

MPIRE是 MultiProcessing Is Very Easy 的縮寫,是一個用於多處理的 Python 套件。 MPIRE在大多數情況下速度更快,包含更多功能,並且通常比預設的多處理包更用戶友好。它結合了multiprocessing.Pool的便利映射功能和使用multiprocessing.Process的寫時複製共享物件的優點,以及易於使用的工作狀態、工作洞察、工作初始化和退出函數、超時和進度條功能。
完整文件可在 https://sybrenjansen.github.io/mpire/ 取得。
map / map_unordered / imap / imap_unordered / apply / apply_async函數進行多處理fork )rich和筆記本小工具)daemon選項時允許巢狀工作池MPIRE 在 Linux、macOS 和 Windows 上進行了測試。對於 Windows 和 macOS 用戶,有一些已知的小警告,這些警告記錄在「故障排除」一章中。
通過點(PyPi):
pip install mpireMPIRE 也可以透過 conda-forge 獲得:
conda install -c conda-forge mpire假設您有一個耗時的函數,它接收一些輸入並傳回其結果。像這樣的簡單函數被稱為“令人尷尬的平行問題”,這些函數幾乎不需要甚至不需要任何努力就可以變成平行任務。並行化一個簡單的函數就像導入multiprocessing並使用multiprocessing.Pool類別一樣簡單:
import time
from multiprocessing import Pool
def time_consuming_function ( x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
with Pool ( processes = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) MPIRE 幾乎可以用作multiprocessing的直接替代品。我們使用mpire.WorkerPool類別並呼叫可用的map函數之一:
from mpire import WorkerPool
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ))程式碼中的差異很小:如果您習慣了普通的multiprocessing ,則無需學習全新的多處理語法。不過,額外的可用功能才是 MPIRE 的與眾不同之處。
假設我們想知道目前任務的狀態:完成了多少個任務,距離工作準備就緒還有多久?就像將progress_bar參數設定為True一樣簡單:
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )它會輸出一個格式良好的 tqdm 進度條。
MPIRE 還提供了一個儀表板,您需要為其安裝額外的依賴項。請參閱儀表板以了解更多資訊。
注意:寫入時複製共享物件僅適用於 start 方法fork 。對於threading物件按原樣共享。對於其他啟動方法,共用物件為每個工作執行緒複製一次,這仍然比每個任務複製一次要好。
如果您想要在所有工作人員之間共用一個或多個對象,您可以使用 MPIRE 的寫入時複製shared_objects選項。 MPIRE 只會為每位工作人員傳遞這些物件一次,而無需複製/序列化。只有當您變更輔助函數中的物件時,它才會開始為該輔助函數複製該物件。
def time_consuming_function ( some_object , x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
def main ():
some_object = ...
with WorkerPool ( n_jobs = 5 , shared_objects = some_object ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )有關更多詳細信息,請參閱共享對象。
可以使用worker_init功能來初始化worker。與worker_state一起,您可以載入模型,或設定資料庫連線等:
def init ( worker_state ):
# Load a big dataset or model and store it in a worker specific worker_state
worker_state [ 'dataset' ] = ...
worker_state [ 'model' ] = ...
def task ( worker_state , idx ):
# Let the model predict a specific instance of the dataset
return worker_state [ 'model' ]. predict ( worker_state [ 'dataset' ][ idx ])
with WorkerPool ( n_jobs = 5 , use_worker_state = True ) as pool :
results = pool . map ( task , range ( 10 ), worker_init = init )同樣,您可以使用worker_exit功能讓MPIRE在worker終止時呼叫函數。你甚至可以讓這個退出函數回傳結果,稍後可以獲得。有關更多信息,請參閱worker_init 和worker_exit 部分。
當您的多處理設定未按您希望的方式運行並且您不知道原因是什麼時,可以使用工作人員洞察功能。這將使您深入了解您的設置,但它不會分析您正在運行的函數(還有其他庫)。相反,它會記錄工作人員的啟動時間、等待時間和工作時間。當提供了工作進程初始化和退出函數時,它也會對這些函數進行計時。
也許您正在透過任務佇列發送大量數據,這會導致等待時間增加。無論哪種情況,您都可以分別使用enable_insights標誌和mpire.WorkerPool.get_insights函數啟用並取得見解:
with WorkerPool ( n_jobs = 5 , enable_insights = True ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ))
insights = pool . get_insights ()請參閱工作人員見解以取得更詳細的範例和預期輸出。
可以為目標、 worker_init和worker_exit函數單獨設定逾時。當設定並達到超時時,它將拋出TimeoutError :
def init ():
...
def exit_ ():
...
