使用標籤傳播方法進行同義詞庫擴充的工具。它根據文本語料庫和現有同義詞庫產生擴展現有同義詞集的建議。該工具是在慕尼黑工業大學 (TUM) 的「商業資訊系統軟體工程 (sebis)」主席的碩士論文「稅法同義詞庫擴展的標籤傳播」期間開發的。
論文摘要。隨著數位化的興起,資訊檢索必須應對越來越多的數位化內容。法律內容提供者投入大量資金來建立特定領域的本體(例如同義詞庫),以檢索數量顯著增加的相關文件。自 2002 年以來,已經開發了許多標籤傳播方法,例如用於識別圖中相似節點的群組。標籤傳播是一系列基於圖的半監督式機器學習演算法。在本文中,我們將測試標籤傳播方法從稅法領域擴展同義詞庫的適用性。標籤傳播操作的圖是由詞嵌入建構的相似圖。我們從頭到尾涵蓋了整個過程,並進行了多項參數研究,以了解某些超參數對整體性能的影響。然後在手動研究中評估結果並與基準方法進行比較。
該工具是使用以下管道和過濾器架構實現的:
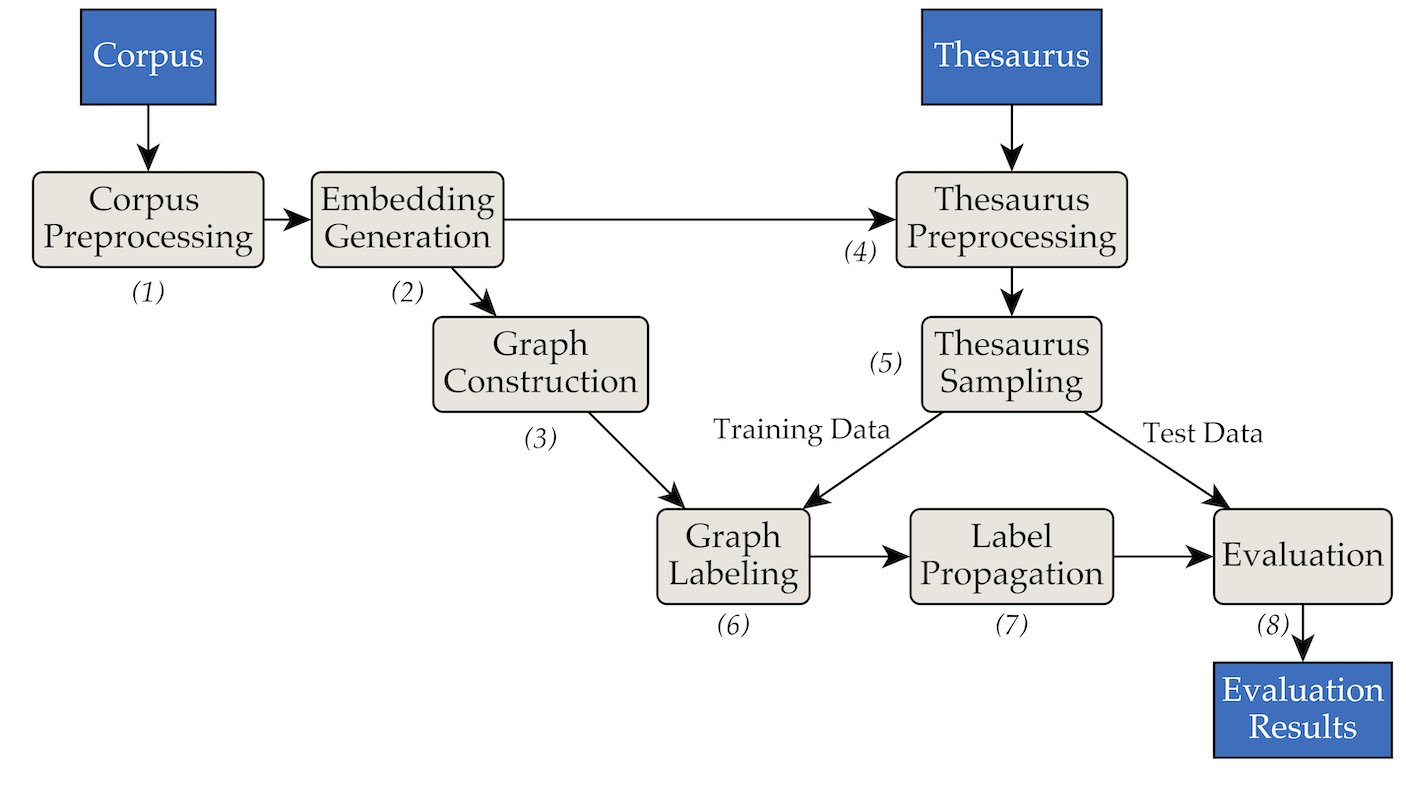
pipenv (安裝指南)。pipenv install安裝專案的要求。 data/RW40jsons中的一組文字語料庫檔案和data/german_relat_pretty-20180605.json中的同義詞庫。有關預期文件格式的信息,請參閱phase1.py 和phase4.py。output/<PHASE_FOLDER>/<DATE>中。最重要的是08_propagation_evaluation和XX_runs 。在08_propagation_evaluation中,評估統計資料儲存為stats.json以及包含預測、訓練和測試集的表( main.txt ,在其他腳本中最常稱為df_evaluation )。在XX_runs中,儲存了運行的日誌。如果透過 multi_runs.py 觸發多次運行(每次都有不同的訓練/測試集),則所有單獨運行的組合統計資料也會儲存為all_stats.json 。 透過purew2v_parameter_studies.py,我們在論文中引入的synset向量基線可以被執行。它需要一組詞嵌入和一個或多個同義詞庫訓練/測試分割。有關範例,請參閱sample_commands.md。
在ipynbs中,我們提供了一些示例性的 Jupyter 筆記本,用於產生 (a) 統計資料、(b) 圖表和 (c) 用於手動評估的 Excel 檔案。您可以透過執行pipenv shell然後使用jupyter notebook啟動 Jupyter 來探索它們。
main.py或multi_run.py時將建置路徑指定為參數。

