whisperX
3.1.1
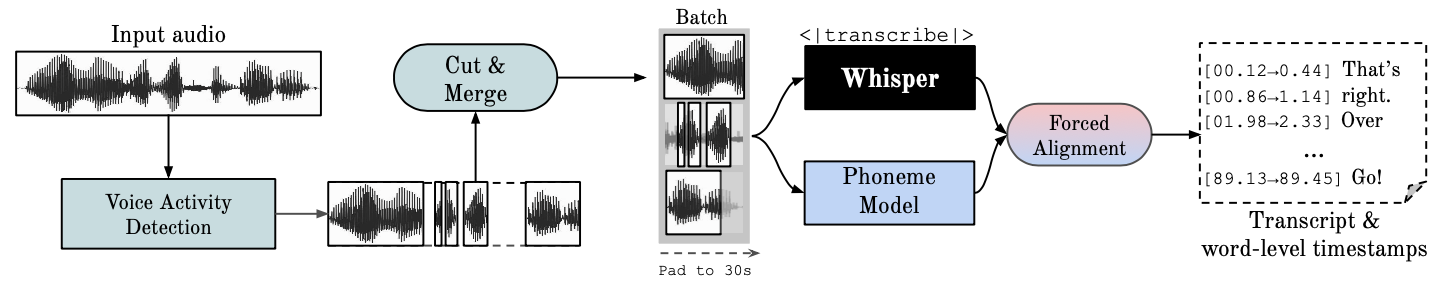
此儲存庫提供快速自動語音辨識(使用大型 v2 實現 70 倍即時),具有字級時間戳記和說話者二值化。
Whisper是 OpenAI 開發的 ASR 模型,在不同音訊的大型資料集上進行訓練。雖然它確實產生了高度準確的轉錄,但相應的時間戳是話語級別的,而不是每個單字的,並且可能不準確幾秒鐘。 OpenAI 的耳語本身並不支援批次處理。
基於音素的 ASR一套經過微調的模型,用於識別區分一個單字和另一個單字的最小語音單位,例如「tap」中的元素 p。一個流行的範例模型是 wav2vec2.0。
強制對齊是指將正字法轉錄與錄音對齊以自動產生音素級分割的過程。
語音活動偵測 (VAD)是偵測人類語音是否存在。
說話者分類是根據每個說話人的身分將包含人類語音的音訊串流劃分為同質片段的過程。
GPU 執行需要在系統上安裝 NVIDIA 函式庫 cuBLAS 11.x 和 cuDNN 8.x。請參閱 CTranslate2 文件。
conda create --name whisperx python=3.10
conda activate whisperx
conda install pytorch==2.0.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
請參閱此處的其他方法。
pip install git+https://github.com/m-bain/whisperx.git
如果已安裝,請將軟體包更新至最新提交
pip install git+https://github.com/m-bain/whisperx.git --upgrade
如果希望修改此包,請複製並以可編輯模式安裝:
$ git clone https://github.com/m-bain/whisperX.git
$ cd whisperX
$ pip install -e .
您可能還需要安裝 ffmpeg、rust 等。
若要啟用「Speaker Diarization」 ,請在--hf_token參數後麵包含您可以從此處產生的Hugging Face 存取權杖(讀取),並接受以下模型的使用者協定:Segmentation 和Speaker-Diarization-3.1(如果您選擇使用Speaker) -Diarization 2.x,請遵循此處的要求。
筆記
截至 2023 年 10 月 11 日,whisperX 中存在一個有關 pyannote/Speaker-Diarization-3.0 效能緩慢的已知問題。這是由於 fast-whisper 和 pyannote-audio 3.0.0 之間的依賴衝突所造成的。請參閱此問題以了解更多詳細資訊和潛在的解決方法。
在範例片段上運行耳語(使用預設參數,耳語小)添加--highlight_words True以可視化 .srt 檔案中的單字計時。
whisperx examples/sample01.wav
使用WhisperX強制對齊到 wav2vec2.0 Large 的結果:
將此與原始的耳語進行比較,其中許多轉錄不同步:
為了提高時間戳準確性,以更高的 GPU mem 為代價,使用更大的模型(發現更大的對齊模型沒有那麼有幫助,請參閱論文)例如
whisperx examples/sample01.wav --model large-v2 --align_model WAV2VEC2_ASR_LARGE_LV60K_960H --batch_size 4
要使用說話者 ID 標記文字記錄(如果已知,則設定說話者數量,例如--min_speakers 2 --max_speakers 2 ):
whisperx examples/sample01.wav --model large-v2 --diarize --highlight_words True
要在 CPU 而不是 GPU 上運行(並在 Mac OS X 上運行):
whisperx examples/sample01.wav --compute_type int8
音素 ASR 對齊模型是特定於語言的,對於測試的語言,這些模型是從 torchaudio 管道或 Huggingface 中自動選取的。只需傳遞--language代碼,並使用 Whisper --model large 。
目前為{en, fr, de, es, it, ja, zh, nl, uk, pt}提供預設模型。如果偵測到的語言不在這個清單中,您需要從 Huggingface 模型中心找到基於音素的 ASR 模型,並在您的資料上進行測試。
whisperx --model large-v2 --language de examples/sample_de_01.wav
請在此處查看其他語言的更多範例。
import whisperx
import gc
device = "cuda"
audio_file = "audio.mp3"
batch_size = 16 # reduce if low on GPU mem
compute_type = "float16" # change to "int8" if low on GPU mem (may reduce accuracy)
# 1. Transcribe with original whisper (batched)
model = whisperx . load_model ( "large-v2" , device , compute_type = compute_type )
