EasyOCR
v1.7.2
即用型 OCR,支援 80 多種語言和所有流行的書寫腳本,包括:拉丁文、中文、阿拉伯文、梵文、西里爾文等。
在我們的網站上嘗試演示
融入 Huggingface 空間?使用Gradio。試試網路示範:
2024 年 9 月 24 日 - 版本 1.7.2
閱讀所有發行說明



使用pip安裝
對於最新的穩定版本:
pip install easyocr對於最新的開發版本:
pip install git+https://github.com/JaidedAI/EasyOCR.git註 1:對於 Windows,請先按照官方說明安裝 torch 和 torchvision https://pytorch.org。在 pytorch 網站上,請務必選擇您擁有的正確的 CUDA 版本。如果您打算僅在 CPU 模式下執行,請選擇CUDA = None 。
註2:我們在這裡也提供了一個Dockerfile。
import easyocr
reader = easyocr . Reader ([ 'ch_sim' , 'en' ]) # this needs to run only once to load the model into memory
result = reader . readtext ( 'chinese.jpg' )輸出將採用清單格式,每個項目分別代表一個邊界框、偵測到的文字和置信度。
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路' , 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西' , 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东' , 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], ' 315 ' , 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], ' 309 ' , 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], ' Yuyuan Rd. ' , 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], ' W ' , 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], ' E ' , 0.8405593633651733)]註1: ['ch_sim','en']是您要閱讀的語言清單。您可以同時傳遞多種語言,但並非所有語言都可以一起使用。英語與所有語言相容,具有共同字元的語言通常彼此相容。
註 2:除了檔案路徑chinese.jpg之外,您還可以傳遞 OpenCV 圖像物件(numpy 陣列)或圖像檔案作為位元組。原始圖像的 URL 也是可以接受的。
註3:行reader = easyocr.Reader(['ch_sim','en'])用於將模型載入到記憶體中。這需要一些時間,但只需運行一次。
您也可以設定detail=0以獲得更簡單的輸出。
reader . readtext ( 'chinese.jpg' , detail = 0 )結果:
[ '愚园路' , '西' , '东' , ' 315 ' , ' 309 ' , ' Yuyuan Rd. ' , ' W ' , ' E ' ]所選語言的模型權重將自動下載,或者您可以從模型中心手動下載它們並將其放入“~/.EasyOCR/model”資料夾中
如果您沒有 GPU,或者您的 GPU 記憶體不足,您可以透過新增gpu=False以僅 CPU 模式運行模型。
reader = easyocr . Reader ([ 'ch_sim' , 'en' ], gpu = False )有關更多信息,請閱讀教程和 API 文件。
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=True對於識別模型,請閱讀此處。
對於檢測模型 (CRAFT),請閱讀此處。
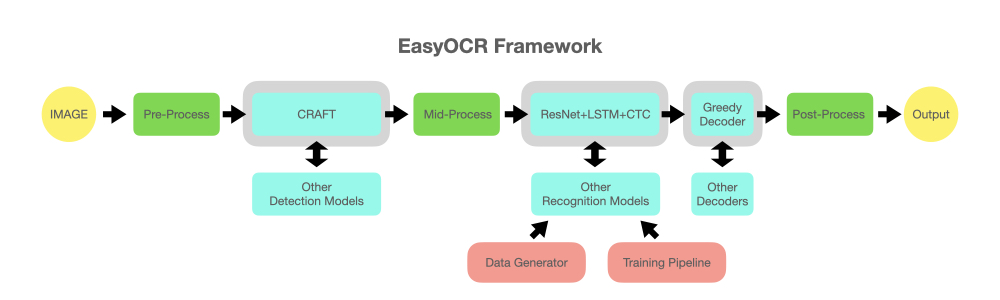
reader = easyocr . Reader ([ 'en' ], detection = 'DB' , recognition = 'Transformer' )我們的想法是能夠將任何最先進的型號插入 EasyOCR。有很多天才試圖做出更好的檢測/識別模型,但我們並不是想成為天才。我們只是想讓大眾能夠快速、免費地接觸他們的作品。 (好吧,我們相信大多數天才都希望他們的工作盡可能快/盡可能大地產生積極影響)管道應該如下圖所示。灰色插槽是可更換淺藍色模組的佔位符。
該專案基於多篇論文和開源存儲庫的研究和程式碼。
所有深度學習執行均基於 Pytorch。 ❤️
檢測執行使用此官方儲存庫及其論文中的 CRAFT 演算法(感謝來自 @clovaai 的 @YoungminBaek)。我們也使用他們的預訓練模型。訓練腳本由@gmuffiness 提供。
辨識模型是CRNN(論文)。它由 3 個主要組件組成:特徵提取(我們目前使用 Resnet)和 VGG、序列標記(LSTM)和解碼(CTC)。用於識別執行的訓練管道是深度文字辨識基準框架的修改版本。 (感謝@clovaai 的@ku21fan)這個儲存庫是一個值得更多認可的寶石。
Beam 搜尋程式碼基於此儲存庫和他的部落格。 (感謝@githubharald)
資料合成基於TextRecognitionDataGenerator。 (感謝@Belval)
在這裡,您可以從 distill.pub 閱讀有關 CTC 的精彩內容。
讓我們共同進步人類,讓人工智慧為每個人所用!
3 種貢獻方式:
編碼員:請發送 PR 以了解小錯誤/改進。對於更大的問題,請先打開問題與我們討論。有一個可能的錯誤/改進問題的列表,標記為“PR WELCOME”。
使用者:告訴我們 EasyOCR 如何使您/您的組織受益,以鼓勵進一步發展。也在問題部分發布失敗案例以幫助改進未來的模型。
技術負責人/大師:如果您發現這個庫有用,請傳播! (請參閱 Yann Lecun 關於 EasyOCR 的文章)
要請求新語言,我們需要您傳送包含以下 2 個檔案的 PR:
如果您的語言有獨特的元素(例如 1. 阿拉伯語:字符相互連接時會改變形式 + 從右向左書寫 2. 泰語:有些字符需要位於行上方,有些位於行下方),請教育我們最好您的能力和/或提供有用的連結。為了實現真正有效的系統,專注於細節非常重要。
最後,請瞭解,我們的優先順序必須是流行語言或彼此共享大部分字元的語言集(也請告訴我們您的語言是否屬於這種情況)。我們至少需要一周的時間來開發新型號,因此您可能需要等待一段時間才能發布新型號。
請參閱正在開發的語言列表
由於資源有限,超過 6 個月的問題將自動關閉。如果問題很關鍵,請再次開啟問題。
對於企業支持,Jaided AI 為客製化 OCR/AI 系統提供從實施、培訓/微調到部署的全方位服務。點擊此處聯絡我們。


