shap
v0.46.0
SHAP(SHapley Additive exPlanations)是一種博弈論方法,用於解釋任何機器學習模型的產出。它使用博弈論中的經典沙普利值及其相關擴展,將最優信用分配與局部解釋聯繫起來(有關詳細資訊和引文,請參閱論文)。
SHAP 可以從 PyPI 或 conda-forge 安裝:
pip 安裝 shap 或者 conda install -c conda-forge shap
雖然 SHAP 可以解釋任何機器學習模型的輸出,但我們已經為樹集成方法開發了一種高速精確演算法(請參閱我們的 Nature MI 論文)。 XGBoost 、 LightGBM 、 CatBoost 、 scikit-learn和pyspark樹模型支援快速 C++ 實作:
import xgboost
import shap
# train an XGBoost model
X , y = shap . datasets . california ()
model = xgboost . XGBRegressor (). fit ( X , y )
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap . Explainer ( model )
shap_values = explainer ( X )
# visualize the first prediction's explanation
shap . plots . waterfall ( shap_values [ 0 ])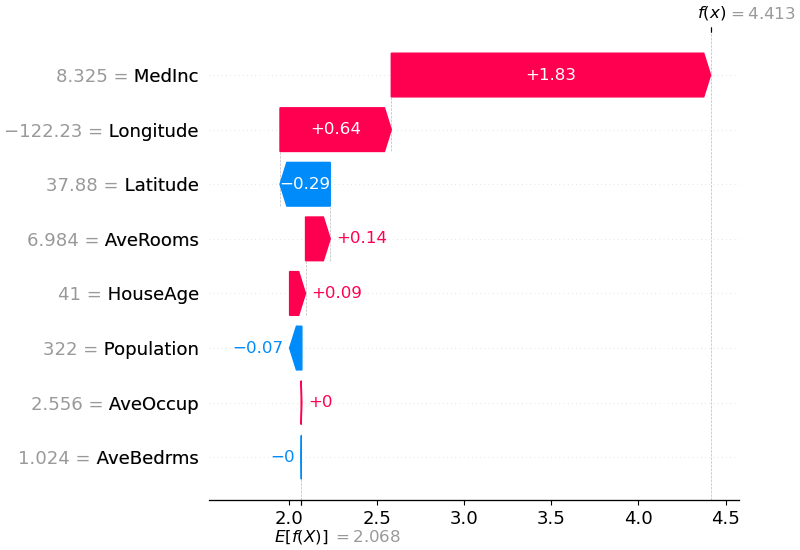
上面的解釋顯示了每個有助於將模型輸出從基底值(我們傳遞的訓練資料集上的平均模型輸出)推送到模型輸出的功能。將預測推高的特徵顯示為紅色,將預測推低的特徵顯示為藍色。可視化相同解釋的另一種方法是使用力圖(這些在我們的 Nature BME 論文中介紹):
# visualize the first prediction's explanation with a force plot
shap . plots . force ( shap_values [ 0 ])
如果我們採用許多力圖解釋(如上所示),將它們旋轉 90 度,然後水平堆疊它們,我們可以看到整個資料集的解釋(在筆記本中,此圖是互動的):
# visualize all the training set predictions
shap . plots . force ( shap_values [: 500 ])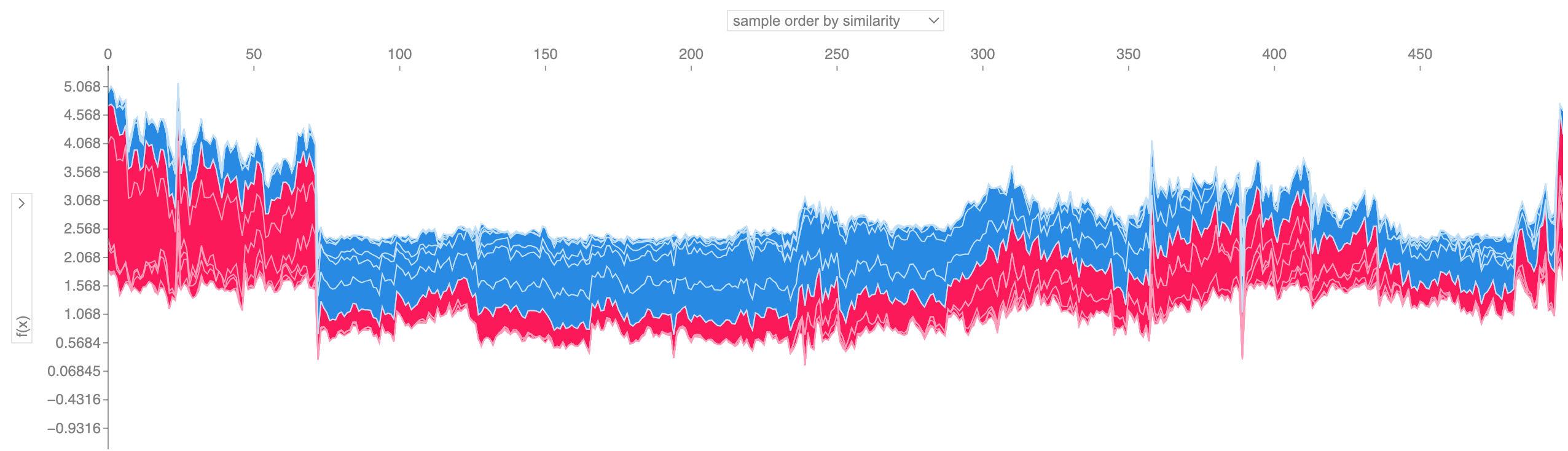
為了了解單一特徵如何影響模型的輸出,我們可以繪製該特徵的 SHAP 值與資料集中所有範例的特徵值的關係。由於 SHAP 值代表要素對模型輸出變化的責任,因此下圖表示預測房價隨緯度變化的變化。單一緯度值的垂直色散表示與其他要素的交互作用效應。為了幫助揭示這些相互作用,我們可以用另一個特徵來著色。如果我們將整個解釋張量傳遞給color參數,則散佈圖將選擇最佳的特徵來著色。在本例中,它選擇經度。
# create a dependence scatter plot to show the effect of a single feature across the whole dataset
shap . plots . scatter ( shap_values [:, "Latitude" ], color = shap_values )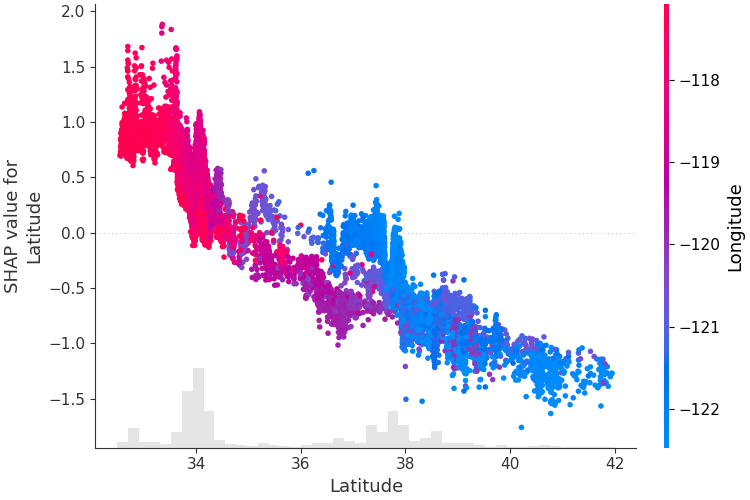
為了概述哪些特徵對模型最重要,我們可以繪製每個樣本的每個特徵的 SHAP 值。下圖按所有樣本的 SHAP 值大小總和對特徵進行排序,並使用 SHAP 值顯示每個特徵對模型輸出的影響的分佈。顏色代表特徵值(紅色高,藍色低)。例如,這表明較高的中位數收入會提高預測的房價。
