我經常使用同義詞庫,無論是在編寫文件和自述文件的副本時,還是在編寫命名變數和函數的程式碼時。
我曾經使用線上同義詞庫,尤其是 thesaurus.com,但我討厭這種體驗。儘管結果很有用且組織得很好,但它們對鍵盤不友善且導航速度很慢,尤其是當結果擴展到許多頁面時。
所以我製作了自己的同義詞庫。我使用它的次數比使用 thesaurus.com 的次數還要多。它的功能較少,但訪問速度要快得多,並且對創作過程的干擾較小。
在終端機視窗中,鍵入th後面跟著一個單字。例如,要查找單字「注意力」 :
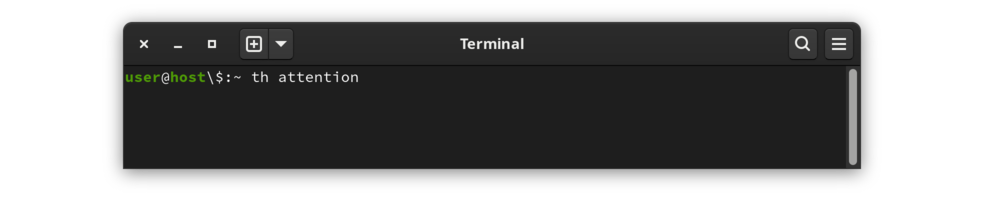 |
|---|
調用th來引起注意 |
輸出是相關單字和短語的列表,組織成列,上面和下面有上下文行,底部有導航選項列表。
 |
|---|
| 關注搜尋結果 |
結果顯示的底行顯示可用操作的清單。透過鍵入操作的第一個字母來啟動操作(在螢幕上突出顯示以進行強調)。
資料被組織為同義詞庫條目,每個詞庫條目都有相關單字和短語的集合。詞條是主幹,相關的字、片語是枝。
預設視圖處於分支模式。顯示的單字是來源同義詞庫中條目後列出的單字和片語。切換到中繼模式將顯示包含該單字的條目。沒有任何分支的例子最清楚地證明了這一點:
 |
|---|
| 觸發器是一個沒有條目的單字 |
沒有單字trigger的同義詞庫條目。然而, 「觸發器」一詞在同義詞庫中作為其他條目的分支。切換到中繼模式以查看包含觸發器的條目:
 |
|---|
| 觸發器是相關詞的單字列表 |
該程式不作為軟體包提供;必須下載原始程式碼並建置專案。以下步驟將產生一個工作同義詞庫:
git clone https://www.github.com/cjungmann/th.gitcd thmakemake thesaurus.db嘗試一下該程序,看看您是否喜歡它。如果您想將其安裝為在建置目錄之外可用,請呼叫以下命令:
sudo make install
如果您決定不需要該程序,則可以輕鬆刪除該程序。
如果您已經安裝了程序,請先使用sudo make uninstall卸載
這將刪除程式、支援檔案以及安裝支援檔案的目錄。
如果未安裝該程序,您可以安全地刪除克隆的目錄。
以下材料主要會讓開發人員(如果有的話)感興趣。
該項目很容易構建,但依賴其他軟體。以下是依賴項列表,其中只有第一個(伯克利資料庫)可能需要一些幹預。下面的第 3 項和第 4 項被下載到建置目錄下的子目錄中,並且在那裡找到的程式碼靜態連結到可執行文件,因此它們不會影響您的環境。
db 版本 5 (伯克利資料庫)對於專案中的 B 樹資料庫是必要的。如果你使用git ,你應該已經有了這個,即使在FreeBSD上,否則它只包含舊版的db 。如果 Make 找不到合適的db ,它會立即終止並顯示一則訊息,在這種情況下,您可以使用套件管理器來安裝db或從來源建置它。
git用於下載一些相依性。雖然可以在不使用git 的情況下直接下載專案依賴項,但這樣做需要有關來源檔案的未記錄的知識,而當make可以使用git下載依賴項時,可以避免這個問題。
readargs 是我處理命令列參數的項目之一。雖然th仍在使用此項目,但th不再需要安裝此庫即可工作。現在,第一個Makefile 將readargs專案下載到子目錄中,建立它並使用靜態庫。
c_patterns 是我的另一個項目,是一個在不需要函式庫的情況下管理可重複使用程式碼的實驗。 Makefile 使用git下載項目,然後連結到src目錄中的一些 c_patterns 模組,以包含在建置中。
這個項目雖然有用(至少對我來說),但也是一個實驗。我的目標之一是提高我的 makefile 編寫技巧。我做出的一些建置和安裝決策可能不是最佳實踐,甚至可能會被更有經驗的開發人員所反對。如果您擔心th後會對您的系統產生什麼影響,我希望以下內容能幫助您做出決定。
正如預期的那樣, make將編譯第一個應用程式。與以往不同的是, make可能會執行其他可能需要一些時間的任務:
下載我的 C 模組儲存庫,並透過連結到src目錄來使用其中的幾個模組。
