大語言模式課程
?在 X 上關注我•?擁抱臉•博客•?實踐 GNN
LLM課程分為三個部分:
- ? LLM 基礎涵蓋數學、Python 和神經網路的基本知識。
- ??法學碩士科學家專注於使用最新技術建立最好的法學碩士。
- ? LLM 工程師專注於創建基於 LLM 的應用程式並部署它們。
對於本課程的互動版本,我創建了兩名法學碩士助理,他們將以個性化的方式回答問題並測試您的知識:
- ? HuggingChat Assistant :使用 Mixtral-8x7B 的免費版本。
- ? ChatGPT 助理:需要高級帳戶。
筆記型電腦
與大型語言模型相關的筆記本和文章清單。
工具
| 筆記本 | 描述 | 筆記本 |
|---|
| ? LLM自動評估 | 使用 RunPod 自動評估您的法學碩士 | |
| ?惰性合併工具包 | 使用 MergeKit 一鍵輕鬆合併模型。 | |
| ?懶惰蠑螈 | 使用 Axolotl 一鍵微調雲中的模型。 | |
| ⚡ 自動定量 | 一鍵量化 GGUF、GPTQ、EXL2、AWQ 和 HQQ 格式的 LLM。 | |
| ?模型家譜 | 可視化合併模型的家譜。 | |
| 零空間 | 使用免費的 ZeroGPU 自動建立 Gradio 聊天介面。 | |
微調
| 筆記本 | 描述 | 文章 | 筆記本 |
|---|
| 使用 QLoRA 微調 Llama 2 | 在 Google Colab 中監督微調 Llama 2 的逐步指南。 | 文章 | |
| 使用 Axolotl 微調 CodeLlama | 最先進的微調工具的端到端指南。 | 文章 | |
| 使用 QLoRA 微調 Mistral-7b | 與 TRL 一起在免費的 Google Colab 中監督微調 Mistral-7b。 | | |
| 使用 DPO 微調 Mistral-7b | 使用 DPO 提升監督微調模型的效能。 | 文章 | |
| 使用 ORPO 微調 Llama 3 | 使用 ORPO 在單級中進行更便宜、更快速的微調。 | 文章 | |
| 使用 Unsloth 微調 Llama 3.1 | Google Colab 中的超高效監督微調。 | 文章 | |
量化
| 筆記本 | 描述 | 文章 | 筆記本 |
|---|
| 量化簡介 | 使用 8 位元量化的大型語言模型最佳化。 | 文章 | |
| 使用 GPTQ 的 4 位量化 | 量化您自己的開源 LLM 以在消費性硬體上運行它們。 | 文章 | |
| 使用 GGUF 和 llama.cpp 進行量化 | 使用 llama.cpp 量化 Llama 2 模型並將 GGUF 版本上傳到 HF Hub。 | 文章 | |
| ExLlamaV2:運行 LLM 最快的函式庫 | 量化並執行 EXL2 模型並將其上傳至 HF Hub。 | 文章 | |
其他
| 筆記本 | 描述 | 文章 | 筆記本 |
|---|
| 大型語言模型中的解碼策略 | 從波束搜尋到核採樣的文本生成指南 | 文章 | |
| 使用知識圖改良 ChatGPT | 用知識圖增強 ChatGPT 的答案。 | 文章 | |
| 使用 MergeKit 合併法學碩士 | 輕鬆創建您自己的模型,無需 GPU! | 文章 | |
| 使用 MergeKit 建立 MoE | 將多個專家合併為一個單一的 FrankenMoE | 文章 | |
| 取消任何帶有刪除的法學碩士的審查 | 無需重新訓練即可微調 | 文章 | |
?法學碩士基礎知識
本節介紹數學、Python 和神經網路的基本知識。您可能不想從這裡開始,但可以根據需要參考它。
切換部分
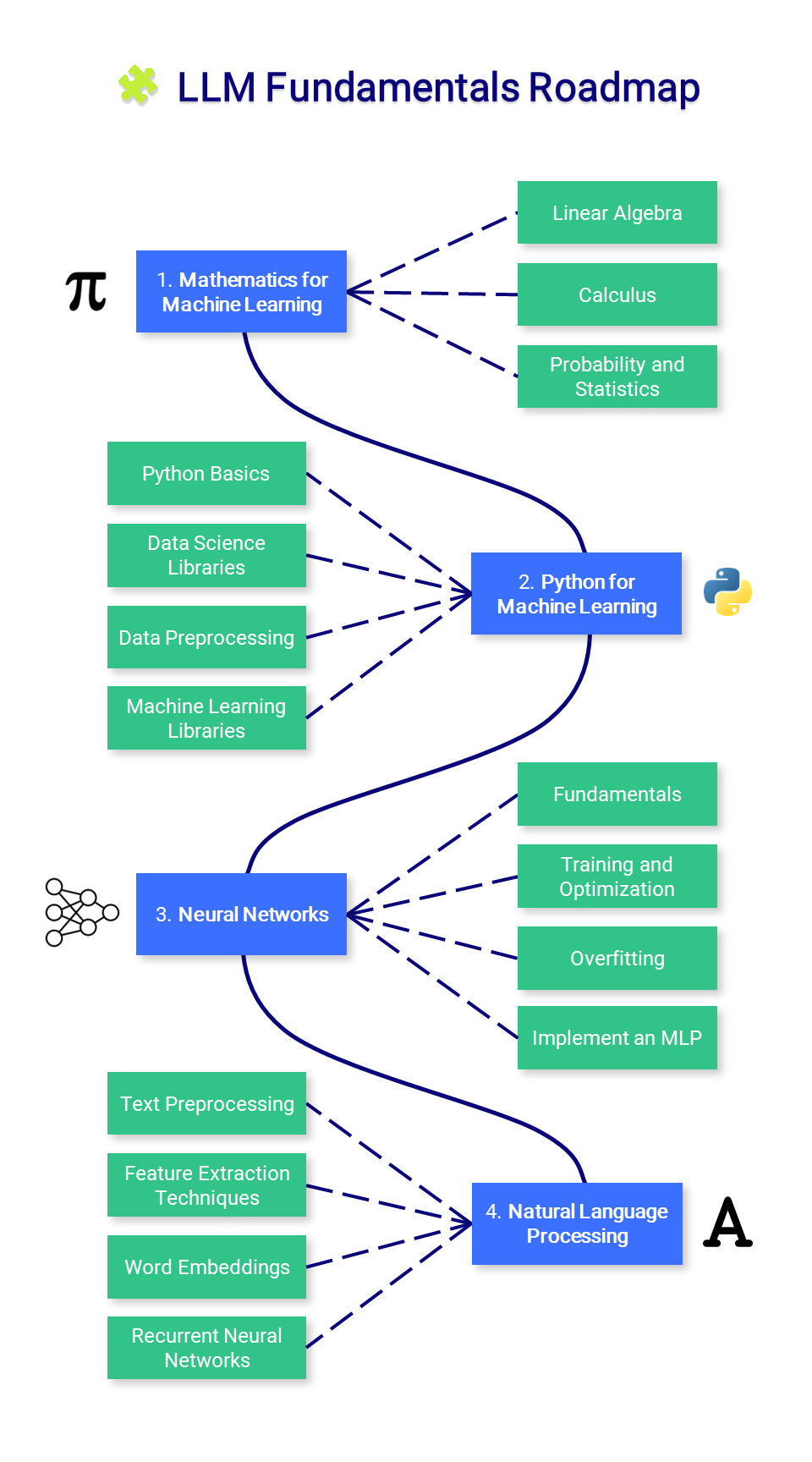
1. 機器學習數學
在掌握機器學習之前,了解支援這些演算法的基本數學概念非常重要。
- 線性代數:這對於理解許多演算法至關重要,尤其是深度學習中使用的演算法。關鍵概念包括向量、矩陣、行列式、特徵值和特徵向量、向量空間和線性變換。
