BLIVA
1.0.0
胡文波*、徐一凡*、李毅、李偉躍、陳澤元和塗卓文。 *平等貢獻
加州大學聖地牙哥分校、 Coinbase Global, Inc.
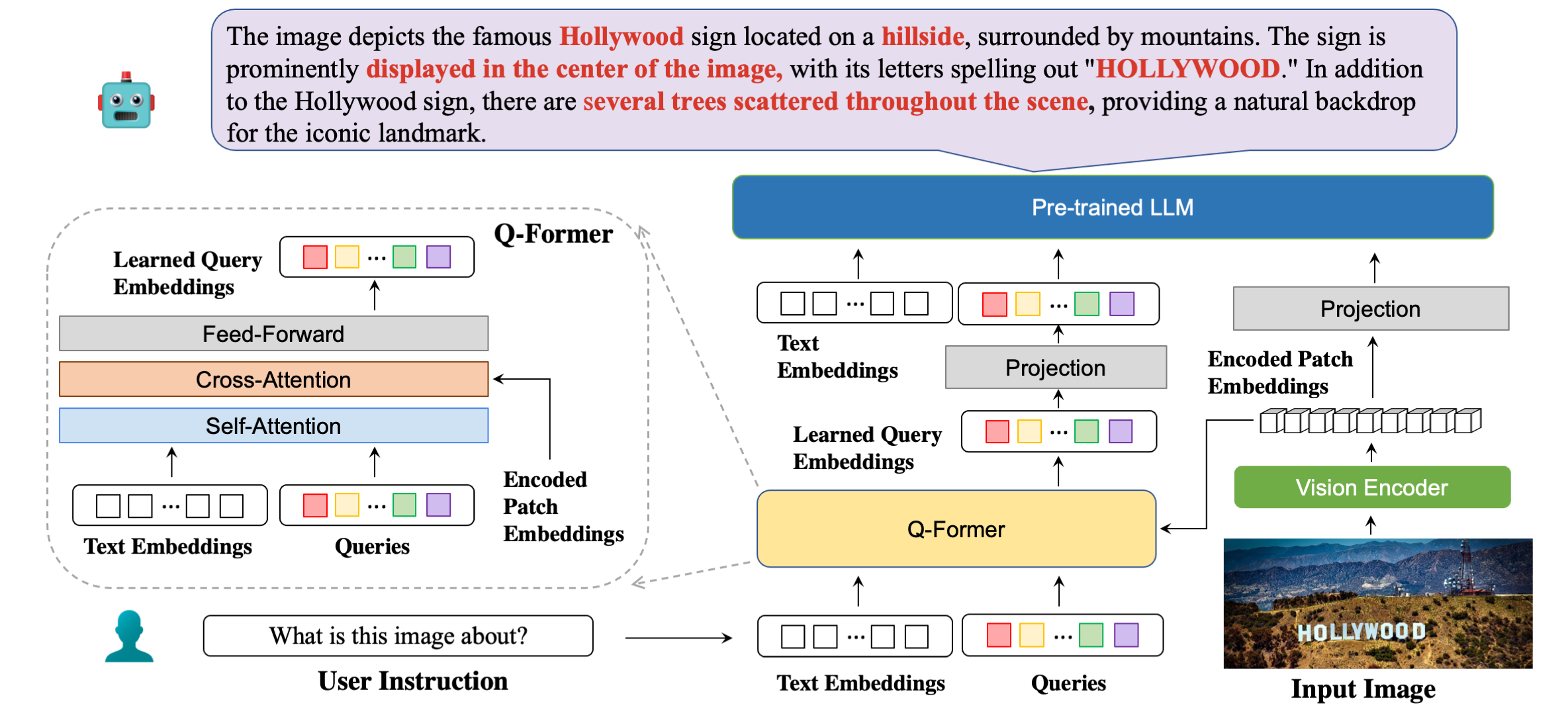
我們的模型架構詳細說明了範例回應。
| 方法 | 衛星電視品質保證 | OCRV品質保證 | 文字VQA | 文件VQA | 資訊品質保證 | 圖表品質保證 | ESTVQA | 基金會 | 社會投資報酬率 | POIE | 平均的 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 開放火烈鳥 | 19.32 | 27.82 | 29.08 | 5.05 | 14.99 | 9.12 | 28.20 | 0.85 | 0.12 | 2.12 | 13.67 |
| BLIP2-OPT | 13.36 | 10.58 | 21.18 | 0.82 | 8.82 | 7.44 | 27.02 | 0.00 | 0.00 | 0.02 | 8.92 |
| BLIP2-FLanT5XXL | 21.38 | 30.28 | 30.62 | 4.00 | 10.17 | 7.20 | 42.46 | 1.19 | 0.20 | 2.52 | 15:00 |
| 迷你GPT4 | 14.02 | 11.52 | 18.72 | 2.97 | 13.32 | 4.32 | 28.36 | 1.19 | 0.04 | 1.31 | 9.58 |
| 拉瓦 | 22.93 | 15.02 | 28.30 | 4.40 | 13.78 | 7.28 | 33.48 | 1.02 | 0.12 | 2.09 | 12.84 |
| mPLUG-Owl | 26.32 | 35:00 | 37.44 | 6.17 | 16.46 | 9.52 | 49.68 | 1.02 | 0.64 | 3.26 | 18.56 |
| 指導BLIP (FLANT5XXL) | 26.22 | 55.04 | 36.86 | 4.94 | 10.14 | 8.16 | 43.84 | 1.36 | 0.50 | 1.91 | 18.90 |
| 指導BLIP (Vicuna-7B) | 28.64 | 47.62 | 39.60 | 5.89 | 13.10 | 5.52 | 47.66 | 0.85 | 0.64 | 2.66 | 19.22 |
| 布利瓦 (FLANT5XXL) | 28.24 | 61.34 | 39.36 | 5.22 | 10.82 | 9.28 | 45.66 | 1.53 | 0.50 | 2.39 | 20.43 |
| BLIVA (Vicuna-7B) | 29.08 | 65.38 | 42.18 | 6.24 | 13.50 | 8.16 | 48.14 | 1.02 | 0.88 | 2.91 | 21.75 |
| 方法 | 振動時效 | 圖示品質保證 | 文字VQA | 維斯迪亞爾 | Flickr30K | HM | 維茲維茲 | 右心室舒張時間 |
|---|---|---|---|---|---|---|---|---|
| 火烈鳥3B | - | - | 30.1 | - | 60.6 | - | - | - |
| 火烈鳥9B | - | - | 31.8 | - | 61.5 | - | - | - |
| 火烈鳥80B | - | - | 35.0 | - | 67.2 | - | - | - |
| 迷你GPT-4 | 50.65 | - | 18.56 | - | - | 29.0 | 34.78 | - |
| 拉瓦 | 56.3 | - | 37.98 | - | - | 9.2 | 36.74 | - |
| BLIP-2 (Vicuna-7B) | 50.0 | 39.7 | 40.1 | 44.9 | 74.9 | 50.2 | 49.34 | 4.17 |
| 指導BLIP (Vicuna-7B) | 54.3 | 43.1 | 50.1 | 45.2 | 82.4 | 54.8 | 43.3 | 18.7 |
