chrono_lens
v1.1.1
這是國家統計局資料科學校園部落格上發布的交通攝影機分析專案的公共儲存庫,作為 ONS 冠狀病毒更快指標的一部分(例如 - 交通攝影機活動 - 2020 年 9 月 10 日)和基本方法。該專案利用 Google 運算平台 (GCP) 來實現可擴展的解決方案,但底層方法與平台無關;這個儲存庫包含我們面向 GCP 的實作。
下面介紹了為冠狀病毒更快指標產生的範例輸出。
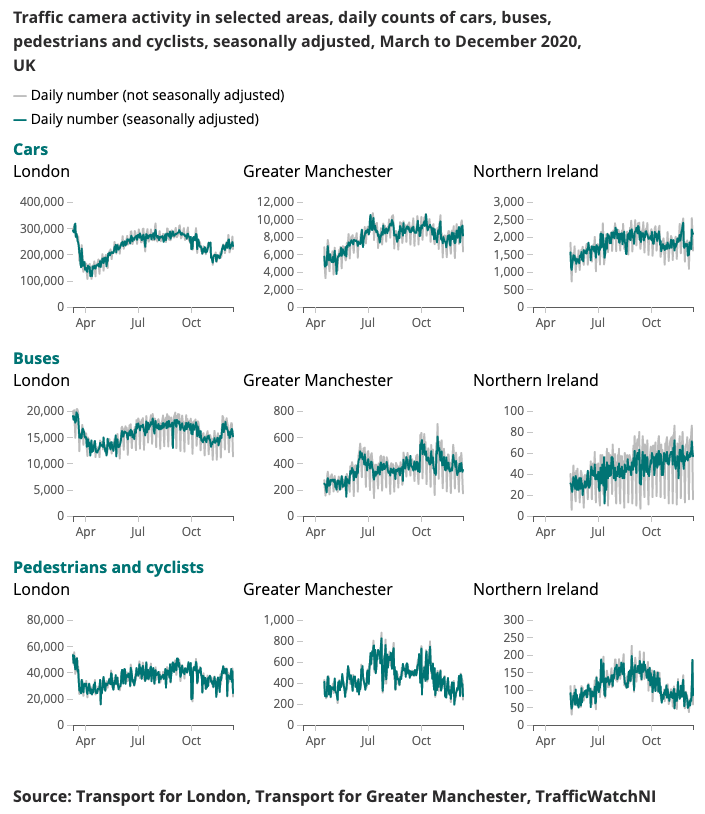
即時了解移動和行為模式的變化一直是政府應對冠狀病毒 (COVID-19) 的主要重點。數據科學校園一直在探索替代數據來源,這些數據來源可能會提供有關如何估計社交距離水平的見解,並隨著封鎖條件的放鬆跟踪社會和經濟的改善。
交通攝影機是一種廣泛公開的資料來源,允許交通專業人士和公眾透過網路評估全國不同地區的交通流量。交通攝影機產生的影像是公開的、低解析度的,並且不允許單獨識別人員或車輛。它們不同於用於公共安全和執法的自動車牌識別 (ANPR) 或監控交通速度的閉路電視。
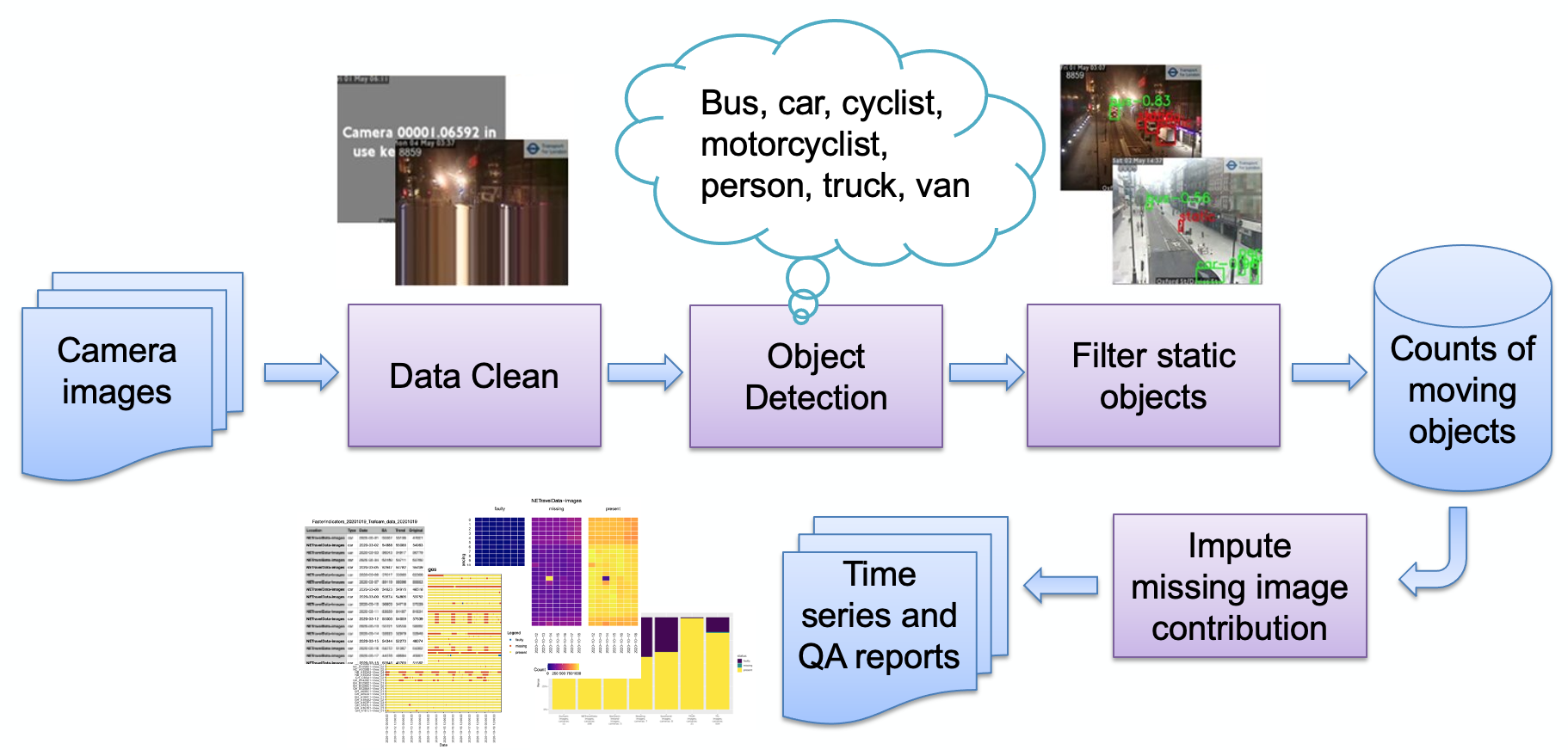
如圖所示,管道的主要階段是:
影像攝取
影像檢測錯誤
物體偵測
靜態物體偵測
儲存結果計數
然後可以進一步處理計數(季節性調整、缺失值插補)並根據需要轉換為報告。我們將簡要回顧主要的管道階段。
使用者選擇一組相機來源(Web 託管的 JPEG 影像),並將其作為 URL 清單提供給使用者。提供的範例程式碼用於從倫敦交通局獲取公共影像,以及直接從紐卡斯爾大學城市觀測站提取 NE 交通資料的專業程式碼。
相機可能因各種原因而無法使用(系統故障、本地操作員停用饋送等),這些可能會導致模型產生虛假物件計數(例如,小斑點可能看起來像遠處的巴士)。此類圖像的範例是: 
到目前為止,這些圖像都遵循非常合成的圖像模式,由平坦的背景顏色和覆蓋的文字組成(與自然場景的圖像相比)。目前,這些影像的檢測方法是降低色彩深度(將相似的顏色對齊在一起),然後查看影像中單一顏色佔據的最高部分。一旦超過閾值,我們就確定該影像是合成的並將其標記為有缺陷的。由於編碼可能會出現其他錯誤,例如: 
此處,camrera 饋送已停止,最後一個「即時」行已重複;我們透過檢查影像的底行是否與上面的行匹配(在閾值內)來檢測這一點。如果是這樣,則檢查上面的下一行是否匹配,依此類推,直到行不再匹配或我們用完行。如果匹配行的數量高於閾值,則影像不太可能產生有用的數據,因此被標記為有缺陷。
請注意,不同的影像提供者使用不同的方式來顯示相機不可用;我們的檢測技術依賴於使用的少量顏色 - 即純合成影像。如果使用更自然的圖像,我們的技術可能不起作用。另一種方法是保留失敗圖像的「庫」並尋找相似性,這對於更自然的圖像可能效果更好。