- 微積分:許多機器學習演算法涉及連續函數的最佳化,這需要了解導數、積分、極限和級數。多變量微積分和梯度的概念也很重要。
- 機率和統計:這些對於理解模型如何從數據中學習並做出預測至關重要。關鍵概念包括機率論、隨機變數、機率分佈、期望、變異數、協方差、相關性、假設檢定、信賴區間、最大似然估計和貝葉斯推理。
資源:
- 3Blue1Brown - 線性代數的本質:一系列視頻,為這些概念提供了幾何直觀。
- StatQuest with Josh Starmer - 統計基礎知識:為許多統計概念提供簡單明了的解釋。
- Aerin 女士的 AP 統計直覺:提供每個機率分佈背後的直覺的中等文章清單。
- 沉浸式線性代數:線性代數的另一種視覺解釋。
- Khan Academy - 線性代數:非常適合初學者,因為它以非常直觀的方式解釋了概念。
- 可汗學院 - 微積分:一門涵蓋微積分所有基礎知識的互動課程。
- 可汗學院 - 機率與統計:以易於理解的格式提供材料。
2. 用於機器學習的Python
Python 是一種強大而靈活的程式語言,由於其可讀性、一致性和強大的資料科學庫生態系統,特別適合機器學習。
- Python基礎:Python程式設計需要很好地理解基本語法、資料類型、錯誤處理和物件導向程式設計。
- 資料科學函式庫:包括熟悉用於數值運算的 NumPy、用於資料操作和分析的 Pandas、用於資料視覺化的 Matplotlib 和 Seaborn。
- 資料預處理:這涉及特徵縮放和標準化、處理缺失資料、異常值檢測、分類資料編碼以及將資料拆分為訓練集、驗證集和測試集。
- 機器學習函式庫:熟練使用 Scikit-learn(一個提供多種監督和非監督學習演算法的函式庫)至關重要。了解如何實現線性迴歸、邏輯迴歸、決策樹、隨機森林、k 最近鄰 (K-NN) 和 K 均值聚類等演算法非常重要。 PCA 和 t-SNE 等降維技術也有助於視覺化高維度資料。
資源:
- Real Python:綜合資源,包含初學者和進階 Python 概念的文章和教學。
- freeCodeCamp - 學習 Python:長視頻,完整介紹了 Python 中的所有核心概念。
- Python 資料科學手冊:免費的數位書籍,是學習 pandas、NumPy、Matplotlib 和 Seaborn 的絕佳資源。
- freeCodeCamp - 適合所有人的機器學習:初學者的不同機器學習演算法的實用介紹。
- Udacity - 機器學習簡介:免費課程,涵蓋 PCA 和其他幾個機器學習概念。
3. 神經網絡
神經網路是許多機器學習模型的基本組成部分,特別是在深度學習領域。為了有效地利用它們,全面了解它們的設計和機制至關重要。
- 基礎知識:這包括理解神經網路的結構,例如層、權重、偏差和激活函數(sigmoid、tanh、ReLU 等)
- 訓練與最佳化:熟悉反向傳播和不同類型的損失函數,例如均方誤差 (MSE) 和交叉熵。了解各種最佳化演算法,例如梯度下降、隨機梯度下降、RMSprop 和 Adam。
- 過度擬合:了解過度擬合的概念(模型在訓練資料上表現良好,但在未見過的資料上表現不佳)並學習各種正則化技術(dropout、L1/L2 正則化、提前停止、資料增強)來防止過度擬合。
- 實作多層感知器 (MLP) :使用 PyTorch 建構 MLP,也稱為全連接網路。
資源:
- 3Blue1Brown - 但什麼是神經網路? :該影片直觀地解釋了神經網路及其內部工作原理。
- freeCodeCamp - 深度學習速成課程:影片有效地介紹了深度學習中所有最重要的概念。
- Fast.ai - 實用深度學習:為具有程式設計經驗、想要了解深度學習的人設計的免費課程。
- Patrick Loeber - PyTorch 教學:為初學者學習 PyTorch 的系列影片。
4.自然語言處理(NLP)
NLP 是人工智慧的一個令人著迷的分支,它彌合了人類語言和機器理解之間的差距。從簡單的文字處理到理解語言的細微差別,NLP 在翻譯、情緒分析、聊天機器人等許多應用中發揮著至關重要的作用。