| BLIVA (Vicuna-7B) | 62.2 | 44.88 | 57.96 | 45.63 | 87.1 | 55.6 | 42.9 | 23.81 |
conda create -n bliva python=3.9
conda activate blivagit clone https://github.com/mlpc-ucsd/BLIVA
cd BLIVA
pip install -e . BLIVA 駱駝毛 7B
我們的 Vicuna 版本模型在這裡發布。下載我們的模型權重並在模型配置中的第 8 行中指定路徑。
我們使用的LLM是Vicuna-7B的v0.1版本。要準備駱駝毛的重量,請參閱此處的說明。然後,在模型設定檔第 21 行設定 vicuna 權重的路徑。
BLIVA FlanT5 XXL(可用於商業用途)
FlanT5版本模型在這裡發布。下載我們的模型權重並在模型配置中的第 8 行中指定路徑。
當執行我們的推理程式碼時,Flant5 的 LLM 權重將自動開始從 Huggingface 下載。
要回答影像中的一個問題,請執行以下評估程式碼。例如,
python evaluate.py --answer_qs
--model_name bliva_vicuna
--img_path images/example.jpg
--question " what is this image about? "我們也支持回答多項選擇題,這與我們在論文中用於評估任務的相同。要提供選項列表,它應該是用逗號分隔的字串。例如,
python evaluate.py --answer_mc
--model_name bliva_vicuna
--img_path images/mi6.png
--question " Which genre does this image belong to? "
--candidates " play, tv show, movie " 我們的演示可在此處公開取得。在您的電腦上本地運行我們的演示。跑步:
python demo.py下載訓練資料集並在資料集配置中指定其路徑後,我們就可以開始訓練了。我們在實驗中使用了 8x A6000 Ada。請根據您的GPU資源調整超參數。 Transformer 可能需要大約 2 分鐘來載入模型,請給模型一些時間來開始訓練。這裡我們以訓練 BLIVA Vicuna 版本為例,Flant5 版本遵循相同的格式。
torchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/pretrain_bliva_vicuna.yamltorchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/finetune_bliva_vicuna.yaml或者,我們也支援在第二步驟中使用 LoRA 與 BLIVA 一起訓練 Vicuna7b,預設我們不使用此版本。
torchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/finetune_bliva_and_vicuna.yaml如果您發現 BLIVA 對您的研究和應用有用,請使用此 BibTeX 進行引用:
@misc { hu2023bliva ,
title = { BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions } ,
author = { Wenbo Hu and Yifan Xu and Yi Li and Weiyue Li and Zeyuan Chen and Zhuowen Tu } ,
publisher = { arXiv:2308.09936 } ,
year = { 2023 } ,
}此儲存庫的程式碼遵循 BSD 3-Clause License。許多程式碼基於 Lavis,並具有 BSD 3-Clause License。
對於我們的 BLIVA Vicuna 版本的模型參數,它應該在 LLaMA 的模型許可下使用。對於 BLIVA FlanT5 的模型權重,它採用 Apache 2.0 授權。對於我們的 YTTB-VQA 數據,它位於 CC BY NC 4.0 下