# summarize the effects of all the features
shap . plots . beeswarm ( shap_values )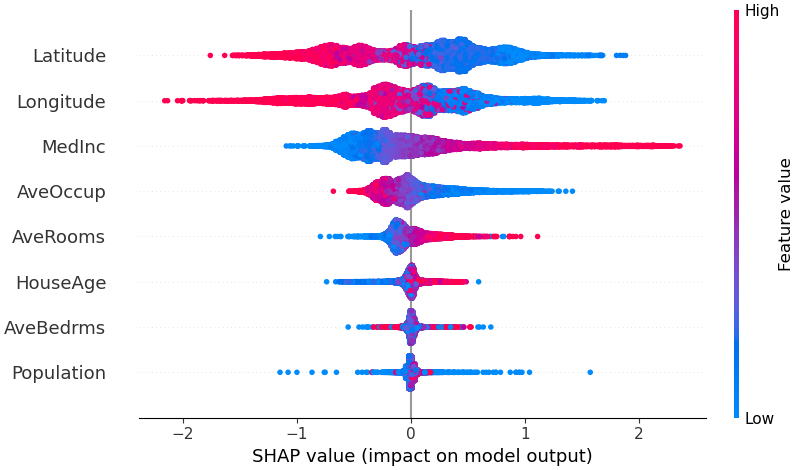
我們也可以只取每個特徵的 SHAP 值的平均絕對值來獲得標準長條圖(為多類輸出產生堆疊長條圖):
shap . plots . bar ( shap_values )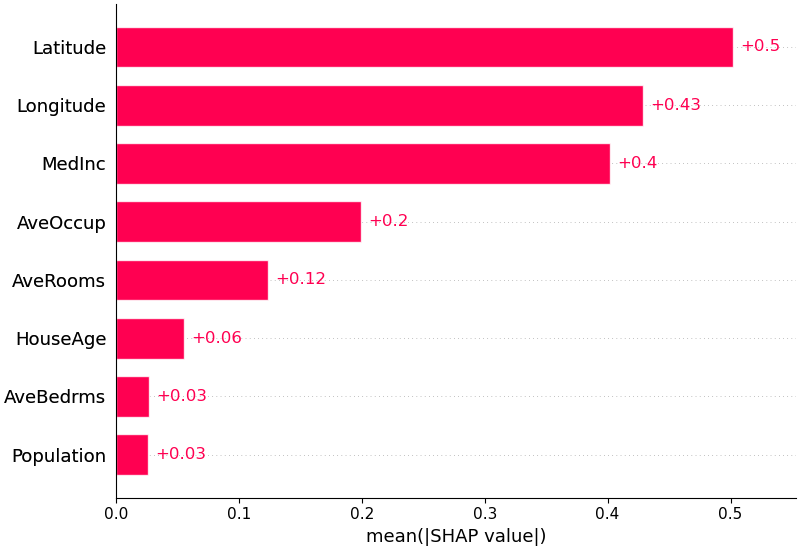
SHAP 對自然語言模型(如 Hugging Face 轉換器庫中的模型)提供特定支援。透過在傳統 Shapley 值中加入聯合規則,我們可以形成使用很少的函數評估來解釋大型現代 NLP 模型的博弈。使用此功能就像將受支援的轉換器管道傳遞給 SHAP 一樣簡單:
import transformers
import shap
# load a transformers pipeline model
model = transformers . pipeline ( 'sentiment-analysis' , return_all_scores = True )
# explain the model on two sample inputs
explainer = shap . Explainer ( model )
shap_values = explainer ([ "What a great movie! ...if you have no taste." ])
# visualize the first prediction's explanation for the POSITIVE output class
shap . plots . text ( shap_values [ 0 , :, "POSITIVE" ])Deep SHAP 是深度學習模型中 SHAP 值的高速近似演算法,它建立在與 SHAP NIPS 論文中所描述的 DeepLIFT 的連結之上。這裡的實作與原始DeepLIFT 的不同之處在於,它使用背景樣本的分佈而不是單一參考值,並使用Shapley 方程式對max、softmax、乘積、除法等組件進行線性化。已被自從整合到 DeepLIFT 中以來。支援使用 TensorFlow 後端的 TensorFlow 模型和 Keras 模型(也初步支援 PyTorch):
# ...include code from https://github.com/keras-team/keras/blob/master/examples/demo_mnist_convnet.py
import shap
import numpy as np
# select a set of background examples to take an expectation over
background = x_train [ np . random . choice ( x_train . shape [ 0 ], 100 , replace = False )]
# explain predictions of the model on four images
e = shap . DeepExplainer ( model , background )
# ...or pass tensors directly
# e = shap.DeepExplainer((model.layers[0].input, model.layers[-1].output), background)
shap_values = e . shap_values ( x_test [ 1 : 5 ])
# plot the feature attributions
shap . image_plot ( shap_values , - x_test [ 1 : 5 ])上圖解釋了四個不同影像的十個輸出(數字 0-9)。紅色像素增加模型的輸出,而藍色像素減少輸出。輸入影像顯示在左側,每個解釋後面都有幾乎透明的灰階背景。 SHAP 值的總和等於預期模型輸出(背景資料集的平均值)與目前模型輸出之間的差異。請注意,對於“零”圖像,中間的空白很重要,而對於“四”圖像,頂部缺少連接使其成為四而不是九。