- 文字預處理:學習各種文字預處理步驟,例如分詞(將文字分割成單字或句子)、詞幹擷取(將單字還原為其詞根形式)、詞形還原(與詞幹擷取類似,但考慮上下文)、停用詞刪除等。
- 特徵提取技術:熟悉將文字資料轉換為機器學習演算法可以理解的格式的技術。主要方法包括詞袋 (BoW)、詞頻-逆文檔頻率 (TF-IDF) 和 n-gram。
- 詞嵌入:詞嵌入是一種詞表示形式,允許具有相似意義的詞具有相似的表示形式。主要方法包括 Word2Vec、GloVe 和 FastText。
- 遞歸神經網路 (RNN) :了解 RNN 的工作原理,RNN 是一種設計用於處理序列資料的神經網路。探索 LSTM 和 GRU,這兩種能夠學習長期依賴關係的 RNN 變體。
資源:
- RealPython - NLP with spaCy in Python:有關 Python 中用於 NLP 任務的 spaCy 函式庫的詳細指南。
- Kaggle - NLP 指南:一些筆記本和資源,用於對 Python 中的 NLP 進行實際解釋。
- Jay Alammar - Word2Vec 插圖:了解著名的 Word2Vec 架構的一個很好的參考。
- Jake Tae - PyTorch RNN from Scratch:在 PyTorch 中實用且簡單地實作 RNN、LSTM 和 GRU 模型。
- colah 的部落格 - Understanding LSTM Networks:一篇關於 LSTM 網路更具理論性的文章。
??法學碩士科學家
本課程的這一部分重點在於學習如何使用最新技術來建立最好的法學碩士。
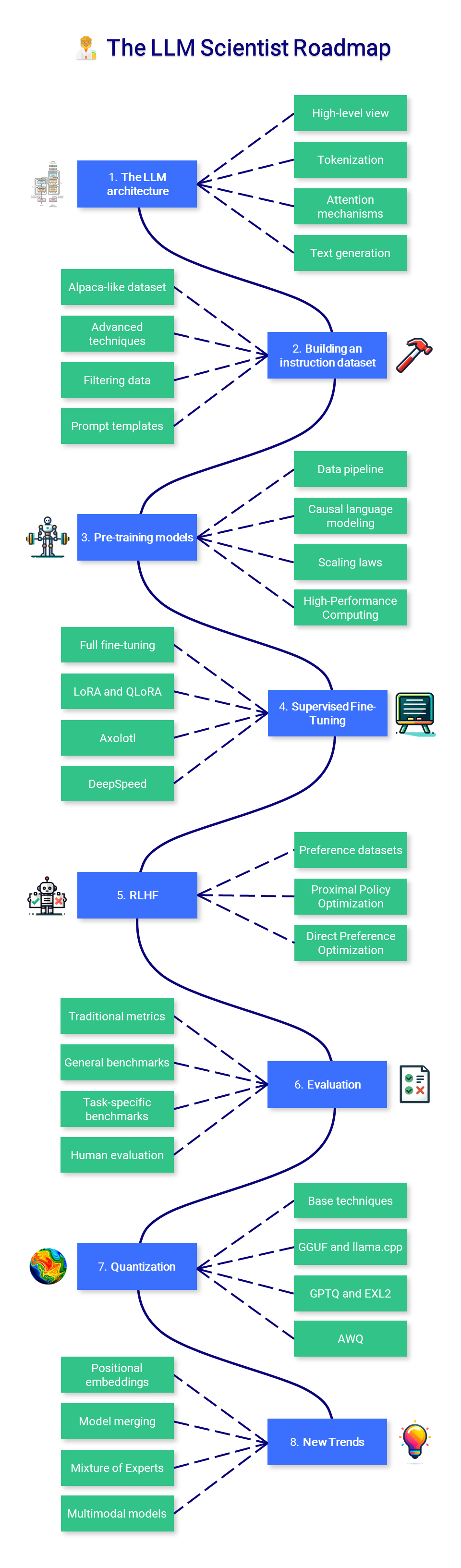
1. 法學碩士架構
雖然不需要深入了解 Transformer 架構,但深入了解其輸入(令牌)和輸出(logits)非常重要。普通的注意力機制是另一個需要掌握的關鍵組成部分,稍後會介紹它的改進版本。
- 進階視圖:重新審視編碼器-解碼器 Transformer 架構,更具體地說,是僅解碼器的 GPT 架構,該架構在每個現代 LLM 中都使用。
- 標記化:了解如何將原始文字資料轉換為模型可以理解的格式,這涉及將文字拆分為標記(通常是單字或子單字)。
- 注意力機制:掌握注意力機制背後的理論,包括自註意力和縮放點積注意力,這使得模型在產生輸出時能夠專注於輸入的不同部分。
- 文字產生:了解模型產生輸出序列的不同方式。常見的策略包括貪婪解碼、波束搜尋、top-k 採樣和核採樣。
參考:
- Jay Alammar 繪製的 Transformer 插圖:Transformer 模型的直觀解釋。
- Jay Alammar 的 GPT-2 圖解:比上一篇文章更重要,它專注於 GPT 架構,與 Llama 非常相似。
- 3Blue1Brown 的《變形金剛》視覺介紹:簡單易懂的《變形金剛》視覺介紹
- Brendan Bycroft 的 LLM 視覺化:以令人難以置信的 3D 視覺化方式呈現 LLM 內部發生的情況。
- nanoGPT,作者:Andrej Karpathy:一段 2 小時長的 YouTube 視頻,用於從頭開始重新實現 GPT(針對程式設計師)。
- 注意力?注意力!作者:Lilian Weng:以更正式的方式介紹關注的必要性。
- 法學碩士中的解碼策略:提供代碼和對生成文本的不同解碼策略的直觀介紹。
2. 建構指令資料集
雖然從維基百科和其他網站找到原始資料很容易,但很難在野外收集成對的指令和答案。與傳統機器學習一樣,資料集的質量將直接影響模型的質量,這就是為什麼它可能是微調過程中最重要的組成部分。
- 類似 Alpaca 的資料集:使用 OpenAI API (GPT) 從頭開始產生合成資料。您可以指定種子和系統提示來建立多樣化的資料集。
- 進階技術:了解如何使用 Evol-Instruct 改進現有資料集,如何產生 Orca 和 phi-1 論文中的高品質合成資料。
- 過濾資料:傳統技術涉及正規表示式、刪除近似重複項、關注具有大量標記的答案等。
- 提示範本:沒有真正的標準方法來格式化說明和答案,這就是為什麼了解不同的聊天範本(例如 ChatML、Alpaca 等)很重要。