# save model to local path (optional)
# model_dir = "/path/"
# model = whisperx.load_model("large-v2", device, compute_type=compute_type, download_root=model_dir)
audio = whisperx . load_audio ( audio_file )
result = model . transcribe ( audio , batch_size = batch_size )
print ( result [ "segments" ]) # before alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model
# 2. Align whisper output
model_a , metadata = whisperx . load_align_model ( language_code = result [ "language" ], device = device )
result = whisperx . align ( result [ "segments" ], model_a , metadata , audio , device , return_char_alignments = False )
print ( result [ "segments" ]) # after alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model_a
# 3. Assign speaker labels
diarize_model = whisperx . DiarizationPipeline ( use_auth_token = YOUR_HF_TOKEN , device = device )
# add min/max number of speakers if known
diarize_segments = diarize_model ( audio )
# diarize_model(audio, min_speakers=min_speakers, max_speakers=max_speakers)
result = whisperx . assign_word_speakers ( diarize_segments , result )
print ( diarize_segments )
print ( result [ "segments" ]) # segments are now assigned speaker IDs 如果您無法存取自己的 GPU,請使用上面的連結嘗試 WhisperX。
有關批次和對齊、VAD 的效果以及所選對齊模型的具體細節,請參閱預印本論文。
若要減少 GPU 記憶體需求,請嘗試以下任一方法(2. 和 3. 可能會影響品質):
--batch_size 4--model base--compute_type int8與 openai 的耳語轉錄差異:
--without_timestamps True ,這可確保批次中每個樣本進行 1 次前向傳遞。但是,這可能會導致預設耳語輸出出現差異。--condition_on_prev_text預設為False (減少幻覺) 如果您會說多種語言,您可以為該專案做出貢獻的一個主要方法是在 Huggingface 上找到音素模型(或訓練您自己的模型)並在目標語言的語音上測試它們。如果結果看起來不錯,請發送拉取請求和一些顯示其成功的範例。
錯誤查找和拉取請求也受到高度讚賞,以保持該專案的繼續進行,因為它已經偏離了最初的研究範圍。
多語言初始化
基於語言偵測的自動對齊模型選擇
Python使用
納入說話者分類
模型刷新,適用於低 GPU 記憶體資源
更快的耳語後端
加入 max-line 等參見(openai 的耳語 utils.py)
句子級分段(nltk 工具箱)
改進對齊邏輯
透過分類和單字突出顯示更新範例
字幕 .ass 輸出 <- 將其帶回來(在 v3 中刪除)
新增基準測試程式碼(用於 spd/WER 和分詞的 TEDLIUM)
允許 silero-vad 作為替代 VAD 選項
改進分類(單字等級)。比原想的更難...
如有疑問,請聯絡 [email protected]。
這項工作和我的博士學位得到了 VGG(視覺幾何小組)和牛津大學的支持。
當然,這是建立在openAI的耳語之上的。借用 PyTorch 強制對齊教程中的重要對齊程式碼,並使用精彩的 pyannote VAD / Diarization https://github.com/pyannote/pyannote-audio
來自 [pyannote audio] 的有價值的 VAD 和二值化模型[https://github.com/pyannote/pyannote-audio]
來自 fast-whisper 和 CTranslate2 的出色後端
那些在經濟上支持這項工作的人
最後,感謝該專案的作業系統貢獻者,讓其繼續下去並發現錯誤。
@article { bain2022whisperx ,
title = { WhisperX: Time-Accurate Speech Transcription of Long-Form Audio } ,
author = { Bain, Max and Huh, Jaesung and Han, Tengda and Zisserman, Andrew } ,
journal = { INTERSPEECH 2023 } ,
year = { 2023 }
}

