鄒陽、Jongheon Jeong、Latha Pemula、張冬青、Onkar Dabeer。
該儲存庫包含我們的 ECCV-2022 論文「SPot-the-Difference Self-Supervised Pre-training for Anomaly Inspection and Segmentation」的資源。目前我們發布了視覺異常(VisA)資料集。
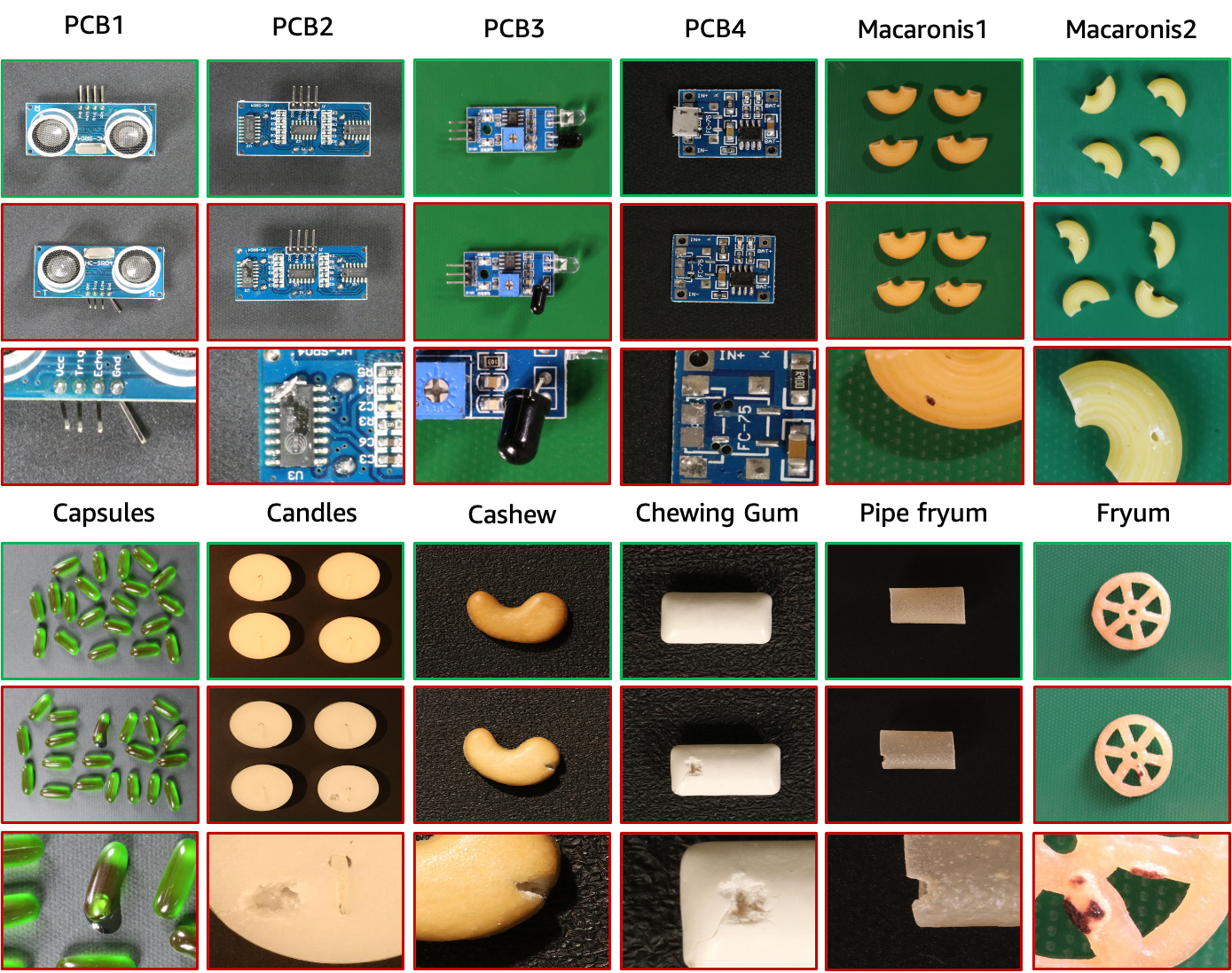
VisA資料集包含12個子集,對應12個不同的對象,如上圖所示。有 10,821 張圖像,其中 9,621 個正常樣本和 1,200 個異常樣本。四個子集是不同類型的印刷電路板(PCB),其結構相對複雜,包含電晶體、電容器、晶片等。 Capsules 和 Macaroni2 中的實例在位置和姿勢上有很大不同。此外,我們收集了四個子集,包括腰果、口香糖、薯條和管道炸薯條,其中物件大致對齊。異常影像包含各種缺陷,包括刮痕、凹痕、色斑或裂縫等表面缺陷,以及錯位或缺失零件等結構缺陷。
| 目的 | # 正常樣本 | # 異常樣本 | # 異常類 | 物件類型 |
|---|---|---|---|---|
| 印刷電路板1 | 1,004 | 100 | 4 | 結構複雜 |
| PCB2 | 1,001 | 100 | 4 | 結構複雜 |
| PCB3 | 1,006 | 100 | 4 | 結構複雜 |
| PCB4 | 1,005 | 100 | 7 | 結構複雜 |
| 膠囊 | 602 | 100 | 5 | 多個實例 |
| 蠟燭 | 1,000 | 100 | 8 | 多個實例 |
| 通心粉1 | 1,000 | 100 | 7 | 多個實例 |
| 通心粉2 | 1,000 | 100 | 7 | 多個實例 |
| 腰果 | 500 | 100 | 9 | 單一實例 |
| 口香糖 | 503 | 100 | 6 | 單一實例 |
| 弗留姆 | 500 | 100 | 8 | 單一實例 |
| 管道弗里姆 | 500 | 100 | 9 | 單一實例 |
我們將 VisA 資料集託管在 AWS S3 中,您可以透過此 URL 下載它。
下載資料的資料樹如下。
VisA
| -- candle
| ----- | --- Data
| ----- | ----- | ----- Images
| ----- | ----- | -------- | ------ Anomaly
| ----- | ----- | -------- | ------ Normal
| ----- | ----- | ----- Masks
| ----- | ----- | -------- | ------ Anomaly
| ----- | --- image_anno.csv
| -- capsules