參考:
- 為指令調整準備資料集,作者:Thomas Capelle:探索 Alpaca 和 Alpaca-GPT4 資料集以及如何格式化它們。
- 產生臨床指導資料集 作者:Solano Todeschini:如何使用 GPT-4 建立綜合指導資料集的教程。
- 用於新聞分類的 GPT 3.5,作者:Kshitiz Sahay:使用 GPT 3.5 建立指令資料集來微調 Llama 2 的新聞分類。
- 用於微調 LLM 的資料集建立:包含一些過濾資料集和上傳結果的技術的筆記本。
- Matthew Carrigan 的聊天範本:Hugging Face 關於提示範本的頁面
3. 預訓練模型
預訓練是一個非常漫長且成本高昂的過程,這就是為什麼這不是本課程的重點。對預訓練期間發生的情況有一定程度的了解是很好的,但不需要實踐經驗。
- 資料管道:預訓練需要龐大的資料集(例如,Llama 2 使用 2 兆個標記進行訓練),需要將這些資料集過濾、標記化並與預先定義的詞彙進行整理。
- 因果語言建模:了解因果語言建模和屏蔽語言建模之間的區別,以及本例中使用的損失函數。為了進行高效的預訓練,請了解有關 Megatron-LM 或 gpt-neox 的更多資訊。
- 縮放法則:縮放法則根據模型大小、資料集大小和用於訓練的計算量描述預期的模型性能。
- 高效能運算:超出了本文的範圍,但如果您打算從頭開始創建自己的法學碩士(硬體、分散式工作負載等),那麼更多有關 HPC 的知識是基礎。
參考:
- LLMDataHub,作者:Junhao Zhu:用於預訓練、微調和 RLHF 的精選資料集清單。
- 透過 Hugging Face 從頭開始訓練因果語言模型:使用 Transformers 庫從頭開始預先訓練 GPT-2 模型。
- TinyLlama,作者:Zhang 等人:查看此項目,可以很好地了解 Llama 模型是如何從頭開始訓練的。
- Hugging Face 的因果語言建模:解釋因果語言建模和屏蔽語言建模之間的差異以及如何快速微調 DistilGPT-2 模型。
- 懷舊學者對 Chinchilla 的瘋狂暗示:討論縮放定律並解釋它們對法學碩士的一般意義。
- BigScience 的 BLOOM:概念頁面,描述如何建立 BLOOM 模型,其中包含有關工程部分和遇到的問題的大量有用資訊。
- Meta 的 OPT-175 日誌:研究日誌顯示出了什麼問題以及什麼是正確的。如果您計劃預先訓練非常大的語言模型(在本例中為 175B 參數),則非常有用。
- LLM 360:開源法學碩士框架,包含訓練和資料準備代碼、資料、指標和模型。
4. 監督微調
預訓練模型僅針對下一個標記預測任務進行訓練,這就是為什麼它們不是有用的助手。 SFT 允許您調整它們以回應指令。此外,它允許您根據任何資料(私人資料、GPT-4 無法看到的資料等)微調您的模型並使用它,而無需支付 OpenAI 等 API 的費用。
- 全微調:全微調是指訓練模型中的所有參數。這不是一種有效的技術,但它會產生稍微好一點的結果。
- LoRA :一種基於低階適配器的參數高效能技術(PEFT)。我們不訓練所有參數,而是只訓練這些適配器。
- QLoRA :另一個基於 LoRA 的 PEFT,它還將模型的權重量化為 4 位,並引入分頁優化器來管理記憶體峰值。將其與 Unsloth 結合使用,可以在免費的 Colab 筆記本上有效運作。
- Axolotl :一種用戶友好且功能強大的微調工具,用於許多最先進的開源模型。
- DeepSpeed :針對多 GPU 和多節點設定的 LLM 的高效預訓練和微調(在 Axolotl 中實現)。
參考:
- Alpin 的新手 LLM 訓練指南:概述微調 LLM 時要考慮的主要概念和參數。
- Sebastian Raschka 的 LoRA 見解:有關 LoRA 以及如何選擇最佳參數的實用見解。
- 微調您自己的 Llama 2 模型:有關如何使用 Hugging Face 庫微調 Llama 2 模型的實作教學。
