LVBench
1.0.0
[專案頁] [ arXiv 論文] [ 資料集][?排行榜][?擁抱排行榜]
LVBench 是一個基準測試,旨在評估和增強多模態模型從長達兩小時的長影片中理解和提取資訊的能力。
2024.08.2我們在 Huggingface Spaces 上設定了 LVBench 排行榜!查看排行榜。
2024.06.11我們發布了長視頻理解新基準LVBench!
LVBench 是一個旨在評估模型理解長視訊能力的基準。我們從公共來源收集了大量的長視訊數據,並透過手動操作和模型輔助進行註釋。我們的基準測試為在擴展時間上下文中測試模型提供了堅實的基礎,透過細緻的人工註釋和多階段品質控制確保高品質的評估。
核心能力:長影片理解的六大核心能力,能夠創建複雜且具挑戰性的問題以進行全面的模型評估。
多樣化數據:多樣化的長影片數據,平均比現有最長數據集長五倍,涵蓋各個類別。
高品質註釋:可靠的基準,具有細緻的人工註釋和多階段品質控制流程。

我們的資料集採用 CC-BY-NC-SA-4.0 授權。
LVBench 僅用於學術研究。禁止任何形式的商業用途。我們不擁有任何原始視訊檔案的版權。
如果LVBench有侵權行為,請聯絡[email protected]或直接提出issue,我們將立即刪除。
首先安裝video2dataset:
pip 安裝 video2dataset pip 卸載變壓器引擎
然後你應該從 Huggingface 下載video_info.meta.jsonl並將其放在data目錄中。
video_info.meta.jsonl檔案中的每個條目都有一個與 YouTube 影片 ID 相對應的關鍵欄位。使用者可以使用該ID下載對應的影片。或者,使用者可以使用我們提供的下載腳本download.sh進行下載:
光碟腳本 bash下載.sh
執行後,視訊檔案將存放在script/videos目錄下。
pip install -e 。
(附註:如果您想快速嘗試評估,可以使用scripts/construct_random_answers.py準備隨機答案檔。)
光碟腳本 python test_acc.py
執行完成後,會在scripts目錄下得到一個評估結果檔result.json 。您可以將結果提交到排行榜。