| ----- | ----- ...image_annot.csv 為每個影像提供影像級標籤和像素級註解遮罩。多類別遮罩的 id2class 映射函數可以在 ./utils/id2class.py 中找到,這裡不儲存普通影像的遮罩以節省空間。
為了準備原始論文中描述的 1-class、2-class-highshot、2-class-fewshot 設置,我們使用 ./utils/prepare_data.py 按照「./split_csv/」中的資料分割檔案重新組織資料。我們給出了用於 1 級設定準備的範例命令列,如下所示。
python ./utils/prepare_data.py --split-type 1cls --data-folder ./VisA --save-folder ./VisA_pytorch --split-file ./split_csv/1cls.csv
重組後的1級設定的資料樹如下。
VisA_pytorch
| -- 1cls
| ----- | --- candle
| ----- | ----- | ----- ground_truth
| ----- | ----- | ----- test
| ----- | ----- | ------- | ------- good
| ----- | ----- | ------- | ------- bad
| ----- | ----- | ----- train
| ----- | ----- | ------- | ------- good
| ----- | --- capsules
| ----- | --- ...具體來說,1 級設定的重組資料遵循 MVTec-AD 的資料樹。對於每個對象,資料具有三個資料夾:
請注意,原始資料集中的多類真實分割遮罩被重新索引為二進位遮罩,其中 0 表示正常,255 表示異常。
此外,可以透過更改prepare_data.py 的參數以類似的方式準備2 類設定。
要計算分類和分段指標,請參閱./utils/metrics.py。請注意,我們在計算本地化指標時考慮了正常樣本。這與其他一些忽略本地化正常樣本的作品不同。
如果該資料集對您的專案有幫助,請引用以下論文:
@article { zou2022spot ,
title = { SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation } ,
author = { Zou, Yang and Jeong, Jongheon and Pemula, Latha and Zhang, Dongqing and Dabeer, Onkar } ,
journal = { arXiv preprint arXiv:2207.14315 } ,
year = { 2022 }
}數據在 CC BY 4.0 許可下發布。