- 填充大型語言模型作者:Benjamin Marie:為因果法學碩士填充訓練範例的最佳實踐
- LLM 微調初學者指南:有關如何使用 Axolotl 微調 CodeLlama 模型的教程。
5. 偏好調整
經過監督微調後,RLHF 是用來使 LLM 的答案與人類期望保持一致的一個步驟。這個想法是從人類(或人工)回饋中學習偏好,這可用於減少偏見、審查模型或使它們以更有用的方式行事。它比 SFT 更複雜,並且通常被視為可選的。
- 偏好資料集:這些資料集通常包含具有某種排名的多個答案,這使得它們比指令資料集更難產生。
- 近端策略最佳化:此演算法利用獎勵模型來預測給定文字是否被人類排名較高。然後使用該預測來最佳化 SFT 模型,並根據 KL 散度進行懲罰。
- 直接偏好優化:DPO 透過將其重新定義為分類問題來簡化流程。它使用參考模型而不是獎勵模型(無需訓練),並且只需要一個超參數,使其更加穩定和高效。
參考:
- Distilabel by Argilla:創建自己的資料集的優秀工具。它是專門為偏好資料集設計的,但也可以進行 SFT。
- Ayush Thakur 的《使用 RLHF 訓練法學碩士簡介》:解釋為什麼 RLHF 對於減少法學碩士的偏見和提高績效是可取的。
- Hugging Face 插圖 RLHF:RLHF 簡介,包括獎勵模型訓練和強化學習微調。
- 透過 Hugging Face 進行偏好調整 LLM:比較 DPO、IPO 和 KTO 演算法以執行偏好對齊。
- LLM 訓練:RLHF 及其替代方案,作者:Sebastian Rashcka:RLHF 流程和 RLAIF 等替代方案的概述。
- 使用 DPO 微調 Mistral-7b:使用 DPO 微調 Mistral-7b 模型並重現 NeuralHermes-2.5 的教學。
六、評價
評估法學碩士是管道中被低估的部分,既耗時又不可靠。您的下游任務應該決定您想要評估的內容,但請始終記住古德哈特定律:“當一項措施成為目標時,它就不再是一個好的措施。”
- 傳統指標:困惑度和 BLEU 分數等指標並不像以前那麼受歡迎,因為它們在大多數情況下都存在缺陷。了解它們以及何時應用它們仍然很重要。
- 通用基準:基於語言模型評估工具,開放 LLM 排行榜是通用 LLM(如 ChatGPT)的主要基準。還有其他流行的基準測試,如 BigBench、MT-Bench 等。
- 任務特定的基準:摘要、翻譯和問答等任務有專用的基準、指標,甚至子領域(醫學、金融等),例如用於生物醫學問答的 PubMedQA。
- 人工評價:最可靠的評價是使用者的接受率或人工的比較。除了聊天記錄之外,記錄使用者回饋(例如,使用 LangSmith)有助於識別潛在的改進領域。
參考:
- Hugging Face 的固定長度模型的困惑:使用 Transformer 庫實現它的程式碼的困惑概述。
- BLEU 風險自負,作者:Rachael Tatman:BLEU 分數及其許多問題的概述和範例。
- Chang 等人的法學碩士評估調查:關於評估內容、評估地點以及如何評估的綜合論文。
- lmsys 的 Chatbot Arena 排行榜:基於人類進行的比較的通用 LLM 的 Elo 評級。
7. 量化
量化是使用較低精度轉換模型權重(和活化)的過程。例如,使用 16 位元儲存的權重可以轉換為 4 位元表示。這項技術對於降低與法學碩士相關的計算和記憶體成本變得越來越重要。
- 基本技術:學習不同等級的精確度(FP32、FP16、INT8 等)以及如何使用 absmax 和零點技術執行簡單量化。
- GGUF 和 llama.cpp :llama.cpp 和 GGUF 格式最初設計為在 CPU 上運行,現已成為在消費級硬體上運行 LLM 的最受歡迎工具。
- GPTQ 和 EXL2 :GPTQ,更具體地說,EXL2 格式提供了令人難以置信的速度,但只能在 GPU 上運行。模型也需要很長時間才能量化。
- AWQ :這種新格式比 GPTQ 更準確(更低的複雜性),但使用更多的 VRAM,而且不一定更快。
參考:
- 量化簡介:量化概述、absmax 和零點量化以及 LLM.int8() 和程式碼。
- 使用 llama.cpp 量化 Llama 模型:如何使用 llama.cpp 和 GGUF 格式量化 Llama 2 模型的教學。
- 使用 GPTQ 進行 4 位元 LLM 量化:有關如何使用 GPTQ 演算法和 AutoGPTQ 來量化 LLM 的教學課程。
- ExLlamaV2:運行 LLM 最快的庫:有關如何使用 EXL2 格式量化 Mistral 模型並使用 ExLlamaV2 庫運行它的指南。
- 了解 FriendliAI 的活化感知權重量化:AWQ 技術及其優勢概述。
8. 新趨勢
- 位置嵌入:了解 LLM 如何編碼位置,尤其是 RoPE 等相對位置編碼方案。實現 YaRN(將注意力矩陣乘以溫度因子)或 ALiBi(基於標記距離的注意力懲罰)來擴展上下文長度。
- 模型合併:合併經過訓練的模型已成為創建高性能模型而無需任何微調的流行方式。流行的 mergekit 庫實現了最流行的合併方法,例如 SLERP、DARE 和 TIES。
- 專家混合:Mixtral 憑藉其出色的性能重新流行了 MoE 架構。同時,OSS 社群中出現了一種 FrankenMoE,它合併了 Phixtral 等模型,這是一種更便宜且高效能的選擇。
- 多模態模型:這些模型(如 CLIP、Stable Diffusion 或 LLaVA)使用統一的嵌入空間處理多種類型的輸入(文字、圖像、音訊等),從而解鎖文字到圖像等強大的應用程式。
參考:
- Extending the RoPE by EleutherAI:總結不同位置編碼技術的文章。
- Rajat Chawla 的《理解 YaRN》:YaRN 簡介。
- 使用 mergekit 合併 LLM:有關使用 mergekit 進行模型合併的教學課程。
- Hugging Face 解釋了專家的混合:關於 MoE 及其工作方式的詳盡指南。
- 大型多模態模型,作者:Chip Huyen:多模態系統概述和該領域的最新歷史。
?法學碩士工程師
本課程的這一部分重點是學習如何建立可在生產中使用的由 LLM 支援的應用程序,重點是增強模型和部署它們。
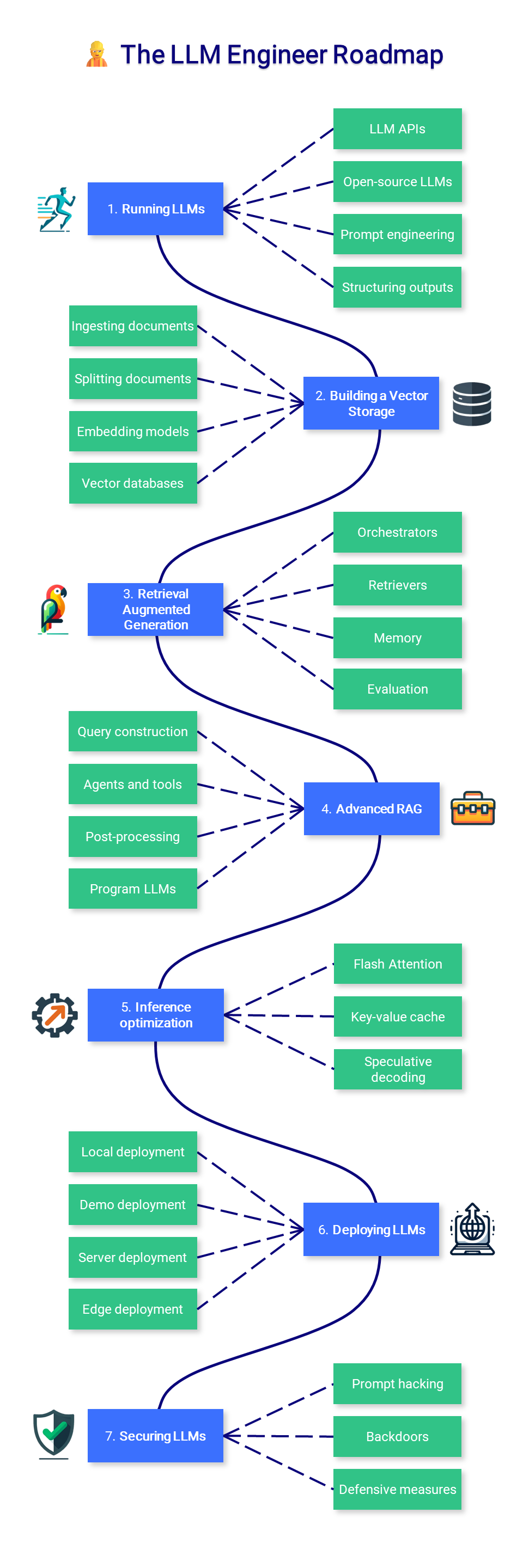
1. 運行法學碩士
由於硬體需求較高,運行法學碩士可能很困難。根據您的用例,您可能只想透過 API(如 GPT-4)使用模型或在本地運行它。無論如何,額外的提示和指導技術可以改進和限制應用程式的輸出。
- LLM API :API 是部署 LLM 的便利方法。這個空間分為私人法學碩士(OpenAI、Google、Anthropic、Cohere 等)和開源法學碩士(OpenRouter、Hugging Face、Together AI 等)。
- 開源法學碩士:Hugging Face Hub 是尋找法學碩士的好地方。您可以直接在 Hugging Face Spaces 中運行其中一些,或者在 LM Studio 等應用程式中本地下載並運行它們,或者透過 CLI 使用 llama.cpp 或 Ollama。
- 提示工程:常見技術包括零樣本提示、少樣本提示、思考鏈和 ReAct。它們與較大的模型配合得更好,但也可以適應較小的模型。
- 結構化輸出:許多任務需要結構化輸出,例如嚴格的範本或 JSON 格式。 LMQL、Outlines、Guidance 等函式庫可用於指導產生並尊重給定的結構。
參考:
- Nisha Arya 的使用 LM Studio 在本地運行法學碩士:有關如何使用 LM Studio 的簡短指南。
- DAIR.AI 的提示工程指南:帶有示例的提示技術的詳盡列表
- Outlines - 快速入門:Outlines 支援的引導生成技術清單。
- LMQL - 概述:LMQL 語言簡介。
2. 建構向量存儲
建立向量儲存是建立檢索增強生成 (RAG) 管道的第一步。載入、分割文檔,並使用相關區塊來產生向量表示(嵌入),並將其儲存起來以供將來在推理過程中使用。