預期梯度將 Integrated Gradients、SHAP 和 SmoothGrad 的想法結合到一個預期值方程式。這允許將整個資料集用作背景分佈(而不是單一參考值)並允許局部平滑。如果我們用每個背景資料樣本和要解釋的當前輸入之間的線性函數來近似模型,並且我們假設輸入特徵是獨立的,那麼預期梯度將計算近似的 SHAP 值。在下面的範例中,我們解釋了 VGG16 ImageNet 模型的第 7 個中間層如何影響輸出機率。
from keras . applications . vgg16 import VGG16
from keras . applications . vgg16 import preprocess_input
import keras . backend as K
import numpy as np
import json
import shap
# load pre-trained model and choose two images to explain
model = VGG16 ( weights = 'imagenet' , include_top = True )
X , y = shap . datasets . imagenet50 ()
to_explain = X [[ 39 , 41 ]]
# load the ImageNet class names
url = "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json"
fname = shap . datasets . cache ( url )
with open ( fname ) as f :
class_names = json . load ( f )
# explain how the input to the 7th layer of the model explains the top two classes
def map2layer ( x , layer ):
feed_dict = dict ( zip ([ model . layers [ 0 ]. input ], [ preprocess_input ( x . copy ())]))
return K . get_session (). run ( model . layers [ layer ]. input , feed_dict )
e = shap . GradientExplainer (
( model . layers [ 7 ]. input , model . layers [ - 1 ]. output ),
map2layer ( X , 7 ),
local_smoothing = 0 # std dev of smoothing noise
)
shap_values , indexes = e . shap_values ( map2layer ( to_explain , 7 ), ranked_outputs = 2 )
# get the names for the classes
index_names = np . vectorize ( lambda x : class_names [ str ( x )][ 1 ])( indexes )
# plot the explanations
shap . image_plot ( shap_values , to_explain , index_names )上圖中解釋了對兩個輸入影像的預測。紅色像素代表增加類別機率的正 SHAP 值,而藍色像素代表減少類別機率的負 SHAP 值。透過使用ranked_outputs=2我們僅解釋每個輸入的兩個最有可能的類別(這使我們無需解釋所有 1,000 個類別)。
