格式進行序列化,即:
safetensor張量序列化格式儲存safetensor張量序列化格式儲存的統計資料資料集可以從 HuggingFace 中心無縫上傳/下載。若要處理本機資料集,您可以將DATA_DIR環境變數設定為根資料集資料夾,如上面有關資料集視覺化的部分所示。
請參閱範例 2,此範例示範如何從 Hugging Face 中心下載預訓練策略,並在其對應的環境中執行評估。
我們還提供了一個功能更強大的腳本,可以在同一部署過程中並行評估多個環境。以下是 lerobot/diffusion_pusht 上託管的預訓練模型的範例:
python lerobot/scripts/eval.py
-p lerobot/diffusion_pusht
eval.n_episodes=10
eval.batch_size=10注意:訓練自己的策略後,您可以使用以下方法重新評估檢查點:
python lerobot/scripts/eval.py -p {OUTPUT_DIR}/checkpoints/last/pretrained_model如需更多說明,請參閱python lerobot/scripts/eval.py --help 。
請參閱範例 3,它示範如何使用我們的 Python 核心庫來訓練模型,範例 4 示範如何從命令列使用我們的訓練腳本。
一般來說,您可以使用我們的訓練腳本輕鬆訓練任何策略。以下是在 Aloha 模擬環境中根據人類收集的軌跡訓練 ACT 策略以執行插入任務的範例:
python lerobot/scripts/train.py
policy=act
env=aloha
env.task=AlohaInsertion-v0
dataset_repo_id=lerobot/aloha_sim_insertion_human 實驗目錄是自動產生的,並將在您的終端中顯示為黃色。它看起來像outputs/train/2024-05-05/20-21-12_aloha_act_default 。您可以將此參數新增至train.py python 指令來手動指定實驗目錄:
hydra.run.dir=your/new/experiment/dir在實驗目錄中會有一個名為checkpoints的資料夾,其架構如下:
checkpoints
├── 000250 # checkpoint_dir for training step 250
│ ├── pretrained_model # Hugging Face pretrained model dir
│ │ ├── config.json # Hugging Face pretrained model config
│ │ ├── config.yaml # consolidated Hydra config
│ │ ├── model.safetensors # model weights
│ │ └── README.md # Hugging Face model card
│ └── training_state.pth # optimizer/scheduler/rng state and training step若要從檢查點恢復訓練,您可以將這些新增到train.py python 命令中:
hydra.run.dir=your/original/experiment/dir resume=true它將載入預訓練模型、優化器和調度器狀態進行訓練。有關更多信息,請參閱此處有關恢復訓練的教程。
若要使用 wandb 記錄訓練和評估曲線,請確保您已將wandb login作為一次性設定步驟運行。然後,在執行上面的訓練命令時,透過新增以下內容在組態中啟用 WandB:
wandb.enable=true運行的 wandb 日誌的連結也會在終端中以黃色顯示。以下是它們在瀏覽器中的外觀範例。另請查看此處以了解日誌中一些常用指標的說明。

注意:為了提高效率,在訓練期間,每個檢查點都會在少量的劇集上進行評估。您可以使用eval.n_episodes=500來評估比預設值更多的劇集。或者,訓練後,您可能想要重新評估更多劇集的最佳檢查點或更改評估設定。如需更多說明,請參閱python lerobot/scripts/eval.py --help 。
我們組織了我們的配置檔案(在lerobot/configs下找到),以便它們在各自的原始作品中重現給定模型變體的 SOTA 結果。只需運行:
python lerobot/scripts/train.py policy=diffusion env=pusht重現 PushT 任務上擴散策略的 SOTA 結果。
預訓練策略以及複製詳細資訊可以在 https://huggingface.co/lerobot 的「模型」部分找到。
如果您願意為 ?樂機器人,請查看我們的貢獻指南。
要將資料集新增至中心,您需要使用寫入存取權杖登錄,該令牌可以從 Hugging Face 設定產生:
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential然後指向您的原始資料集資料夾(例如data/aloha_static_pingpong_test_raw ),並使用以下命令將資料集推送到集線器:
python lerobot/scripts/push_dataset_to_hub.py
--raw-dir data/aloha_static_pingpong_test_raw
--out-dir data
--repo-id lerobot/aloha_static_pingpong_test
--raw-format aloha_hdf5如需更多說明,請參閱python lerobot/scripts/push_dataset_to_hub.py --help 。
如果您的資料集格式不受支持,請透過複製諸如 Pusht_zarr、umi_zarr、aloha_hdf5 或 xarm_pkl 之類的範例,在lerobot/common/datasets/push_dataset_to_hub/${raw_format}_format.py中實作您自己的資料集格式。