物件偵測過程使用紐卡斯爾大學城市天文台提供的預先訓練的 Faster-RCNN 來識別靜態和移動物件。該模型已使用英格蘭東北部的 10,000 個交通攝影機影像進行了訓練,並由 ONS 資料科學園區進一步驗證,以確認該模型可用於英國其他地區的攝影機影像。它可偵測以下物件類型:汽車、貨車、卡車、巴士、行人、騎自行車者、摩托車騎士。
由於我們的目標是偵測活動,因此使用時間資訊過濾掉靜態物件非常重要。影像每隔 10 分鐘採樣一次,因此傳統的視訊背景偵測方法(例如高斯混合)並不適用。
在物件偵測過程中分類的任何行人和車輛都將被設定為靜態,如果它們也出現在背景中,則將從最終計數中刪除。下圖顯示了靜態遮罩的範例結果,其中影像 (a) 中停放的汽車被識別為靜態並被移除。另一個好處是靜電面罩可以幫助消除誤報。例如,在影像(b)中,垃圾箱在物件偵測中被誤識別為行人,但被過濾為靜態背景。

結果簡單地儲存為表格,模式記錄攝影機 ID、日期、時間、每個物件類型(汽車、貨車、行人等)的相關計數(如果影像有問題或影像遺失)。
最初,該系統被設計為雲端原生,以實現可擴展性;然而,這引入了進入障礙 - 您需要擁有雲端提供者的帳戶,知道如何保護基礎設施等。使有興趣的用戶能夠在自己的筆記型電腦上簡單地運行系統。下面描述這兩種實作方式。
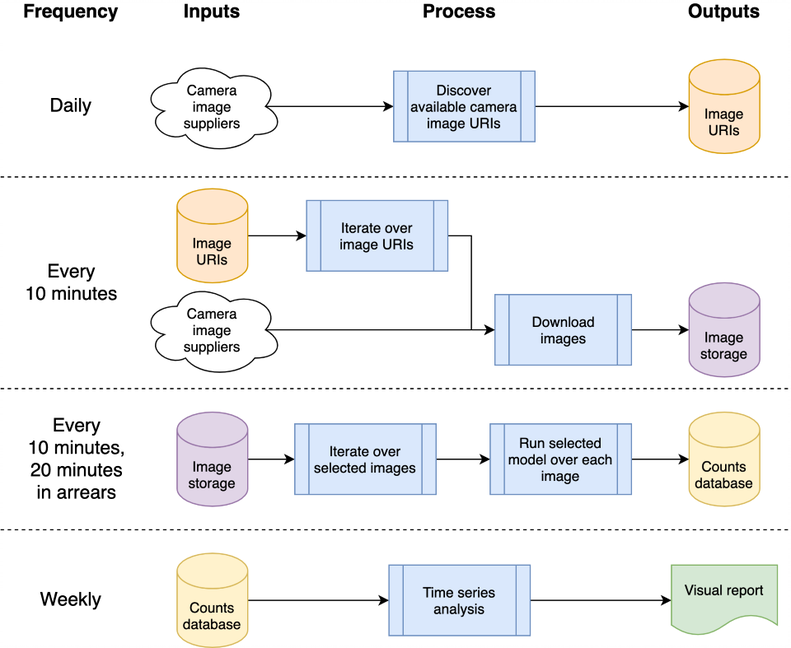
該架構可以映射到單機或者雲端系統;我們選擇使用Google運算平台(GCP),但其他平台,如亞馬遜網路服務(AWS)或微軟的Azure將提供相對等效的服務。
該系統以「雲函數」的形式託管,它們是獨立的無狀態代碼,可以重複調用而不會導致損壞——這是提高函數穩健性的關鍵考慮因素。使用 GCP 的排程器來編排每日和「每 10 分鐘」的處理突發,以根據所需的時間表觸發 GCP Pub/Sub 主題。 GCP 雲端函數針對主題註冊,並在觸發主題時啟動。
處理影像以偵測車輛和行人會導致物件計數寫入資料庫,以便日後作為時間序列進行分析。資料庫用於資料採集和時間序列分析之間共享數據,減少耦合。我們在 GCP 中使用 BigQuery 作為資料庫,因為它在其他 GCP 產品中得到了廣泛支持,例如用於資料視覺化的 Data Studio;本機實作會儲存每日 CSV 進行比較,以消除對特定資料庫或其他基礎架構的任何依賴。
GCP相關原始碼存放在cloud資料夾中;它會下載圖像,對其進行處理以對物件進行計數,將計數儲存在資料庫中並(每週)產生時間序列分析。所有文件和原始碼都儲存在cloud資料夾中;請參閱 Cloud README.md,以了解架構概述以及如何使用我們的腳本將您自己的執行個體安裝到您的 GCP 專案空間。該專案可以整合到GitHub中,實現自動部署和自動測試執行,從提交到本地GitHub專案;這也記錄在 Cloud README.md 中。雲端支援程式碼也儲存在chrono_lens.gcloud模組中,使命令列腳本能夠支援 GCP,以及cloud資料夾中的雲端函數程式碼。