內核 SHAP 使用特殊加權的局部線性迴歸來估計任何模型的 SHAP 值。以下是一個簡單的範例,用於解釋經典鳶尾花資料集上的多類 SVM。
import sklearn
import shap
from sklearn . model_selection import train_test_split
# print the JS visualization code to the notebook
shap . initjs ()
# train a SVM classifier
X_train , X_test , Y_train , Y_test = train_test_split ( * shap . datasets . iris (), test_size = 0.2 , random_state = 0 )
svm = sklearn . svm . SVC ( kernel = 'rbf' , probability = True )
svm . fit ( X_train , Y_train )
# use Kernel SHAP to explain test set predictions
explainer = shap . KernelExplainer ( svm . predict_proba , X_train , link = "logit" )
shap_values = explainer . shap_values ( X_test , nsamples = 100 )
# plot the SHAP values for the Setosa output of the first instance
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ][ 0 ,:], X_test . iloc [ 0 ,:], link = "logit" )上面的解釋顯示了四個特徵,每個特徵都有助於將模型輸出從基值(我們通過的訓練資料集的平均模型輸出)推向零。如果有任何功能將類別標籤推高,它們將顯示為紅色。
如果我們採用如上所示的多種解釋,將它們旋轉 90 度,然後水平堆疊它們,我們就可以看到整個資料集的解釋。這正是我們在下面對 iris 測試集中的所有範例所做的操作:
# plot the SHAP values for the Setosa output of all instances
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ], X_test , link = "logit" )SHAP 交互值是 SHAP 值對更高階交互作用的推廣。使用shap.TreeExplainer(model).shap_interaction_values(X)為樹模型實現了成對交互作用的快速精確計算。這會為每個預測傳回一個矩陣,其中主效應位於對角線上,交互效應位於非對角線上。這些值經常揭示有趣的隱藏關係,例如男性死亡風險增加如何在 60 歲時達到峰值(有關詳細信息,請參閱 NHANES 筆記本):
下面的筆記本示範了 SHAP 的不同用例。如果您想自己嘗試使用原始筆記本,請查看儲存庫的筆記本目錄。
Tree SHAP 的實現,一種快速而精確的演算法,用於計算樹和樹集合的 SHAP 值。
具有 XGBoost 和 SHAP 交互作用值的 NHANES 生存模型- 使用 20 年追蹤的死亡率數據,本筆記本示範如何使用 XGBoost 和shap來揭示複雜的風險因素關係。
使用 LightGBM 進行人口普查收入分類- 該筆記本使用標準成人人口普查收入資料集,使用 LightGBM 訓練梯度增強樹模型,然後使用shap解釋預測。
使用 XGBoost 預測英雄聯盟獲勝- 使用包含 180,000 場英雄聯盟排名比賽的 Kaggle 資料集,我們使用 XGBoost 訓練和解釋梯度提升樹模型,以預測玩家是否會贏得比賽。