訓練策略後,您可以使用類似${hf_user}/${repo_name} (例如 lerobot/diffusion_pusht)的集線器 ID 將其上傳到 Hugging Face 中心。
您首先需要找到位於實驗目錄中的檢查點資料夾(例如outputs/train/2024-05-05/20-21-12_aloha_act_default/checkpoints/002500 )。其中有一個pretrained_model目錄,其中應包含:
config.json :策略配置的序列化版本(遵循策略的資料類別配置)。model.safetensors :一組torch.nn.Module參數,以 Hugging Face Safetensors 格式儲存。config.yaml :包含策略、環境和資料集配置的整合 Hydra 訓練配置。策略配置應與config.json完全匹配。環境配置對於任何想要評估您的策略的人都很有用。資料集配置只是作為可重複性的書面記錄。若要將這些上傳到中心,請執行以下命令:
huggingface-cli upload ${hf_user} / ${repo_name} path/to/pretrained_model有關其他人如何使用您的策略的範例,請參閱 eval.py。
用於分析策略評估的程式碼片段範例:
from torch . profiler import profile , record_function , ProfilerActivity
def trace_handler ( prof ):
prof . export_chrome_trace ( f"tmp/trace_schedule_ { prof . step_num } .json" )
with profile (
activities = [ ProfilerActivity . CPU , ProfilerActivity . CUDA ],
schedule = torch . profiler . schedule (
wait = 2 ,
warmup = 2 ,
active = 3 ,
),
on_trace_ready = trace_handler
) as prof :
with record_function ( "eval_policy" ):
for i in range ( num_episodes ):
prof . step ()
# insert code to profile, potentially whole body of eval_policy function 如果您願意,您可以透過以下方式引用這項工作:
@misc { cadene2024lerobot ,
author = { Cadene, Remi and Alibert, Simon and Soare, Alexander and Gallouedec, Quentin and Zouitine, Adil and Wolf, Thomas } ,
title = { LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch } ,
howpublished = " url{https://github.com/huggingface/lerobot} " ,
year = { 2024 }
}此外,如果您正在使用任何特定的策略架構、預訓練模型或資料集,建議引用該作品的原始作者,如下所示:
@article { chi2024diffusionpolicy ,
author = { Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song } ,
title = { Diffusion Policy: Visuomotor Policy Learning via Action Diffusion } ,
journal = { The International Journal of Robotics Research } ,
year = { 2024 } ,
} @article { zhao2023learning ,
title = { Learning fine-grained bimanual manipulation with low-cost hardware } ,
author = { Zhao, Tony Z and Kumar, Vikash and Levine, Sergey and Finn, Chelsea } ,
journal = { arXiv preprint arXiv:2304.13705 } ,
year = { 2023 }
} @inproceedings { Hansen2022tdmpc ,
title = { Temporal Difference Learning for Model Predictive Control } ,
author = { Nicklas Hansen and Xiaolong Wang and Hao Su } ,
booktitle = { ICML } ,
year = { 2022 }
} @article { lee2024behavior ,
title = { Behavior generation with latent actions } ,
author = { Lee, Seungjae and Wang, Yibin and Etukuru, Haritheja and Kim, H Jin and Shafiullah, Nur Muhammad Mahi and Pinto, Lerrel } ,
journal = { arXiv preprint arXiv:2403.03181 } ,
year = { 2024 }
}