獨立的單機(“localhost”)程式碼包含在chrono_lens.localhost模組中。這個過程遵循與 GCP 變體相同的流程,儘管使用單一機器,並且chrono_lens.localhost中的每個 python 檔案都對應到 GCP 的雲端功能。有關更多詳細信息,請參閱 README-localhost.md。
鑑於 GCP 和本地主機實現至少需要一些本地安裝,我們現在描述安裝系統的各個步驟和先決條件。
強烈建議創建虛擬環境,以提供隔離的工作環境。良好工作環境的範例包括 conda、pyenv 和 poerty。
請注意,依賴項已包含在requirements.txt中,因此請透過pip安裝:
pip install -r requirements.txt
為了防止意外提交密碼,建議使用預提交掛鉤,以防止在敏感資訊到達儲存庫之前處理 git 提交。我們使用了 https://github.com/ukgovdatascience/govcookiecutter 中的預提交掛鉤
安裝requirements.txt將安裝預先提交工具,現在需要連接到git:
pre-commit install
....然後將從.pre-commit-config.yaml中提取配置。
注意,在新增 RCNN 模型檔案/tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb fig_frcnn_rebuscov-3.pb 時, check-added-large-files預提交測試的.pre-commit-config.yaml中的最大 kB 大小暫時增加到 60Mb 。然後該限制將恢復為 5Mb 作為合理的“正常”上限。
建議在繼續之前對所有文件進行掃描,以確保沒有任何文件被錯誤地存在:
pre-commit run --all-files
這將報告任何現有問題 - 很有用,因為掛鉤僅在編輯的文件上運行。
該專案設計主要透過雲端基礎設施使用,但也有用於本地存取和更新雲端中時間序列的實用程式腳本。這些腳本位於scripts/gcloud資料夾中,每個腳本現在在單獨的以下部分中進行描述。更多資訊可以在scripts/gcloud/README.md中找到,並且可選虛擬機器對它們的使用在cloud/README.md中進行了描述。
scripts/localhost資料夾中的腳本支援非雲端使用, README-localhost.md中描述如何在獨立電腦上使用chrono_lens系統的詳細資訊。有關使用腳本的更多資訊可以在scripts/localhost/README.md中找到。
請注意,腳本使用chrono_lens資料夾中的程式碼。