- 擷取文件:文件載入器是方便的包裝器,可以處理多種格式:PDF、JSON、HTML、Markdown 等。
- 分割文件:文字分割器將文件分解為更小的、具有語意意義的區塊。與其在n 個字元後分割文本,不如按標題或遞歸方式分割文本,並使用一些附加元資料。
- 嵌入模型:嵌入模型將文字轉換為向量表示。它允許對語言有更深入、更細緻的理解,這對於執行語義搜尋至關重要。
- 向量資料庫:向量資料庫(如 Chroma、Pinecone、Milvus、FAISS、Annoy 等)旨在儲存嵌入向量。它們能夠根據向量相似性高效檢索與查詢「最相似」的資料。
參考:
- LangChain - 文字分割器:LangChain 中實作的不同文字分割器的清單。
- Sentence Transformers 庫:流行的嵌入模型庫。
- MTEB Leaderboard:嵌入模型的排行榜。
- Moez Ali 的前 5 個向量資料庫:最好和最受歡迎的向量資料庫的比較。
3. 檢索增強生成
借助 RAG,法學碩士可以從資料庫中檢索上下文文檔,以提高答案的準確性。 RAG 是一種無需任何微調即可增強模型知識的流行方法。
- Orchestrators :Orchestrators(如LangChain、LlamaIndex、FastRAG等)是流行的框架,用於將LLM與工具、資料庫、記憶體等連接起來並增強他們的能力。
- 檢索器:使用者指令未針對檢索進行最佳化。可以應用不同的技術(例如,多查詢檢索器、HyDE 等)來重新表達/擴展它們並提高效能。
- 記憶:為了記住先前的說明和答案,LLM 和 ChatGPT 等聊天機器人會將此歷史記錄加入其上下文視窗。此緩衝區可以透過匯總(例如,使用較小的 LLM)、向量儲存 + RAG 等來改進。
- 評估:我們需要評估文件檢索(上下文精確度和召回率)和生成階段(可信度和答案相關性)。可以使用 Ragas 和 DeepEval 工具來簡化。
參考:
- Llamaindex - 高級概念:建造 RAG 管道時需要了解的主要概念。
- Pinecone - 檢索增強:檢索增強流程概述。
- LangChain - RAG 問答:建立典型 RAG 管道的逐步教學。
- LangChain - 記憶體類型:不同類型記憶體及其相關用途的清單。
- RAG 管道 - 指標:用於評估 RAG 管道的主要指標的概述。
4.高級RAG
現實應用程式可能需要複雜的管道,包括 SQL 或圖形資料庫,以及自動選擇相關工具和 API。這些先進技術可以改進基準解決方案並提供附加功能。
- 查詢建構:傳統資料庫中儲存的結構化資料需要特定的查詢語言,如SQL、Cypher、元資料等。
- 代理與工具:代理人透過自動選擇最相關的工具來提供答案來增強法學碩士。這些工具可以像使用 Google 或 Wikipedia 一樣簡單,也可以像 Python 解釋器或 Jira 一樣複雜。
- 後處理:處理輸入到 LLM 的輸入的最後一步。它透過重新排序、RAG 融合和分類增強了檢索到的文件的相關性和多樣性。
- 程序法學碩士:DSPy 等框架可讓您以程式設計方式基於自動評估來優化提示和權重。
參考:
- LangChain - 查詢建構:關於不同類型的查詢建構的部落格文章。
- LangChain - SQL:關於如何使用 LLM 與 SQL 資料庫互動的教學課程,涉及文字到 SQL 和可選的 SQL 代理程式。
- Pinecone - LLM代理:不同類型代理和工具的介紹。
- Lilian Weng 的 LLM Powered Autonomous Agents:有關 LLM 代理的更多理論文章。
- LangChain - OpenAI 的 RAG:OpenAI 採用的 RAG 策略概述,包括後處理。
- DSPy 的 8 個步驟:DSPy 通用指南,介紹模組、簽章和最佳化器。
5. 推理優化
文字生成是一個成本高昂的過程,需要昂貴的硬體。除了量化之外,還提出了各種技術來最大化吞吐量並降低推理成本。
- Flash Attention :優化注意力機制,將其複雜度從二次型轉變為線性型,加速訓練和推理速度。