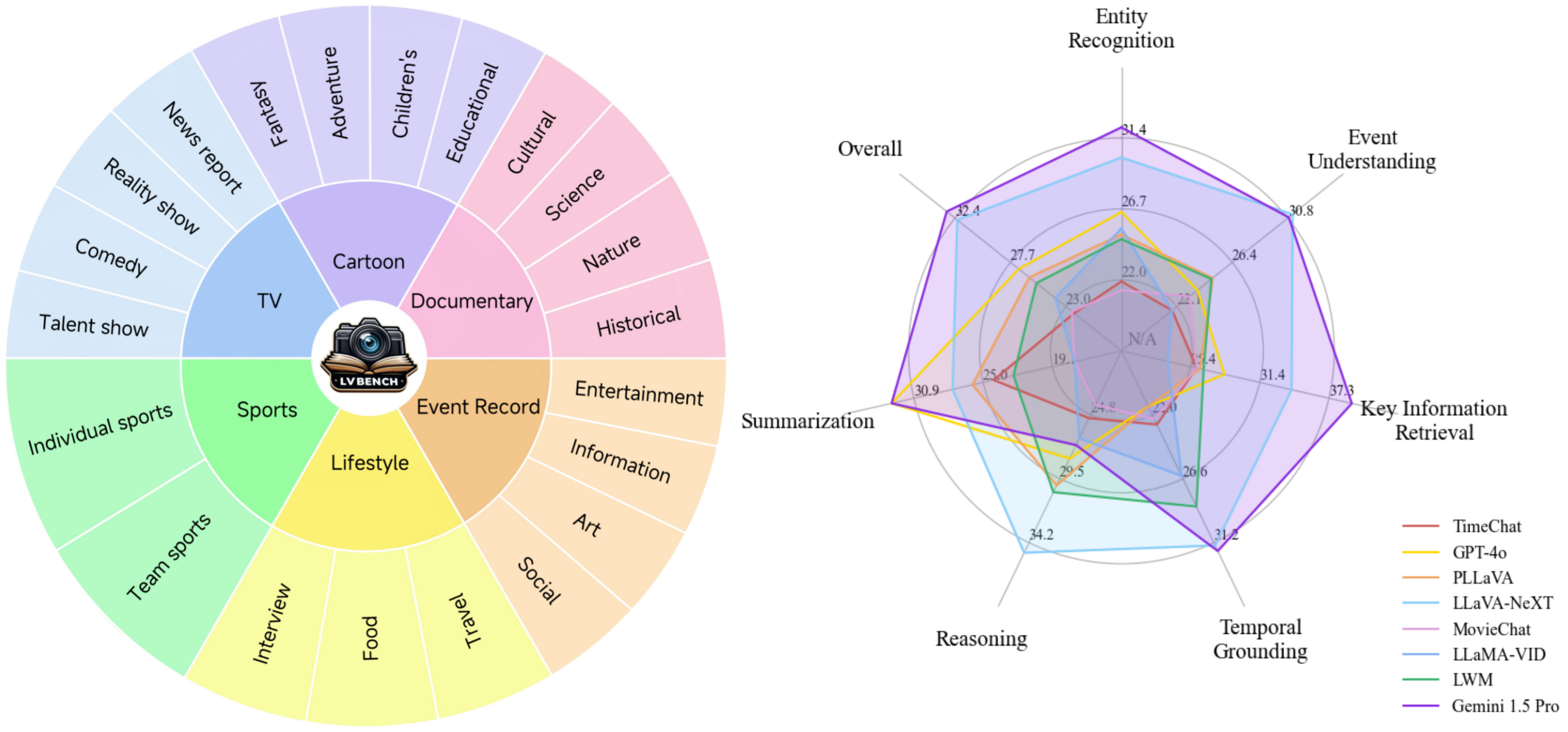
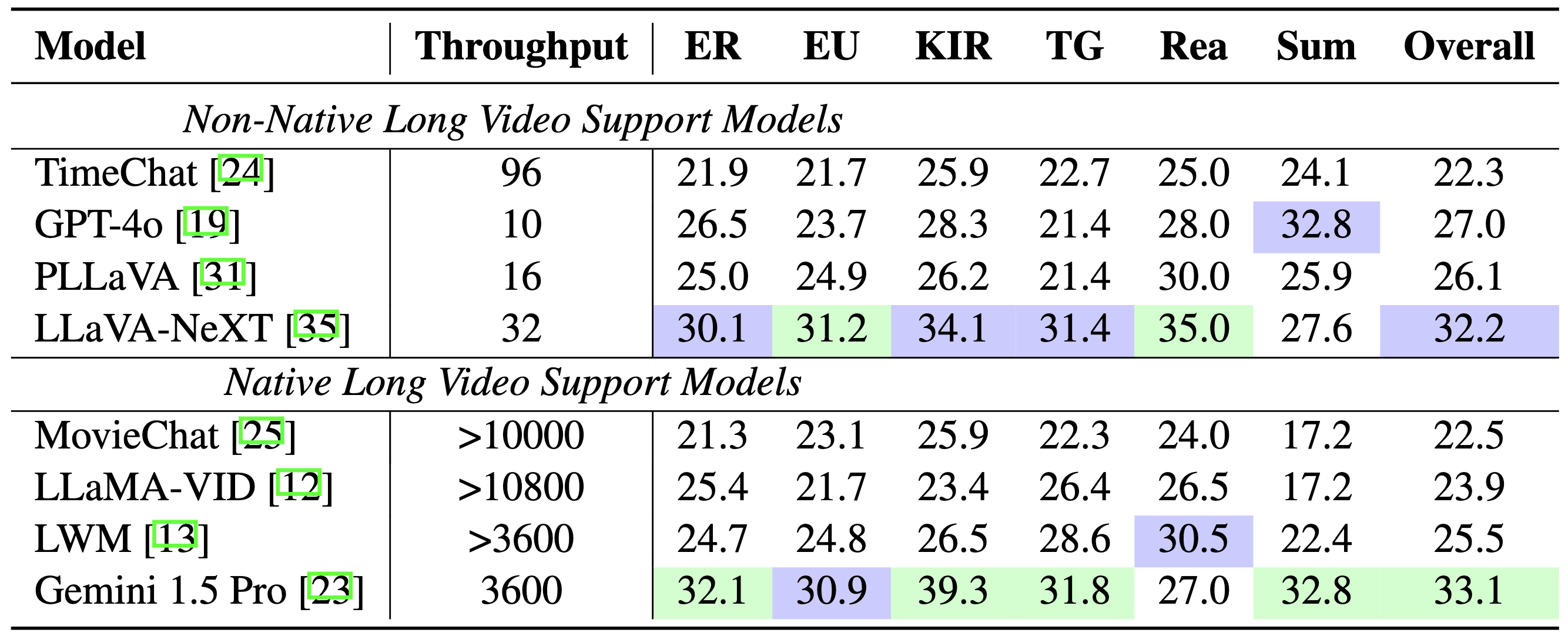
型號對比:
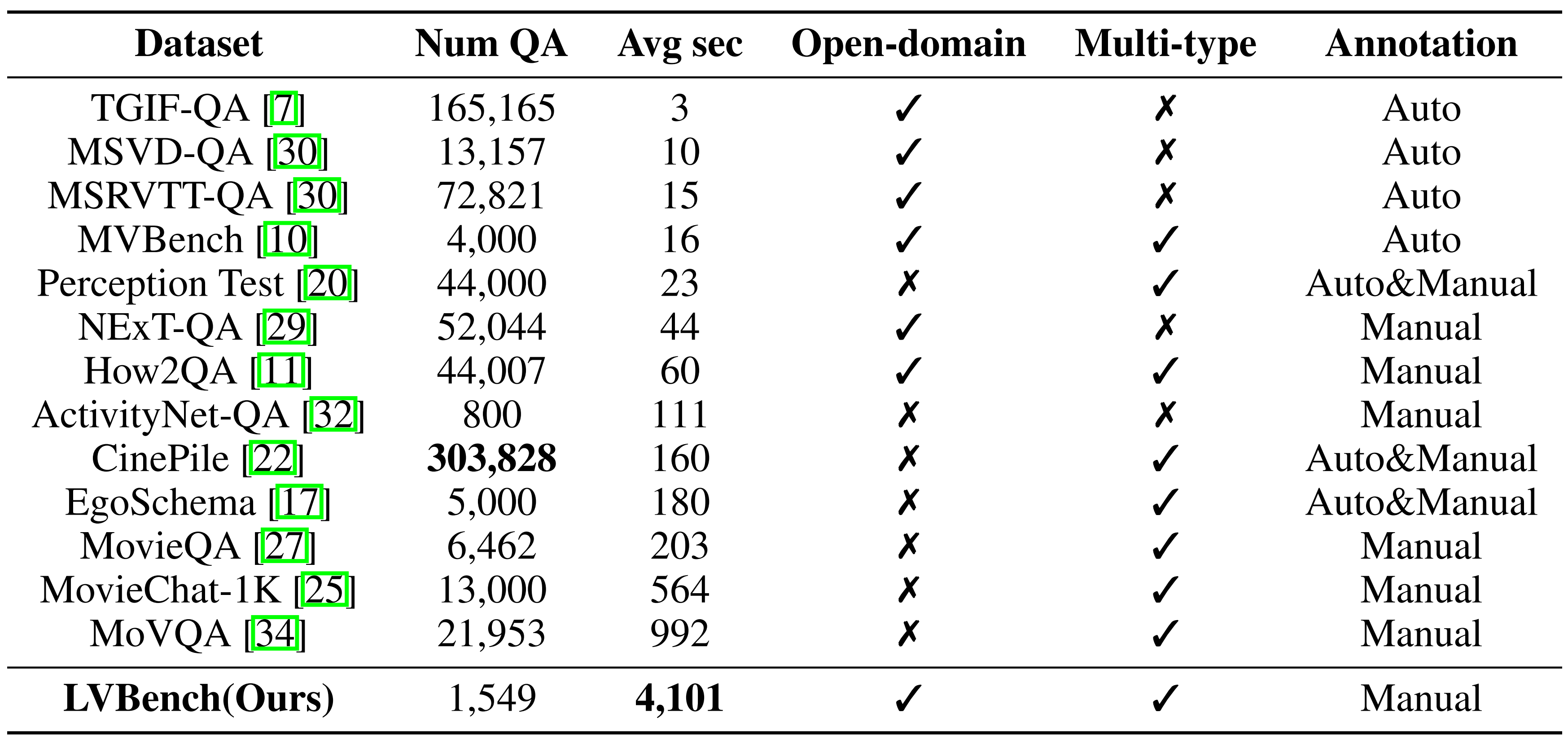
基準比較:
模型與人類:

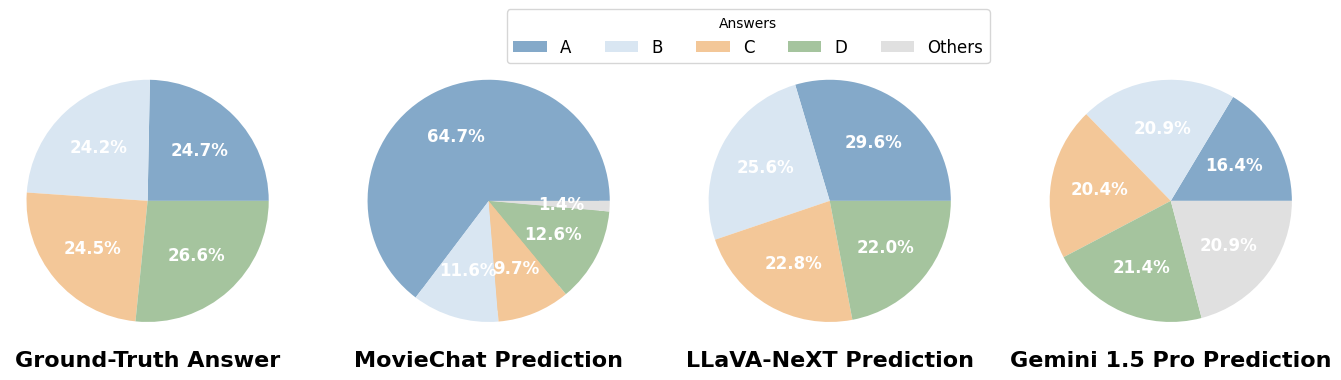
答案分佈:
如果您發現我們的工作對您的研究有幫助,請考慮引用我們的工作。
@misc{wang2024lvbench, title={LVBench:超長視頻理解基準},
作者={Weihan Wang、Zehai He、Wenyi Hong、Yan Cheng、Xiaohan Zhang、Ji Qi、Shiyu Huang、Bin Xu、Yuxia Dong、Ming Ding、Jie Tang},year={2024},eprint={2406.08035},archivePrefix ={arXiv},primaryClass={cs.CV}} 