| 版本 | 日期 | 筆記 |
|---|---|---|
| 1.0.0 | 2021-06-08 | 公共儲存庫的首次發布 |
| 1.0.1 | 2021-09-21 | 修正了孤立影像、tensorflow 版本凹凸的錯誤 |
| 1.1.0 | ? | 增加了對單機單機的有限支持 |
這裡介紹了未來潛在的工作領域;這些變化可能不會被調查,但目的是讓人們意識到我們考慮過的潛在改進。
目前,bash shell腳本用於建立GCP基礎架構;改進方法是使用 IaC,例如 Terraform。這簡化了(例如)雲端功能配置的更改,而無需在運行時環境或記憶體限制更改時手動刪除雲端建置觸發器並重新建立它。
目前的設計源自於其在模型最終確定之前獲取圖像的初始用例,因此所有可用圖像都會被下載,而不僅僅是那些被分析的圖像。為了節省攝取成本,攝取程式碼應對照分析 JSON 檔案進行交叉檢查並僅下載這些檔案;當任何這些來源不再可用或有新來源可用時,應發出警報。
NETravelData 的影像每晚回填似乎刷新了約 40% 的 NETravelData 影像;如果只每天需要這些數字,則定期刷新的優勢就會減弱,因此可以刪除雲函數distribute_ne_travel_data 。
http async異步轉向 PubSub初始設計在測試新模型時使用手動操作的腳本 - 即batch_process_images.py 。這會報告成功(或失敗)以及處理的圖像數量。為此,雲端函數可以很好地工作,因為它會傳回結果。然而,更有效率的架構是在內部使用 PubSub 佇列,並使用distribute_json_sources和processed_scheduled函數將工作新增至由單一工作函數消耗的PubSub 佇列,而不是目前的非同步呼叫層次結構(使用兩個額外的函數來橫向擴展) )。
紐卡斯爾大學城市觀測站提供了我們使用的預訓練 Faster-RCNNN(本地副本儲存在/tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb fig_frcnn_rebuscov-3.pb 中)。
資料由東北城市交通管理和控制開放資料服務提供,並根據開放政府許可證 3.0 獲得許可。圖片來自泰恩威爾郡城市交通管理與控制。
東北部數據由紐卡斯爾大學城市觀測站進一步處理和託管,我們衷心感謝其支持和建議。
數據由倫敦交通局 (TfL) 提供,並由倫敦交通局開放資料 (TfL Open Data) 提供支援。該資料根據開放政府授權 2.0 版獲得許可。 TfL 資料包含 OS 資料 © Crown 版權和資料庫權利 2016 以及 Geomni UK 地圖資料 © 和資料庫權利 (2019)。
本項目使用了各種第三方函式庫;這些都列在依賴項頁面上,我們衷心感謝他們的貢獻。