- 鍵值快取:了解鍵值快取以及多查詢注意(MQA)和分組查詢注意(GQA)中引入的改進。
- 推測性解碼:使用小型模型產生草稿,然後由較大模型進行審查以加快文字產生速度。
參考:
- GPU Inference by Hugging Face:說明如何優化 GPU 上的推理。
- Databricks 的 LLM 推理:如何在生產中優化 LLM 推理的最佳實踐。
- Optimizing LLMs for Speed and Memory by Hugging Face:解釋最佳化速度和記憶體的三種主要技術,即量化、Flash Attention 和架構創新。
- Assisted Generation by Hugging Face:HF 版本的推測解碼,這是一篇有趣的部落格文章,介紹了它如何使用程式碼來實現。
6. 部署法學碩士
大規模部署 LLM 是一項工程壯舉,可能需要多個 GPU 叢集。在其他場景中,可以以低得多的複雜度來實現演示和本地應用程式。
- 本地部署:隱私權是開源 LLM 相對於私有 LLM 的一個重要優勢。本地 LLM 伺服器(LM Studio、Ollama、oobabooga、kobold.cpp 等)利用此優勢來支援本機應用程式。
- 演示部署:Gradio 和 Streamlit 等框架有助於建立應用程式原型並共享演示。您也可以輕鬆地在線上託管它們,例如使用 Hugging Face Spaces。
- 伺服器部署:大規模部署 LLM 需要雲端(另請參閱 SkyPilot)或本地基礎設施,並且通常利用最佳化的文字產生框架,如 TGI、vLLM 等。
- 邊緣部署:在受限環境中,MLC LLM 和 mnn-llm 等高效能框架可以在 Web 瀏覽器、Android 和 iOS 中部署 LLM。
參考:
- Streamlit - 建立基本的 LLM 應用程式:使用 Streamlit 製作基本的類似 ChatGPT 的應用程式的教學。
- HF LLM 推理容器:使用 Hugging Face 的推理容器在 Amazon SageMaker 上部署 LLM。
- Philschmid 博客,作者:Philipp Schmid:有關使用 Amazon SageMaker 部署 LLM 的高品質文章集合。
- 優化延遲,作者:Hamel Husain:TGI、vLLM、CTranslate2 和 mlc 在吞吐量和延遲方面的比較。
7. 確保法學碩士
除了與軟體相關的傳統安全問題之外,法學碩士由於其培訓和提示方式而具有獨特的弱點。
- 提示駭客:與提示工程相關的不同技術,包括提示注入(劫持模型答案的附加指令)、資料/提示洩漏(檢索其原始資料/提示)和越獄(製作提示以繞過安全功能)。
- 後門:攻擊向量可以透過毒害訓練資料(例如,使用虛假資訊)或建立後門(在推理過程中改變模型行為的秘密觸發器)來針對訓練資料本身。
- 防禦措施:保護您的 LLM 應用程式的最佳方法是針對這些漏洞進行測試(例如,使用紅隊和像 garak 這樣的檢查)並在生產中觀察它們(使用像 langfuse 這樣的框架)。
參考:
- HEGO Wiki 的 OWASP LLM Top 10:LLM 應用程式中發現的 10 個最嚴重漏洞的清單。
- Joseph Thacker 的《Prompt Injection Primer》:專為工程師提供的快速注入簡短指南。
- LLM Security by @llm_sec:與 LLM 安全性相關的廣泛資源清單。
- Microsoft 的紅隊法學碩士:有關如何與法學碩士進行紅隊合作的指南。
致謝
路線圖的靈感來自 Milan Milanović 和 Romano Roth 的優秀 DevOps 路線圖。
特別鳴謝:
- Thomas Thelen 激勵我制定路線圖
- André Frade 對初稿的貢獻與審查
- Dino Dunn 提供有關 LLM 安全性的資源
- Magdalena Kuhn 改進了「人類評估」部分
- Odoverdose 推薦 3Blue1Brown 有關變形金剛的視頻
免責聲明:我不隸屬於此處列出的任何來源。