如果makefile偵測到缺少依賴項,它會識別並立即終止並顯示有用的訊息,而不是使用configure來檢查依賴項。
從古騰堡計畫下載並導入公共領域莫比同義詞庫。這將填充應用程式的單字資料庫。
已放棄下載並匯入字數統計資料庫。這個想法是提供替代的排序順序,以便更輕鬆地從較長的列表中找到單字。現在這不起作用。我不確定我是否會回到這個主題,因為我發現閱讀字母清單的好處遠遠超過嘗試將更常用的單字放在第一位的可疑好處。原因是,當所考慮的單字不是隨機分散在一長串單字中時,追蹤它們會更容易。
我剛剛注意到有一個 Moby 詞性列表資源可以幫助組織輸出。這很有趣,但根據字母排序對使用輸出的幫助程度,我不確定它是否會有幫助。我們拭目以待。
當我開始這個專案時,我有幾個目標。
我想要更多使用伯克利資料庫的經驗。這個密鑰儲存資料庫支撐著許多其他應用程序,包括git和sqlite 。
我想練習使用我的一些 c_patterns 專案模組。在實際專案中使用這些模組可以幫助我了解它們的設計缺陷和缺少的功能。我用
columnize.c產生柱狀輸出,
提示器.c用於輸出底部的最小選項選單,
get_keypress.c用於非回顯按鍵,主要由提示器.c使用。
我想練習設計一個可以在 Gnu Linux 和 BSD 中運行的建置過程。這包括識別缺少的模組(特別是db ,其中 BSD 包含一個太舊的庫),以及重新設計的條件處理。
我不是針對 Windows,因為它與 Linux 的差異比 BSD 更大,而且我不認為許多 Windows 用戶會願意使用命令列應用程式。
伯克利資料庫( bdb )似乎是一個有趣的資料庫產品。它的低階 C 函式庫方法看起來類似於我在 20 世紀 90 年代末使用的 FairCom DB 引擎。
Berkeley 資料庫很有吸引力,因為它是 Linux 和 BSD 發行版的一部分,而且佔用空間很小。它獎勵了對數據的詳細規劃,也是探索我的一些C語言想法的藉口。
這個專案是我的單字專案的重新啟動,該專案旨在成為一個命令列同義詞庫和字典。那個專案是我第一次使用bdb ,所以我的一些工作有點笨拙。我想從頭開始重新設計bdb程式碼。我將從單字專案複製一些適用於此處的文字解析程式碼。
使用同義詞庫和字典等大型資料集,我還想測試 Queue 和 Recno 資料存取方法之間的效能差異。我預計隊列會更快,因為可以計算固定長度記錄的開頭和結尾。透過給定可變長度記錄的記錄號進行存取將需要查找檔案位置。我想測量效能差異,以權衡該優勢與可變長度記錄的儲存效率。
同義詞庫有兩個公共領域來源:
我使用 Moby 同義詞庫,因為它的組織更簡單,因此更容易解析。問題在於同義詞數量眾多,而且缺乏組織,在搜尋合適的同義詞時更難掃描。
由於許多單字有數百個同義詞,因此很難掃描清單來找到合適的單字。我將嘗試對列表進行一些排序以使其更易於使用。使用該工具一段時間後,我得出的結論是按字母順序排列是最好的。返回字母列表中的單字要容易得多。我刪除了選擇其他詞序的選項。
最簡單的分類是單字使用頻率。我打算按照使用頻率最高到最低的順序列出單字。據推測,更流行的詞可能是最好的選擇,而不太流行的詞可能是過時的。
詞頻有多種來源。我使用的是基於 Google ngrams 的:
自然語言語料庫數據:美麗的數據
我還沒有真正研究過 Norvig 的源碼,所以它可能有很多廢話。還有另一個來源可能有更乾淨的列表,hackerb9/gwordlist。如果 Norvig 是一個問題,我想記住這個備用列表,我可以用它來替換它。
這部分不再嘗試。由於需要識別字典的獨特符號並將其轉換為 unicode 字符,解釋來源資料變得很複雜。我解決了其中許多問題,但仍有許多問題仍然存在。 Makefile 仍然包含下載此資訊的說明,並且儲存庫保留了一些轉換腳本,以備我想返回時使用。
按詞性(即名詞、動詞、形容詞等)將同義詞分組也可能很有用。第一個問題是辨識每個單字所代表的詞性。第二個問題是在演示中:如果有一個介面讓使用者在顯示單字之前選擇詞性,那就更好了,但更難編程。
電子公共領域詞典
我的第一次嘗試是使用 GNU 協作國際英語字典 (GCIDE)。它基於韋氏字典的舊版本(1914 年),並由更現代的編輯添加了一些文字。