# Will raise TimeoutError, provided that the target function takes longer
# than half a second to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), task_timeout = 0.5 )
# Will raise TimeoutError, provided that the worker_init function takes longer
# than 3 seconds to complete or the worker_exit function takes longer than
# 150.5 seconds to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), worker_init = init , worker_exit = exit_ ,
worker_init_timeout = 3.0 , worker_exit_timeout = 150.5 )當使用threading作為啟動方法時,MPIRE 將無法中斷某些函數,例如time.sleep 。
有關更多詳細信息,請參閱超時。
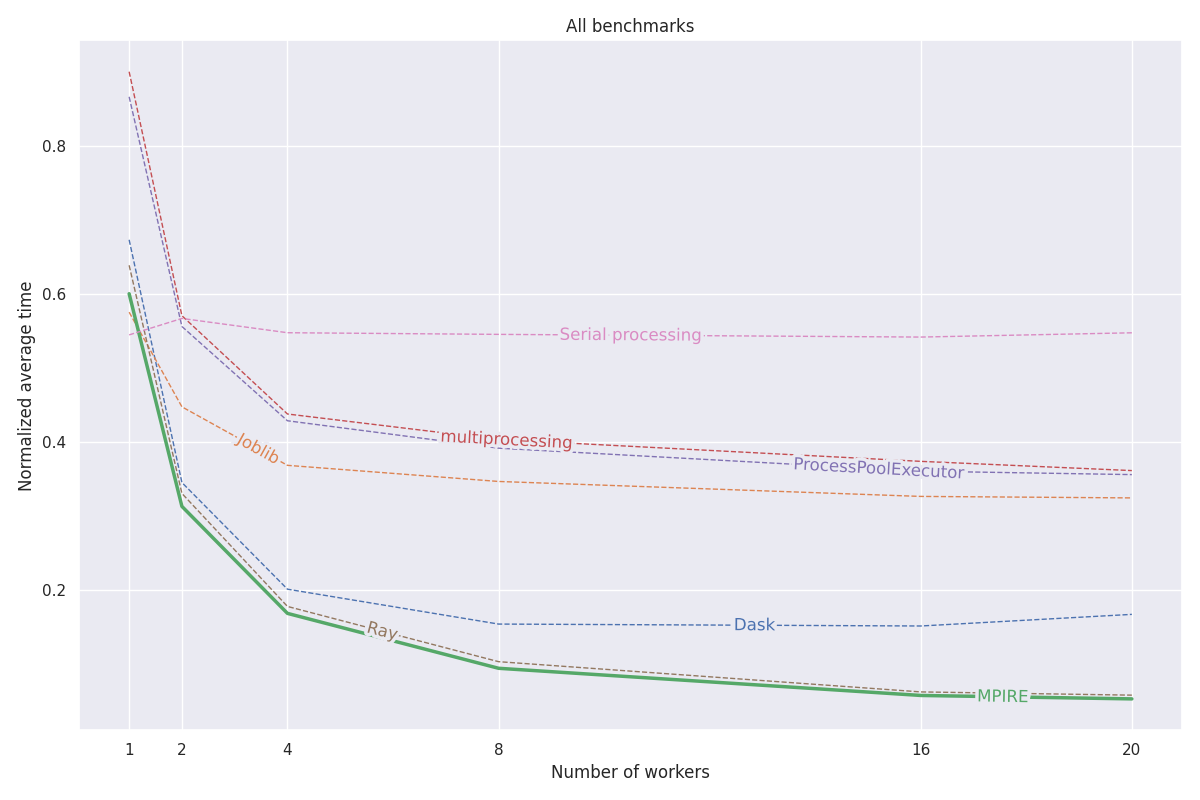
MPIRE 已經在三個不同的基準上進行了基準測試:數值計算、狀態計算和昂貴的初始化。有關這些基準的更多詳細資訊可以在這篇部落格文章中找到。這些基準測試的所有程式碼都可以在此專案中找到。
簡而言之,MPIRE 速度更快的主要原因是:
fork可用時,我們可以使用寫入時複製共享對象,這減少了複製需要在子進程上共享的對象的需要下圖顯示了所有三個基準的平均標準化結果。各個基準測試的結果可以在部落格文章中找到。基準測試在具有 20 個核心、禁用超線程和 200GB RAM 的 Linux 機器上運行。對於每項任務,都使用不同數量的進程/工作人員執行實驗,並對 5 次運行的結果進行平均。
有關 MPIRE 所有其他功能的信息,請參閱 https://sybrenjansen.github.io/mpire/ 上的完整文件。
如果您想自己建立文檔,請透過執行以下命令安裝文檔依賴項:
pip install mpire[docs]或者
pip install .[docs]然後可以使用 Python <= 3.9 並執行以下命令來建立文件:
python setup.py build_docs也可以直接從docs資料夾建置文件。在這種情況下,應該安裝MPIRE並在您當前的工作環境中可用。然後執行:
make html在docs夾中。