Deep SHAP 的實現,這是一種更快(但只是近似)的演算法,用於計算深度學習模型的 SHAP 值,該演算法基於 SHAP 和 DeepLIFT 演算法之間的連接。
使用 Keras 進行 MNIST 數字分類- 該筆記本使用 MNIST 手寫識別資料集,使用 Keras 訓練神經網絡,然後使用shap解釋預測。
用於 IMDB 情緒分類的 Keras LSTM - 此筆記本在 IMDB 文字情緒分析資料集上使用 Keras 訓練 LSTM,然後使用shap解釋預測。
實現深度學習模型的近似 SHAP 值的預期梯度。它基於 SHAP 和積分梯度演算法之間的聯繫。 GradientExplainer 比 DeepExplainer 慢,並且做出不同的近似假設。
對於具有獨立特徵的線性模型,我們可以分析計算精確的 SHAP 值。如果我們願意估計特徵協方差矩陣,我們也可以考慮特徵相關性。 LinearExplainer 支援這兩個選項。
內核 SHAP 的實現,這是一種與模型無關的方法,用於估計任何模型的 SHAP 值。因為 KernelExplainer 不對模型類型做出任何假設,所以它比其他模型類型特定的演算法慢。
使用 scikit-learn 進行人口普查收入分類- 使用標準成人人口普查收入資料集,此筆記本使用 scikit-learn 訓練 k 最近鄰分類器,然後使用shap解釋預測。
ImageNet VGG16 Model with Keras - 解釋經典 VGG16 卷積神經網路對影像的預測。這是透過將與模型無關的 Kernel SHAP 方法應用於超像素分割影像來實現的。
鳶尾花分類- 使用流行的鳶尾花物種資料集的基本演示。它解釋了 scikit-learn 中使用shap的六種不同模型的預測。
這些筆記本全面示範如何使用特定的功能和物件。
shap.decision_plot和shap.multioutput_decision_plot
shap.dependence_plot
石灰: Ribeiro、Marco Tulio、Sameer Singh 和 Carlos Guestrin。 “我為什麼要相信你?:解釋任何分類器的預測。”第 22 屆 ACM SIGKDD 國際知識發現與資料探勘會議論文集。美國CM,2016。
Shapley 採樣值: Strumbelj、Erik 和 Igor Kononenko。 “透過特徵貢獻解釋預測模型和個體預測。”知識與資訊系統41.3(2014):647-665。
DeepLIFT: Shrikumar、Avanti、Peyton Greenside 和 Anshul Kundaje。 “透過傳播激活差異來學習重要特徵。” arXiv 預印本 arXiv:1704.02685 (2017)。
QII: Datta、Anupam、Shayak Sen 和 Yair Zick。 “透過定量輸入影響實現演算法透明度:學習系統的理論和實驗。”安全與隱私 (SP),2016 年 IEEE 研討會。 IEEE,2016。
逐層相關性傳播: Bach、Sebastian 等人。 “透過逐層相關性傳播對非線性分類器決策進行像素級解釋。” PloS one 10.7 (2015): e0130140。
Shapley 迴歸值: Lipovetsky、Stan 和 Michael Conklin。 “博弈論方法中的迴歸分析。”商業和工業中的應用隨機模型 17.4 (2001): 319-330。
樹解釋者:薩巴斯、安藤。解釋隨機森林。 http://blog.datadive.net/interpreting-random-forests/
該軟體包中使用的演算法和視覺化主要來自華盛頓大學 Su-In Lee 實驗室和微軟研究院的研究。如果您在研究中使用 SHAP,我們將不勝感激對適當論文的引用:
force_plot視覺化和醫學應用,您可以閱讀/引用我們的《自然生物醫學工程》論文(bibtex;免費存取)。

